 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Recharge: UAV Coverage Path Planning through Deep Reinforcement Learning
Sep 07, 2023



Coverage path planning (CPP) is a critical problem in robotics, where the goal is to find an efficient path that covers every point in an area of interest. This work addresses the power-constrained CPP problem with recharge for battery-limited unmanned aerial vehicles (UAVs). In this problem, a notable challenge emerges from integrating recharge journeys into the overall coverage strategy, highlighting the intricate task of making strategic, long-term decisions. We propose a novel proximal policy optimization (PPO)-based deep reinforcement learning (DRL) approach with map-based observations, utilizing action masking and discount factor scheduling to optimize coverage trajectories over the entire mission horizon. We further provide the agent with a position history to handle emergent state loops caused by the recharge capability. Our approach outperforms a baseline heuristic, generalizes to different target zones and maps, with limited generalization to unseen maps. We offer valuable insights into DRL algorithm design for long-horizon problems and provide a publicly available software framework for the CPP problem.
Model-aided Federated Reinforcement Learning for Multi-UAV Trajectory Planning in IoT Networks
Jun 03, 2023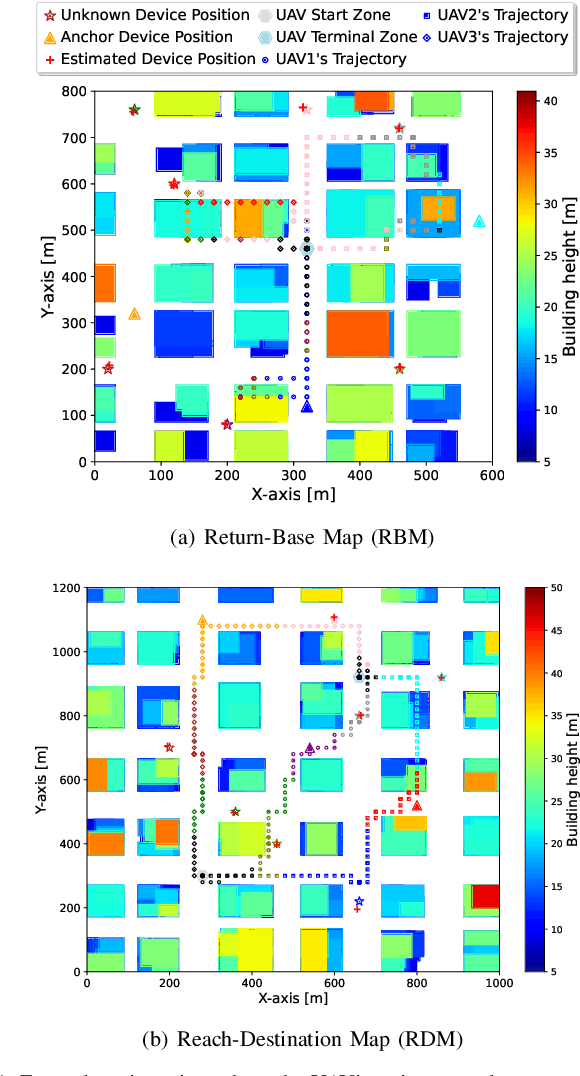
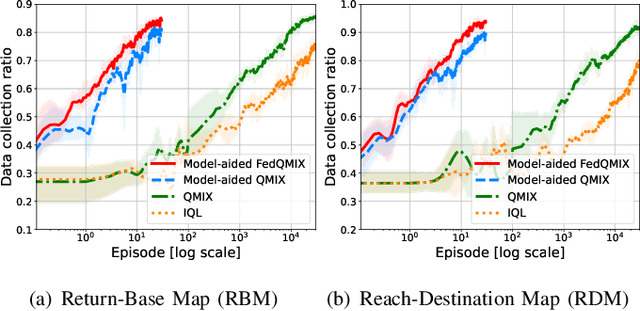
Deploying teams of cooperative unmanned aerial vehicles (UAVs) to harvest data from distributed Internet of Things (IoT) devices requires efficient trajectory planning and coordination algorithms. Multi-agent reinforcement learning (MARL) has emerged as an effective solution, but often requires extensive and costly real-world training data. In this paper, we propose a novel model-aided federated MARL algorithm to coordinate multiple UAVs on a data harvesting mission with limited knowledge about the environment, significantly reducing the real-world training data demand. The proposed algorithm alternates between learning an environment model from real-world measurements and federated QMIX training in the simulated environment. Specifically, collected measurements from the real-world environment are used to learn the radio channel and estimate unknown IoT device locations to create a simulated environment. Each UAV agent trains a local QMIX model in its simulated environment and continuously consolidates it through federated learning with other agents, accelerating the learning process and further improving training sample efficiency. Simulation results demonstrate that our proposed model-aided FedQMIX algorithm substantially reduces the need for real-world training experiences while attaining similar data collection performance as standard MARL algorithms.
Modeling Interactions of Autonomous Vehicles and Pedestrians with Deep Multi-Agent Reinforcement Learning for Collision Avoidance
Sep 30, 2021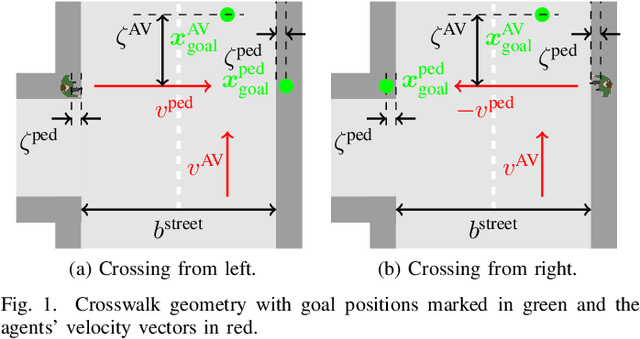

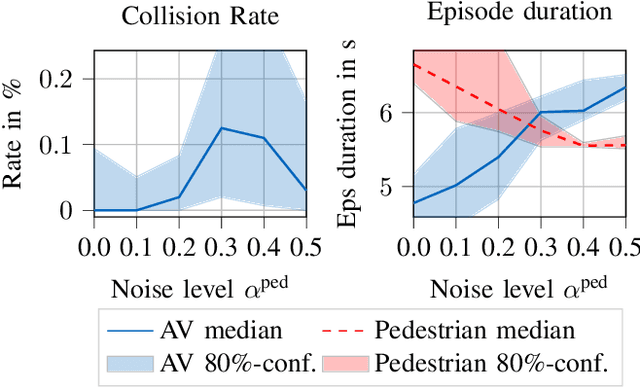
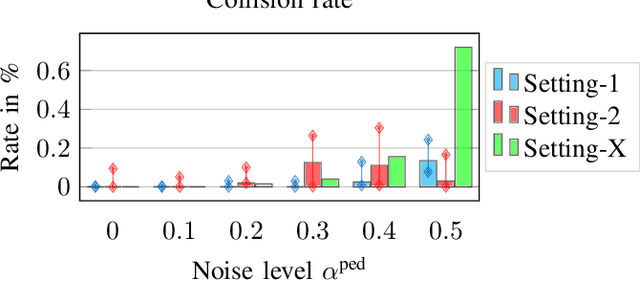
Reliable pedestrian crash avoidance mitigation (PCAM) systems are crucial components of safe autonomous vehicles (AVs). The sequential nature of the vehicle-pedestrian interaction, i.e., where immediate decisions of one agent directly influence the following decisions of the other agent, is an often neglected but important aspect. In this work, we model the corresponding interaction sequence as a Markov decision process (MDP) that is solved by deep reinforcement learning (DRL) algorithms to define the PCAM system's policy. The simulated driving scenario is based on an AV acting as a DRL agent driving along an urban street, facing a pedestrian at an unmarked crosswalk who tries to cross. Since modeling realistic crossing behavior of the pedestrian is challenging, we introduce two levels of intelligent pedestrian behavior: While the baseline model follows a predefined strategy, our advanced model captures continuous learning and the inherent uncertainty in human behavior by defining the pedestrian as a second DRL agent, i.e., we introduce a deep multi-agent reinforcement learning (DMARL) problem. The presented PCAM system with different levels of intelligent pedestrian behavior is benchmarked according to the agents' collision rate and the resulting traffic flow efficiency. In this analysis, our focus lies on evaluating the influence of observation noise on the decision making of the agents. The results show that the AV is able to completely mitigate collisions under the majority of the investigated conditions and that the DRL-based pedestrian model indeed learns a more human-like crossing behavior.
Model-aided Deep Reinforcement Learning for Sample-efficient UAV Trajectory Design in IoT Networks
May 03, 2021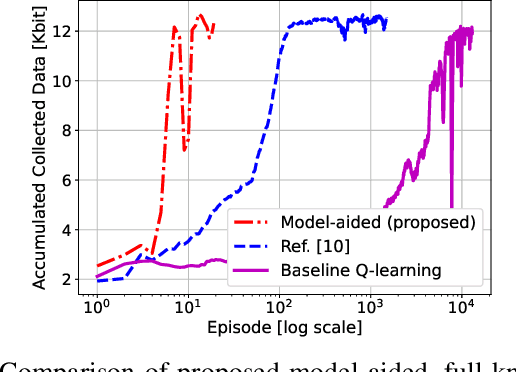
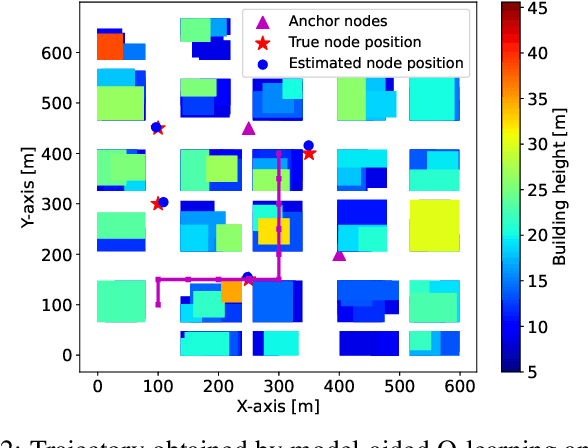
Deep Reinforcement Learning (DRL) is gaining attention as a potential approach to design trajectories for autonomous unmanned aerial vehicles (UAV) used as flying access points in the context of cellular or Internet of Things (IoT) connectivity. DRL solutions offer the advantage of on-the-go learning hence relying on very little prior contextual information. A corresponding drawback however lies in the need for many learning episodes which severely restricts the applicability of such approach in real-world time- and energy-constrained missions. Here, we propose a model-aided deep Q-learning approach that, in contrast to previous work, considerably reduces the need for extensive training data samples, while still achieving the overarching goal of DRL, i.e to guide a battery-limited UAV towards an efficient data harvesting trajectory, without prior knowledge of wireless channel characteristics and limited knowledge of wireless node locations. The key idea consists in using a small subset of nodes as anchors (i.e. with known location) and learning a model of the propagation environment while implicitly estimating the positions of regular nodes. Interaction with the model allows us to train a deep Q-network (DQN) to approximate the optimal UAV control policy. We show that in comparison with standard DRL approaches, the proposed model-aided approach requires at least one order of magnitude less training data samples to reach identical data collection performance, hence offering a first step towards making DRL a viable solution to the problem.
UAV Path Planning using Global and Local Map Information with Deep Reinforcement Learning
Nov 02, 2020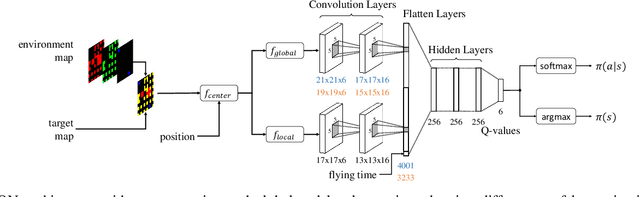
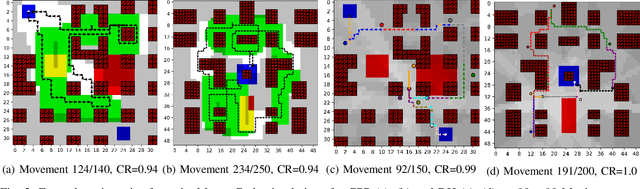
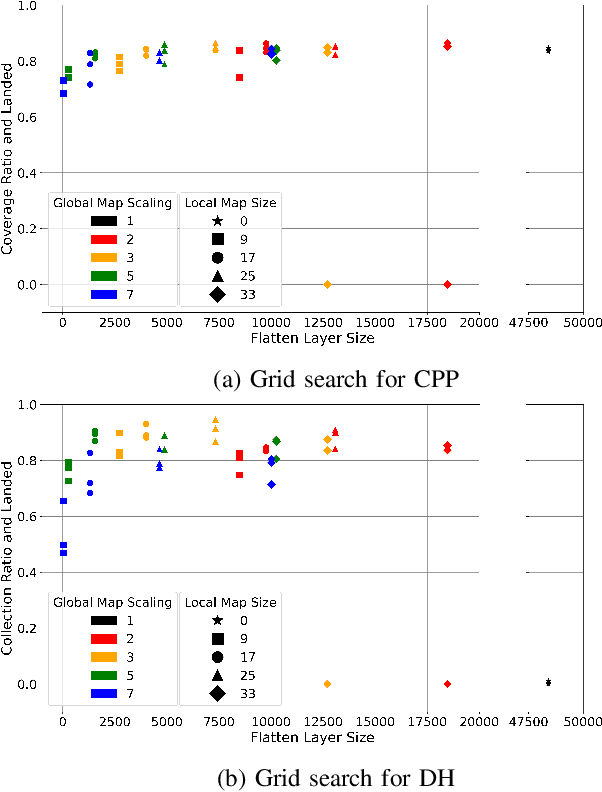
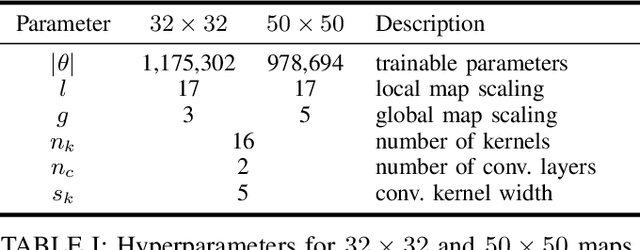
Path planning methods for autonomous unmanned aerial vehicles (UAVs) are typically designed for one specific type of mission. In this work, we present a method for autonomous UAV path planning based on deep reinforcement learning (DRL) that can be applied to a wide range of mission scenarios. Specifically, we compare coverage path planning (CPP), where the UAV's goal is to survey an area of interest to data harvesting (DH), where the UAV collects data from distributed Internet of Things (IoT) sensor devices. By exploiting structured map information of the environment, we train double deep Q-networks (DDQNs) with identical architectures on both distinctly different mission scenarios, to make movement decisions that balance the respective mission goal with navigation constraints. By introducing a novel approach exploiting a compressed global map of the environment combined with a cropped but uncompressed local map showing the vicinity of the UAV agent, we demonstrate that the proposed method can efficiently scale to large environments. We also extend previous results for generalizing control policies that require no retraining when scenario parameters change and offer a detailed analysis of crucial map processing parameters' effects on path planning performance.
Multi-UAV Path Planning for Wireless Data Harvesting with Deep Reinforcement Learning
Oct 23, 2020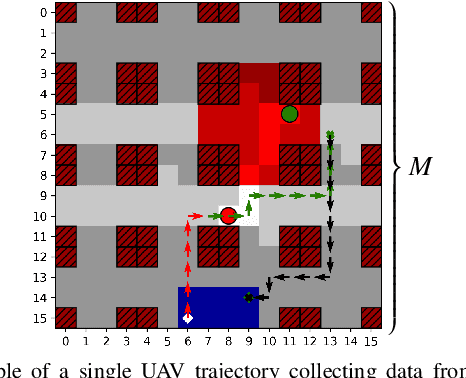
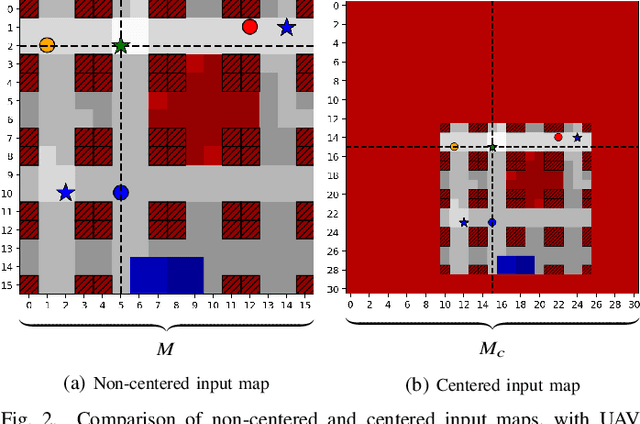
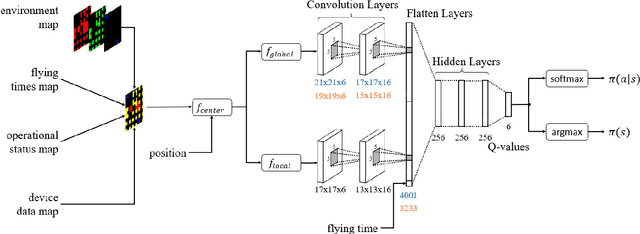
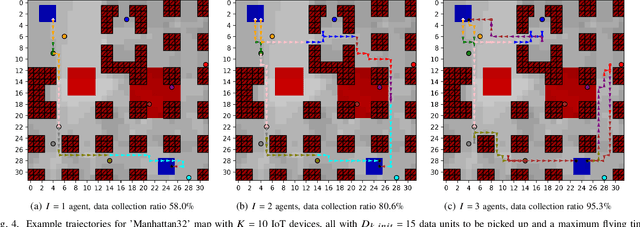
Harvesting data from distributed Internet of Things (IoT) devices with multiple autonomous unmanned aerial vehicles (UAVs) is a challenging problem requiring flexible path planning methods. We propose a multi-agent reinforcement learning (MARL) approach that, in contrast to previous work, can adapt to profound changes in the scenario parameters defining the data harvesting mission, such as the number of deployed UAVs, number and position of IoT devices, or the maximum flying time, without the need to perform expensive recomputations or relearn control policies. We formulate the path planning problem for a cooperative, non-communicating, and homogeneous team of UAVs tasked with maximizing collected data from distributed IoT sensor nodes subject to flying time and collision avoidance constraints. The path planning problem is translated into a decentralized partially observable Markov decision process (Dec-POMDP), which we solve by training a double deep Q-network (DDQN) to approximate the optimal UAV control policy. By exploiting global-local maps of the environment that are fed into convolutional layers of the agents, we show that our proposed network architecture enables the agents to cooperate effectively by carefully dividing the data collection task among themselves, adapt to large state spaces, and make movement decisions that balance data collection goals, flight-time efficiency, and navigation constraints.
UAV Path Planning for Wireless Data Harvesting: A Deep Reinforcement Learning Approach
Jul 01, 2020


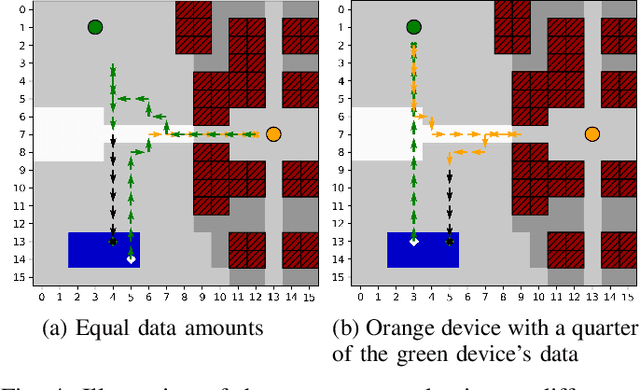
Autonomous deployment of unmanned aerial vehicles (UAVs) supporting next-generation communication networks requires efficient trajectory planning methods. We propose a new end-to-end reinforcement learning (RL) approach to UAV-enabled data collection from Internet of Things (IoT) devices in an urban environment. An autonomous drone is tasked with gathering data from distributed sensor nodes subject to limited flying time and obstacle avoidance. While previous approaches, learning and non-learning based, must perform expensive recomputations or relearn a behavior when important scenario parameters such as the number of sensors, sensor positions, or maximum flying time, change, we train a double deep Q-network (DDQN) with combined experience replay to learn a UAV control policy that generalizes over changing scenario parameters. By exploiting a multi-layer map of the environment fed through convolutional network layers to the agent, we show that our proposed network architecture enables the agent to make movement decisions for a variety of scenario parameters that balance the data collection goal with flight time efficiency and safety constraints. Considerable advantages in learning efficiency from using a map centered on the UAV's position over a non-centered map are also illustrated.
UAV Coverage Path Planning under Varying Power Constraints using Deep Reinforcement Learning
Mar 05, 2020



Coverage path planning (CPP) is the task of designing a trajectory that enables a mobile agent to travel over every point of an area of interest. We propose a new method to control an unmanned aerial vehicle (UAV) carrying a camera on a CPP mission with random start positions and multiple options for landing positions in an environment containing no-fly zones. While numerous approaches have been proposed to solve similar CPP problems, we leverage end-to-end reinforcement learning (RL) to learn a control policy that generalizes over varying power constraints for the UAV. Despite recent improvements in battery technology, the maximum flying range of small UAVs is still a severe constraint, which is exacerbated by variations in the UAV's power consumption that are hard to predict. By using map-like input channels to feed spatial information through convolutional network layers to the agent, we are able to train a double deep Q-network (DDQN) to make control decisions for the UAV, balancing limited power budget and coverage goal. The proposed method can be applied to a wide variety of environments and harmonizes complex goal structures with system constraints.