 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Real-World Autonomous Racing via Attenuated Residual Policy Optimization
Mar 13, 2026Residual policy learning (RPL), in which a learned policy refines a static base policy using deep reinforcement learning (DRL), has shown strong performance across various robotic applications. Its effectiveness is particularly evident in autonomous racing, a domain that serves as a challenging benchmark for real-world DRL. However, deploying RPL-based controllers introduces system complexity and increases inference latency. We address this by introducing an extension of RPL named attenuated residual policy optimization ($α$-RPO). Unlike standard RPL, $α$-RPO yields a standalone neural policy by progressively attenuating the base policy, which initially serves to bootstrap learning. Furthermore, this mechanism enables a form of privileged learning, where the base policy is permitted to use sensor modalities not required for final deployment. We design $α$-RPO to integrate seamlessly with PPO, ensuring that the attenuated influence of the base controller is dynamically compensated during policy optimization. We evaluate $α$-RPO by building a framework for 1:10-scaled autonomous racing around it. In both simulation and zero-shot real-world transfer to Roboracer cars, $α$-RPO not only reduces system complexity but also improves driving performance compared to baselines - demonstrating its practicality for robotic deployment. Our code is available at: https://github.com/raphajaner/arpo_racing.
Impoola: The Power of Average Pooling for Image-Based Deep Reinforcement Learning
Mar 07, 2025



As image-based deep reinforcement learning tackles more challenging tasks, increasing model size has become an important factor in improving performance. Recent studies achieved this by focusing on the parameter efficiency of scaled networks, typically using Impala-CNN, a 15-layer ResNet-inspired network, as the image encoder. However, while Impala-CNN evidently outperforms older CNN architectures, potential advancements in network design for deep reinforcement learning-specific image encoders remain largely unexplored. We find that replacing the flattening of output feature maps in Impala-CNN with global average pooling leads to a notable performance improvement. This approach outperforms larger and more complex models in the Procgen Benchmark, particularly in terms of generalization. We call our proposed encoder model Impoola-CNN. A decrease in the network's translation sensitivity may be central to this improvement, as we observe the most significant gains in games without agent-centered observations. Our results demonstrate that network scaling is not just about increasing model size - efficient network design is also an essential factor.
Action Mapping for Reinforcement Learning in Continuous Environments with Constraints
Dec 05, 2024



Deep reinforcement learning (DRL) has had success across various domains, but applying it to environments with constraints remains challenging due to poor sample efficiency and slow convergence. Recent literature explored incorporating model knowledge to mitigate these problems, particularly through the use of models that assess the feasibility of proposed actions. However, integrating feasibility models efficiently into DRL pipelines in environments with continuous action spaces is non-trivial. We propose a novel DRL training strategy utilizing action mapping that leverages feasibility models to streamline the learning process. By decoupling the learning of feasible actions from policy optimization, action mapping allows DRL agents to focus on selecting the optimal action from a reduced feasible action set. We demonstrate through experiments that action mapping significantly improves training performance in constrained environments with continuous action spaces, especially with imperfect feasibility models.
RaceMOP: Mapless Online Path Planning for Multi-Agent Autonomous Racing using Residual Policy Learning
Mar 11, 2024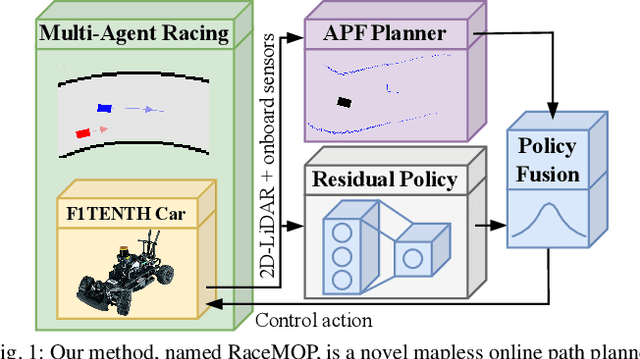
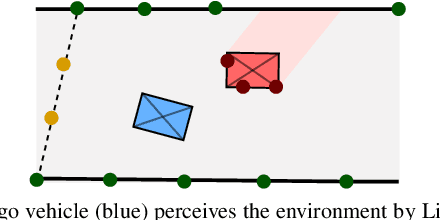
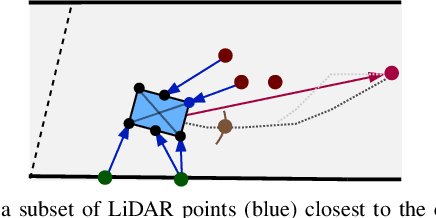
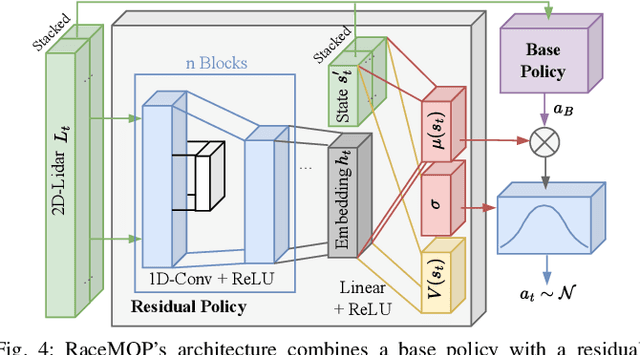
The interactive decision-making in multi-agent autonomous racing offers insights valuable beyond the domain of self-driving cars. Mapless online path planning is particularly of practical appeal but poses a challenge for safely overtaking opponents due to the limited planning horizon. Accordingly, this paper introduces RaceMOP, a novel method for mapless online path planning designed for multi-agent racing of F1TENTH cars. Unlike classical planners that depend on predefined racing lines, RaceMOP operates without a map, relying solely on local observations to overtake other race cars at high speed. Our approach combines an artificial potential field method as a base policy with residual policy learning to introduce long-horizon planning capabilities. We advance the field by introducing a novel approach for policy fusion with the residual policy directly in probability space. Our experiments for twelve simulated racetracks validate that RaceMOP is capable of long-horizon decision-making with robust collision avoidance during overtaking maneuvers. RaceMOP demonstrates superior handling over existing mapless planners while generalizing to unknown racetracks, paving the way for further use of our method in robotics. We make the open-source code for RaceMOP available at http://github.com/raphajaner/racemop.
Unifying F1TENTH Autonomous Racing: Survey, Methods and Benchmarks
Feb 28, 2024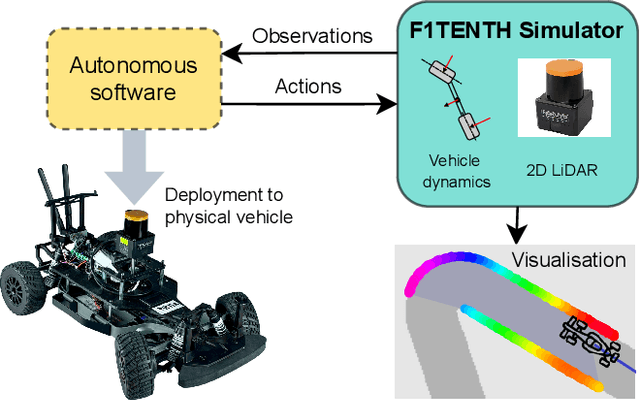
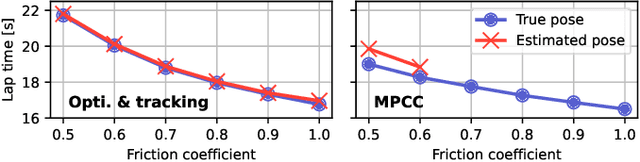
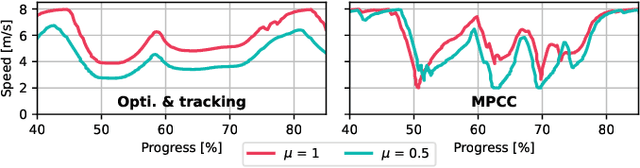
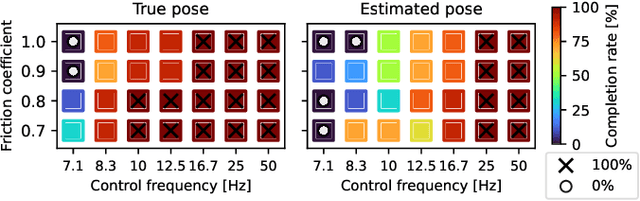
The F1TENTH autonomous racing platform, consisting of 1:10 scale RC cars, has evolved into a leading research platform. The many publications and real-world competitions span many domains, from classical path planning to novel learning-based algorithms. Consequently, the field is wide and disjointed, hindering direct comparison of methods and making it difficult to assess the state-of-the-art. Therefore, we aim to unify the field by surveying current approaches, describing common methods and providing benchmark results to facilitate clear comparison and establish a baseline for future work. We survey current work in F1TENTH racing in the classical and learning categories, explaining the different solution approaches. We describe particle filter localisation, trajectory optimisation and tracking, model predictive contouring control (MPCC), follow-the-gap and end-to-end reinforcement learning. We provide an open-source evaluation of benchmark methods and investigate overlooked factors of control frequency and localisation accuracy for classical methods and reward signal and training map for learning methods. The evaluation shows that the optimisation and tracking method achieves the fastest lap times, followed by the MPCC planner. Finally, our work identifies and outlines the relevant research aspects to help motivate future work in the F1TENTH domain.
Efficient Learning of Urban Driving Policies Using Bird's-Eye-View State Representations
May 31, 2023



Autonomous driving involves complex decision-making in highly interactive environments, requiring thoughtful negotiation with other traffic participants. While reinforcement learning provides a way to learn such interaction behavior, efficient learning critically depends on scalable state representations. Contrary to imitation learning methods, high-dimensional state representations still constitute a major bottleneck for deep reinforcement learning methods in autonomous driving. In this paper, we study the challenges of constructing bird's-eye-view representations for autonomous driving and propose a recurrent learning architecture for long-horizon driving. Our PPO-based approach, called RecurrDriveNet, is demonstrated on a simulated autonomous driving task in CARLA, where it outperforms traditional frame-stacking methods while only requiring one million experiences for training. RecurrDriveNet causes less than one infraction per driven kilometer by interacting safely with other road users.
Residual Policy Learning for Vehicle Control of Autonomous Racing Cars
Feb 14, 2023The development of vehicle controllers for autonomous racing is challenging because racing cars operate at their physical driving limit. Prompted by the demand for improved performance, autonomous racing research has seen the proliferation of machine learning-based controllers. While these approaches show competitive performance, their practical applicability is often limited. Residual policy learning promises to mitigate this by combining classical controllers with learned residual controllers. The critical advantage of residual controllers is their high adaptability parallel to the classical controller's stable behavior. We propose a residual vehicle controller for autonomous racing cars that learns to amend a classical controller for the path-following of racing lines. In an extensive study, performance gains of our approach are evaluated for a simulated car of the F1TENTH autonomous racing series. The evaluation for twelve replicated real-world racetracks shows that the residual controller reduces lap times by an average of 4.55 % compared to a classical controller and zero-shot generalizes to new racetracks.
Learning to Generate All Feasible Actions
Jan 26, 2023



Several machine learning (ML) applications are characterized by searching for an optimal solution to a complex task. The search space for this optimal solution is often very large, so large in fact that this optimal solution is often not computable. Part of the problem is that many candidate solutions found via ML are actually infeasible and have to be discarded. Restricting the search space to only the feasible solution candidates simplifies finding an optimal solution for the tasks. Further, the set of feasible solutions could be re-used in multiple problems characterized by different tasks. In particular, we observe that complex tasks can be decomposed into subtasks and corresponding skills. We propose to learn a reusable and transferable skill by training an actor to generate all feasible actions. The trained actor can then propose feasible actions, among which an optimal one can be chosen according to a specific task. The actor is trained by interpreting the feasibility of each action as a target distribution. The training procedure minimizes a divergence of the actor's output distribution to this target. We derive the general optimization target for arbitrary f-divergences using a combination of kernel density estimates, resampling, and importance sampling. We further utilize an auxiliary critic to reduce the interactions with the environment. A preliminary comparison to related strategies shows that our approach learns to visit all the modes in the feasible action space, demonstrating the framework's potential for learning skills that can be used in various downstream tasks.
Modeling Interactions of Autonomous Vehicles and Pedestrians with Deep Multi-Agent Reinforcement Learning for Collision Avoidance
Sep 30, 2021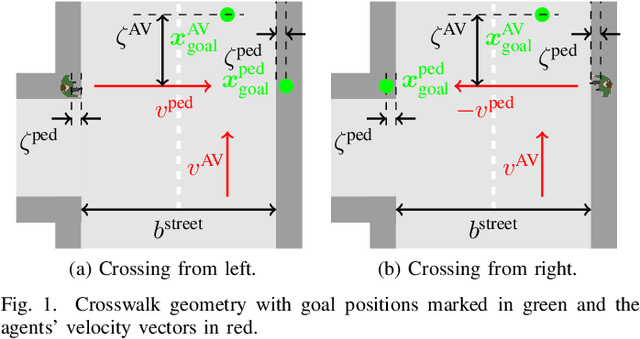

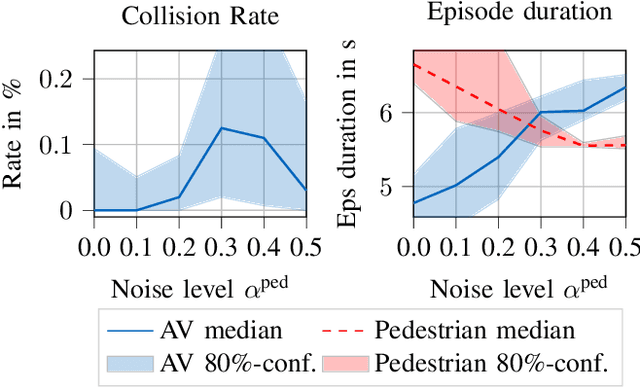
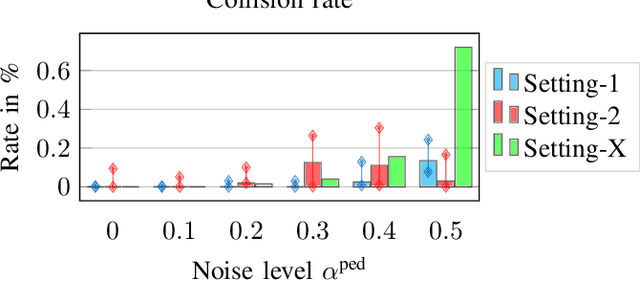
Reliable pedestrian crash avoidance mitigation (PCAM) systems are crucial components of safe autonomous vehicles (AVs). The sequential nature of the vehicle-pedestrian interaction, i.e., where immediate decisions of one agent directly influence the following decisions of the other agent, is an often neglected but important aspect. In this work, we model the corresponding interaction sequence as a Markov decision process (MDP) that is solved by deep reinforcement learning (DRL) algorithms to define the PCAM system's policy. The simulated driving scenario is based on an AV acting as a DRL agent driving along an urban street, facing a pedestrian at an unmarked crosswalk who tries to cross. Since modeling realistic crossing behavior of the pedestrian is challenging, we introduce two levels of intelligent pedestrian behavior: While the baseline model follows a predefined strategy, our advanced model captures continuous learning and the inherent uncertainty in human behavior by defining the pedestrian as a second DRL agent, i.e., we introduce a deep multi-agent reinforcement learning (DMARL) problem. The presented PCAM system with different levels of intelligent pedestrian behavior is benchmarked according to the agents' collision rate and the resulting traffic flow efficiency. In this analysis, our focus lies on evaluating the influence of observation noise on the decision making of the agents. The results show that the AV is able to completely mitigate collisions under the majority of the investigated conditions and that the DRL-based pedestrian model indeed learns a more human-like crossing behavior.