 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous World Coverage Path Planning for Fixed-Wing UAVs using Deep Reinforcement Learning
May 13, 2025Unmanned Aerial Vehicle (UAV) Coverage Path Planning (CPP) is critical for applications such as precision agriculture and search and rescue. While traditional methods rely on discrete grid-based representations, real-world UAV operations require power-efficient continuous motion planning. We formulate the UAV CPP problem in a continuous environment, minimizing power consumption while ensuring complete coverage. Our approach models the environment with variable-size axis-aligned rectangles and UAV motion with curvature-constrained B\'ezier curves. We train a reinforcement learning agent using an action-mapping-based Soft Actor-Critic (AM-SAC) algorithm employing a self-adaptive curriculum. Experiments on both procedurally generated and hand-crafted scenarios demonstrate the effectiveness of our method in learning energy-efficient coverage strategies.
Action Mapping for Reinforcement Learning in Continuous Environments with Constraints
Dec 05, 2024



Deep reinforcement learning (DRL) has had success across various domains, but applying it to environments with constraints remains challenging due to poor sample efficiency and slow convergence. Recent literature explored incorporating model knowledge to mitigate these problems, particularly through the use of models that assess the feasibility of proposed actions. However, integrating feasibility models efficiently into DRL pipelines in environments with continuous action spaces is non-trivial. We propose a novel DRL training strategy utilizing action mapping that leverages feasibility models to streamline the learning process. By decoupling the learning of feasible actions from policy optimization, action mapping allows DRL agents to focus on selecting the optimal action from a reduced feasible action set. We demonstrate through experiments that action mapping significantly improves training performance in constrained environments with continuous action spaces, especially with imperfect feasibility models.
Equivariant Ensembles and Regularization for Reinforcement Learning in Map-based Path Planning
Mar 19, 2024



In reinforcement learning (RL), exploiting environmental symmetries can significantly enhance efficiency, robustness, and performance. However, ensuring that the deep RL policy and value networks are respectively equivariant and invariant to exploit these symmetries is a substantial challenge. Related works try to design networks that are equivariant and invariant by construction, limiting them to a very restricted library of components, which in turn hampers the expressiveness of the networks. This paper proposes a method to construct equivariant policies and invariant value functions without specialized neural network components, which we term equivariant ensembles. We further add a regularization term for adding inductive bias during training. In a map-based path planning case study, we show how equivariant ensembles and regularization benefit sample efficiency and performance.
Learning to Recharge: UAV Coverage Path Planning through Deep Reinforcement Learning
Sep 07, 2023



Coverage path planning (CPP) is a critical problem in robotics, where the goal is to find an efficient path that covers every point in an area of interest. This work addresses the power-constrained CPP problem with recharge for battery-limited unmanned aerial vehicles (UAVs). In this problem, a notable challenge emerges from integrating recharge journeys into the overall coverage strategy, highlighting the intricate task of making strategic, long-term decisions. We propose a novel proximal policy optimization (PPO)-based deep reinforcement learning (DRL) approach with map-based observations, utilizing action masking and discount factor scheduling to optimize coverage trajectories over the entire mission horizon. We further provide the agent with a position history to handle emergent state loops caused by the recharge capability. Our approach outperforms a baseline heuristic, generalizes to different target zones and maps, with limited generalization to unseen maps. We offer valuable insights into DRL algorithm design for long-horizon problems and provide a publicly available software framework for the CPP problem.
Learning to Generate All Feasible Actions
Jan 26, 2023



Several machine learning (ML) applications are characterized by searching for an optimal solution to a complex task. The search space for this optimal solution is often very large, so large in fact that this optimal solution is often not computable. Part of the problem is that many candidate solutions found via ML are actually infeasible and have to be discarded. Restricting the search space to only the feasible solution candidates simplifies finding an optimal solution for the tasks. Further, the set of feasible solutions could be re-used in multiple problems characterized by different tasks. In particular, we observe that complex tasks can be decomposed into subtasks and corresponding skills. We propose to learn a reusable and transferable skill by training an actor to generate all feasible actions. The trained actor can then propose feasible actions, among which an optimal one can be chosen according to a specific task. The actor is trained by interpreting the feasibility of each action as a target distribution. The training procedure minimizes a divergence of the actor's output distribution to this target. We derive the general optimization target for arbitrary f-divergences using a combination of kernel density estimates, resampling, and importance sampling. We further utilize an auxiliary critic to reduce the interactions with the environment. A preliminary comparison to related strategies shows that our approach learns to visit all the modes in the feasible action space, demonstrating the framework's potential for learning skills that can be used in various downstream tasks.
Emotional Semantics-Preserved and Feature-Aligned CycleGAN for Visual Emotion Adaptation
Nov 25, 2020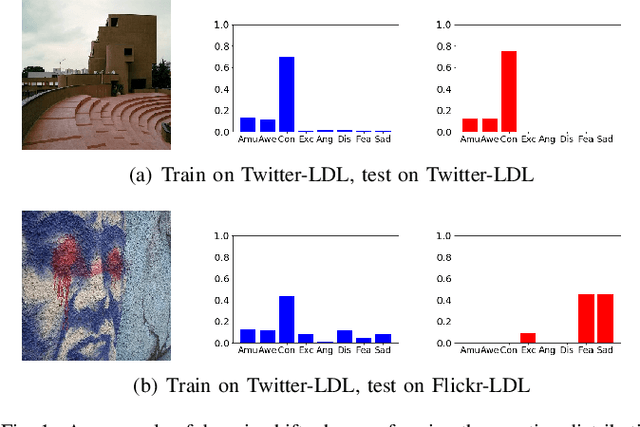

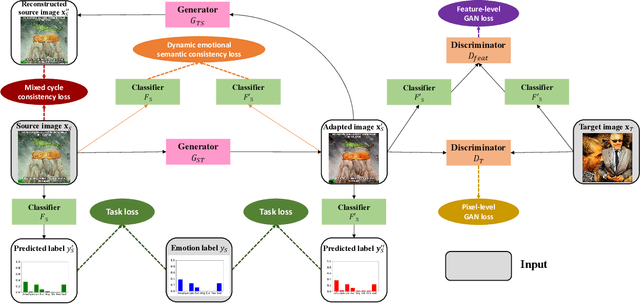
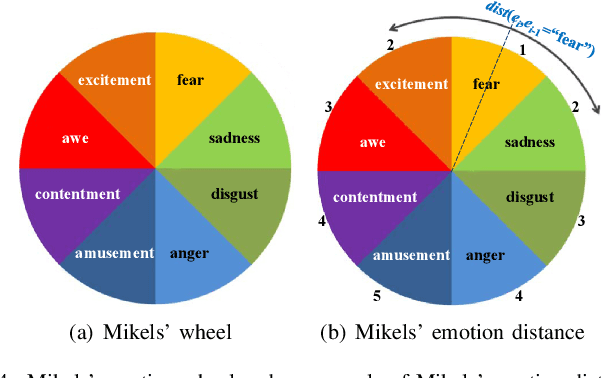
Thanks to large-scale labeled training data, deep neural networks (DNNs) have obtained remarkable success in many vision and multimedia tasks. However, because of the presence of domain shift, the learned knowledge of the well-trained DNNs cannot be well generalized to new domains or datasets that have few labels. Unsupervised domain adaptation (UDA) studies the problem of transferring models trained on one labeled source domain to another unlabeled target domain. In this paper, we focus on UDA in visual emotion analysis for both emotion distribution learning and dominant emotion classification. Specifically, we design a novel end-to-end cycle-consistent adversarial model, termed CycleEmotionGAN++. First, we generate an adapted domain to align the source and target domains on the pixel-level by improving CycleGAN with a multi-scale structured cycle-consistency loss. During the image translation, we propose a dynamic emotional semantic consistency loss to preserve the emotion labels of the source images. Second, we train a transferable task classifier on the adapted domain with feature-level alignment between the adapted and target domains. We conduct extensive UDA experiments on the Flickr-LDL & Twitter-LDL datasets for distribution learning and ArtPhoto & FI datasets for emotion classification. The results demonstrate the significant improvements yielded by the proposed CycleEmotionGAN++ as compared to state-of-the-art UDA approaches.
Scenic: A Language for Scenario Specification and Data Generation
Oct 13, 2020
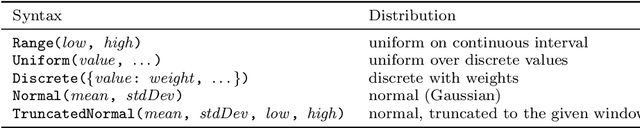
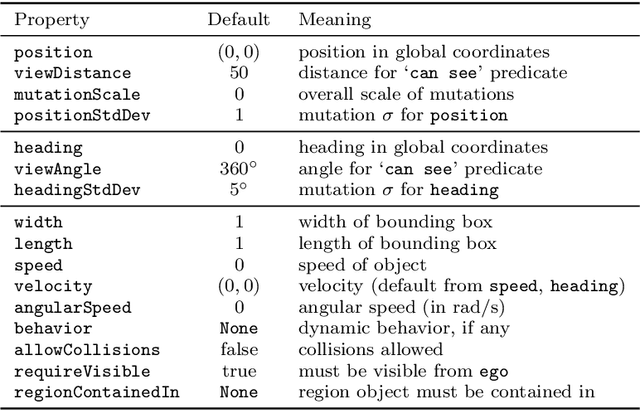
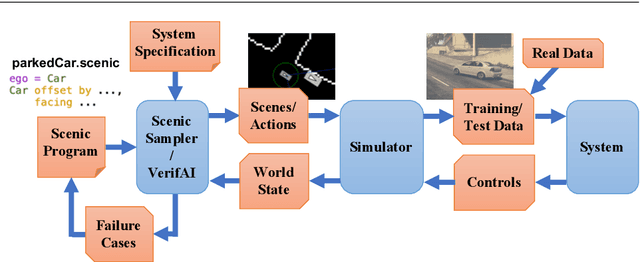
We propose a new probabilistic programming language for the design and analysis of cyber-physical systems, especially those based on machine learning. Specifically, we consider the problems of training a system to be robust to rare events, testing its performance under different conditions, and debugging failures. We show how a probabilistic programming language can help address these problems by specifying distributions encoding interesting types of inputs, then sampling these to generate specialized training and test data. More generally, such languages can be used to write environment models, an essential prerequisite to any formal analysis. In this paper, we focus on systems like autonomous cars and robots, whose environment at any point in time is a 'scene', a configuration of physical objects and agents. We design a domain-specific language, Scenic, for describing scenarios that are distributions over scenes and the behaviors of their agents over time. As a probabilistic programming language, Scenic allows assigning distributions to features of the scene, as well as declaratively imposing hard and soft constraints over the scene. We develop specialized techniques for sampling from the resulting distribution, taking advantage of the structure provided by Scenic's domain-specific syntax. Finally, we apply Scenic in a case study on a convolutional neural network designed to detect cars in road images, improving its performance beyond that achieved by state-of-the-art synthetic data generation methods.
A Review of Single-Source Deep Unsupervised Visual Domain Adaptation
Sep 19, 2020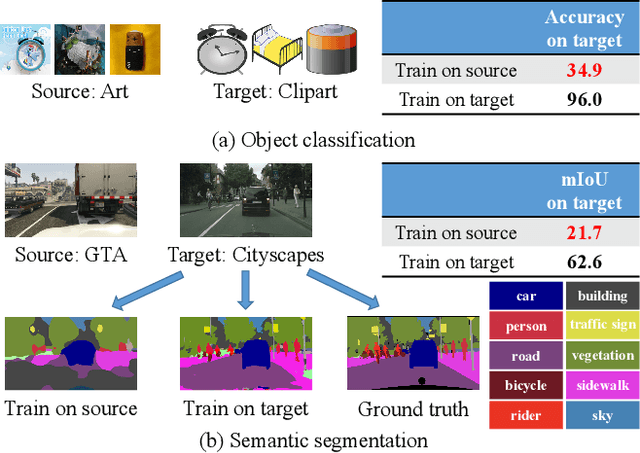
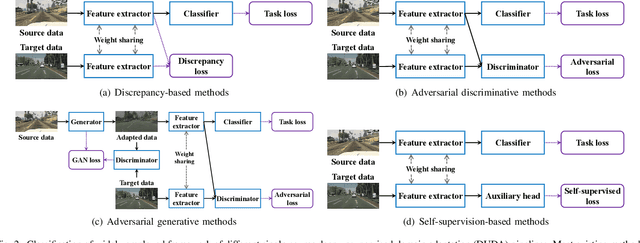

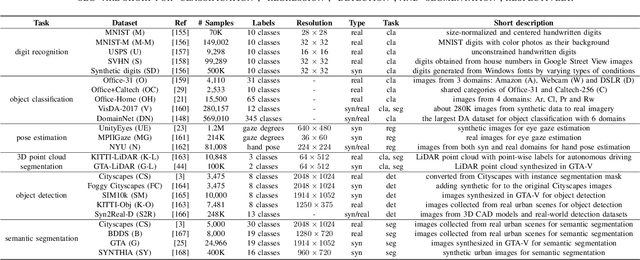
Large-scale labeled training datasets have enabled deep neural networks to excel across a wide range of benchmark vision tasks. However, in many applications, it is prohibitively expensive and time-consuming to obtain large quantities of labeled data. To cope with limited labeled training data, many have attempted to directly apply models trained on a large-scale labeled source domain to another sparsely labeled or unlabeled target domain. Unfortunately, direct transfer across domains often performs poorly due to the presence of domain shift or dataset bias. Domain adaptation is a machine learning paradigm that aims to learn a model from a source domain that can perform well on a different (but related) target domain. In this paper, we review the latest single-source deep unsupervised domain adaptation methods focused on visual tasks and discuss new perspectives for future research. We begin with the definitions of different domain adaptation strategies and the descriptions of existing benchmark datasets. We then summarize and compare different categories of single-source unsupervised domain adaptation methods, including discrepancy-based methods, adversarial discriminative methods, adversarial generative methods, and self-supervision-based methods. Finally, we discuss future research directions with challenges and possible solutions.
Scenic: Language-Based Scene Generation
Sep 25, 2018
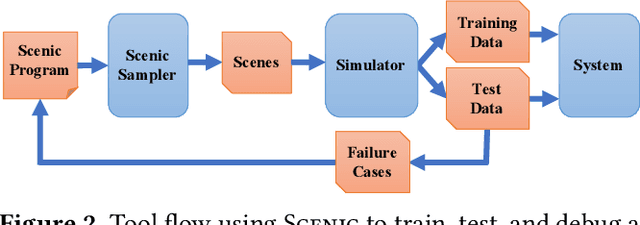
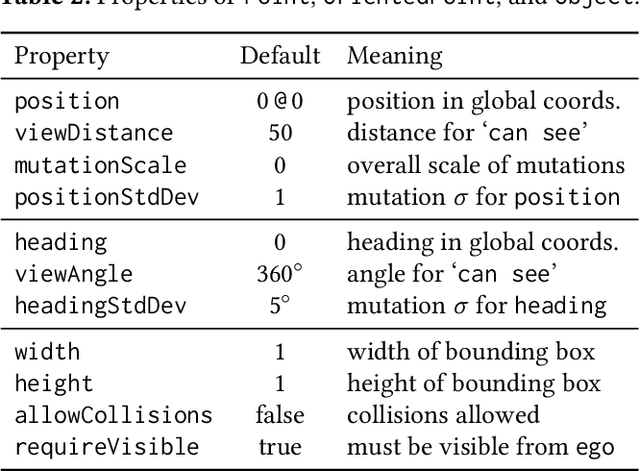

Synthetic data has proved increasingly useful in both training and testing machine learning models such as neural networks. The major problem in synthetic data generation is producing meaningful data that is not simply random but reflects properties of real-world data or covers particular cases of interest. In this paper, we show how a probabilistic programming language can be used to guide data synthesis by encoding domain knowledge about what data is useful. Specifically, we focus on data sets arising from "scenes", configurations of physical objects; for example, images of cars on a road. We design a domain-specific language, Scenic, for describing "scenarios" that are distributions over scenes. The syntax of Scenic makes it easy to specify complex relationships between the positions and orientations of objects. As a probabilistic programming language, Scenic allows assigning distributions to features of the scene, as well as declaratively imposing hard and soft constraints over the scene. A Scenic scenario thereby implicitly defines a distribution over scenes, and we formulate the problem of sampling from this distribution as "scene improvisation". We implement an improviser for Scenic scenarios and apply it in a case study generating synthetic data sets for a convolutional neural network designed to detect cars in road images. Our experiments demonstrate the usefulness of our approach by using Scenic to analyze and improve the performance of the network in various scenarios.
A LiDAR Point Cloud Generator: from a Virtual World to Autonomous Driving
Mar 31, 2018
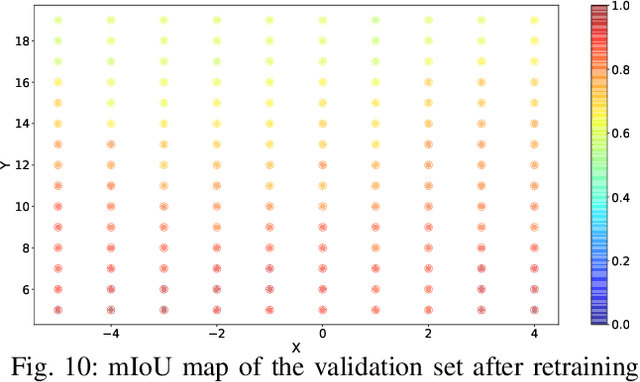
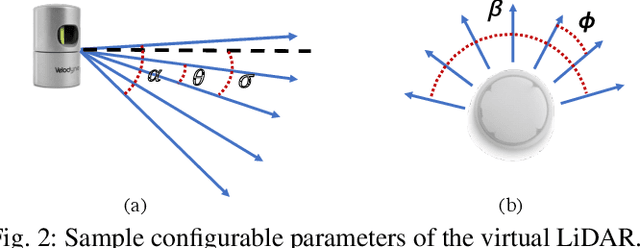
3D LiDAR scanners are playing an increasingly important role in autonomous driving as they can generate depth information of the environment. However, creating large 3D LiDAR point cloud datasets with point-level labels requires a significant amount of manual annotation. This jeopardizes the efficient development of supervised deep learning algorithms which are often data-hungry. We present a framework to rapidly create point clouds with accurate point-level labels from a computer game. The framework supports data collection from both auto-driving scenes and user-configured scenes. Point clouds from auto-driving scenes can be used as training data for deep learning algorithms, while point clouds from user-configured scenes can be used to systematically test the vulnerability of a neural network, and use the falsifying examples to make the neural network more robust through retraining. In addition, the scene images can be captured simultaneously in order for sensor fusion tasks, with a method proposed to do automatic calibration between the point clouds and captured scene images. We show a significant improvement in accuracy (+9%) in point cloud segmentation by augmenting the training dataset with the generated synthesized data. Our experiments also show by testing and retraining the network using point clouds from user-configured scenes, the weakness/blind spots of the neural network can be fixed.