 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoViF 2026 The First Challenge on Holistic Quality Assessment for 4D World Model (PhyScore)
May 06, 2026This paper reports on the LoViF 2026 PhyScore challenge, a competition on holistic quality assessment of world-model-generated videos across both 2D and 4D generation settings. The challenge is motivated by a central gap in current evaluation practice: perceptual quality alone is insufficient to judge whether generated dynamics are physically plausible, temporally coherent, and consistent with input conditions. Participants are required to build a metric that jointly predicts four dimensions, i.e., Video Quality, Physical Realism, Condition-Video Alignment, and Temporal Consistency. Depart from that, participants also need to localize physical anomaly timestamps for fine-grained diagnosis. The benchmark dataset contains 1,554 videos generated by seven representative world generative models, organized into three tracks (text-2D, image-to-4D, and video-to-4D) and spanning 26 categories. These categories explicitly cover physics-relevant scenarios, including dynamics, optics, and thermodynamics, together with diverse real-world and creative content. To ensure label reliability, scores and anomaly timestamps are produced through trained human annotation with an additional automated quality-control pass. Evaluation is based on both score prediction and anomaly localization, with a composite protocol that combines TimeStamp_IOU and SRCC/PLCC. This report summarizes the challenge design and provides method-level insights from submitted solutions.
NTIRE 2026 3D Restoration and Reconstruction in Real-world Adverse Conditions: RealX3D Challenge Results
Apr 05, 2026This paper presents a comprehensive review of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge, detailing the proposed methods and results. The challenge seeks to identify robust reconstruction pipelines that are robust under real-world adverse conditions, specifically extreme low-light and smoke-degraded environments, as captured by our RealX3D benchmark. A total of 279 participants registered for the competition, of whom 33 teams submitted valid results. We thoroughly evaluate the submitted approaches against state-of-the-art baselines, revealing significant progress in 3D reconstruction under adverse conditions. Our analysis highlights shared design principles among top-performing methods and provides insights into effective strategies for handling 3D scene degradation.
Causal Scene Narration with Runtime Safety Supervision for Vision-Language-Action Driving
Apr 02, 2026Vision-Language-Action (VLA) models for autonomous driving must integrate diverse textual inputs, including navigation commands, hazard warnings, and traffic state descriptions, yet current systems often present these as disconnected fragments, forcing the model to discover on its own which environmental constraints are relevant to the current maneuver. We introduce Causal Scene Narration (CSN), which restructures VLA text inputs through intent-constraint alignment, quantitative grounding, and structured separation, at inference time with zero GPU cost. We complement CSN with Simplex-based runtime safety supervision and training-time alignment via Plackett-Luce DPO with negative log-likelihood (NLL) regularization. A multi-town closed-loop CARLA evaluation shows that CSN improves Driving Score by +31.1% on original LMDrive and +24.5% on the preference-aligned variant. A controlled ablation reveals that causal structure accounts for 39.1% of this gain, with the remainder attributable to information content alone. A perception noise ablation confirms that CSN's benefit is robust to realistic sensing errors. Semantic safety supervision improves Infraction Score, while reactive Time-To-Collision monitoring degrades performance, demonstrating that intent-aware monitoring is needed for VLA systems.
An Open-Source Modular Benchmark for Diffusion-Based Motion Planning in Closed-Loop Autonomous Driving
Mar 01, 2026Diffusion-based motion planners have achieved state-of-the-art results on benchmarks such as nuPlan, yet their evaluation within closed-loop production autonomous driving stacks remains largely unexplored. Existing evaluations abstract away ROS 2 communication latency and real-time scheduling constraints, while monolithic ONNX deployment freezes all solver parameters at export time. We present an open-source modular benchmark that addresses both gaps: using ONNX GraphSurgeon, we decompose a monolithic 18,398 node diffusion planner into three independently executable modules and reimplement the DPM-Solver++ denoising loop in native C++. Integrated as a ROS 2 node within Autoware, the open-source AD stack deployed on real vehicles worldwide, the system enables runtime-configurable solver parameters without model recompilation and per-step observability of the denoising process, breaking the black box of monolithic deployment. Unlike evaluations in standalone simulators such as CARLA, our benchmark operates within a production-grade stack and is validated through AWSIM closed-loop simulation. Through systematic comparison of DPM-Solver++ (first- and second-order) and DDIM across six step-count configurations (N in {3, 5, 7, 10, 15, 20}), we show that encoder caching yields a 3.2x latency reduction, and that second-order solving reduces FDE by 41% at N=3 compared to first-order. The complete codebase will be released as open-source, providing a direct path from simulation benchmarks to real-vehicle deployment.
Trust, Don't Trust, or Flip: Robust Preference-Based Reinforcement Learning with Multi-Expert Feedback
Jan 26, 2026Preference-based reinforcement learning (PBRL) offers a promising alternative to explicit reward engineering by learning from pairwise trajectory comparisons. However, real-world preference data often comes from heterogeneous annotators with varying reliability; some accurate, some noisy, and some systematically adversarial. Existing PBRL methods either treat all feedback equally or attempt to filter out unreliable sources, but both approaches fail when faced with adversarial annotators who systematically provide incorrect preferences. We introduce TriTrust-PBRL (TTP), a unified framework that jointly learns a shared reward model and expert-specific trust parameters from multi-expert preference feedback. The key insight is that trust parameters naturally evolve during gradient-based optimization to be positive (trust), near zero (ignore), or negative (flip), enabling the model to automatically invert adversarial preferences and recover useful signal rather than merely discarding corrupted feedback. We provide theoretical analysis establishing identifiability guarantees and detailed gradient analysis that explains how expert separation emerges naturally during training without explicit supervision. Empirically, we evaluate TTP on four diverse domains spanning manipulation tasks (MetaWorld) and locomotion (DM Control) under various corruption scenarios. TTP achieves state-of-the-art robustness, maintaining near-oracle performance under adversarial corruption while standard PBRL methods fail catastrophically. Notably, TTP outperforms existing baselines by successfully learning from mixed expert pools containing both reliable and adversarial annotators, all while requiring no expert features beyond identification indices and integrating seamlessly with existing PBRL pipelines.
SUG-Occ: An Explicit Semantics and Uncertainty Guided Sparse Learning Framework for Real-Time 3D Occupancy Prediction
Jan 16, 2026As autonomous driving moves toward full scene understanding, 3D semantic occupancy prediction has emerged as a crucial perception task, offering voxel-level semantics beyond traditional detection and segmentation paradigms. However, such a refined representation for scene understanding incurs prohibitive computation and memory overhead, posing a major barrier to practical real-time deployment. To address this, we propose SUG-Occ, an explicit Semantics and Uncertainty Guided Sparse Learning Enabled 3D Occupancy Prediction Framework, which exploits the inherent sparsity of 3D scenes to reduce redundant computation while maintaining geometric and semantic completeness. Specifically, we first utilize semantic and uncertainty priors to suppress projections from free space during view transformation while employing an explicit unsigned distance encoding to enhance geometric consistency, producing a structurally consistent sparse 3D representation. Secondly, we design an cascade sparse completion module via hyper cross sparse convolution and generative upsampling to enable efficiently coarse-to-fine reasoning. Finally, we devise an object contextual representation (OCR) based mask decoder that aggregates global semantic context from sparse features and refines voxel-wise predictions via lightweight query-context interactions, avoiding expensive attention operations over volumetric features. Extensive experiments on SemanticKITTI benchmark demonstrate that the proposed approach outperforms the baselines, achieving a 7.34/% improvement in accuracy and a 57.8\% gain in efficiency.
Trajectory Planning for UAV-Based Smart Farming Using Imitation-Based Triple Deep Q-Learning
Dec 21, 2025Unmanned aerial vehicles (UAVs) have emerged as a promising auxiliary platform for smart agriculture, capable of simultaneously performing weed detection, recognition, and data collection from wireless sensors. However, trajectory planning for UAV-based smart agriculture is challenging due to the high uncertainty of the environment, partial observations, and limited battery capacity of UAVs. To address these issues, we formulate the trajectory planning problem as a Markov decision process (MDP) and leverage multi-agent reinforcement learning (MARL) to solve it. Furthermore, we propose a novel imitation-based triple deep Q-network (ITDQN) algorithm, which employs an elite imitation mechanism to reduce exploration costs and utilizes a mediator Q-network over a double deep Q-network (DDQN) to accelerate and stabilize training and improve performance. Experimental results in both simulated and real-world environments demonstrate the effectiveness of our solution. Moreover, our proposed ITDQN outperforms DDQN by 4.43\% in weed recognition rate and 6.94\% in data collection rate.
EIA-SEC: Improved Actor-Critic Framework for Multi-UAV Collaborative Control in Smart Agriculture
Dec 21, 2025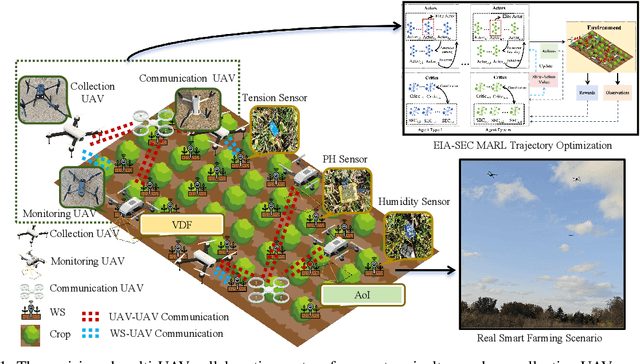
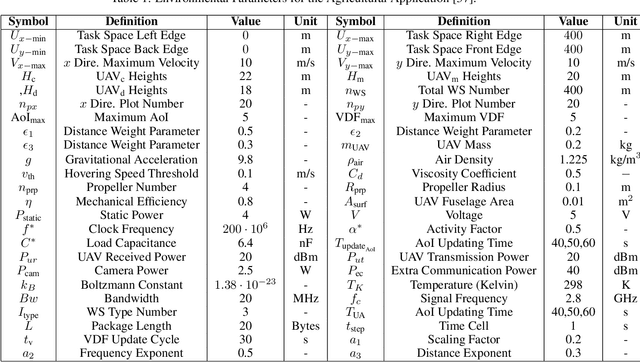
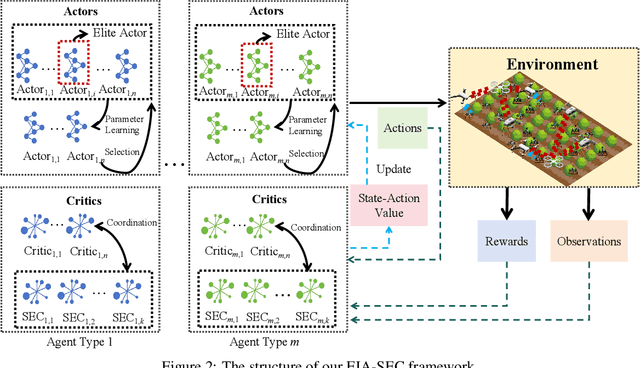
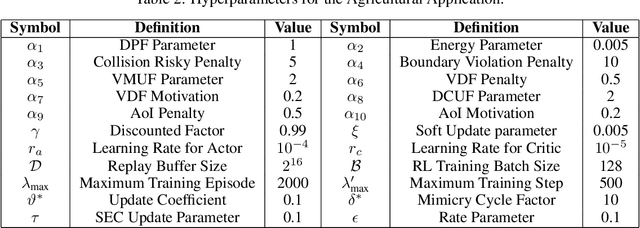
The widespread application of wireless communication technology has promoted the development of smart agriculture, where unmanned aerial vehicles (UAVs) play a multifunctional role. We target a multi-UAV smart agriculture system where UAVs cooperatively perform data collection, image acquisition, and communication tasks. In this context, we model a Markov decision process to solve the multi-UAV trajectory planning problem. Moreover, we propose a novel Elite Imitation Actor-Shared Ensemble Critic (EIA-SEC) framework, where agents adaptively learn from the elite agent to reduce trial-and-error costs, and a shared ensemble critic collaborates with each agent's local critic to ensure unbiased objective value estimates and prevent overestimation. Experimental results demonstrate that EIA-SEC outperforms state-of-the-art baselines in terms of reward performance, training stability, and convergence speed.
FM-EAC: Feature Model-based Enhanced Actor-Critic for Multi-Task Control in Dynamic Environments
Dec 17, 2025Model-based reinforcement learning (MBRL) and model-free reinforcement learning (MFRL) evolve along distinct paths but converge in the design of Dyna-Q [1]. However, modern RL methods still struggle with effective transferability across tasks and scenarios. Motivated by this limitation, we propose a generalized algorithm, Feature Model-Based Enhanced Actor-Critic (FM-EAC), that integrates planning, acting, and learning for multi-task control in dynamic environments. FM-EAC combines the strengths of MBRL and MFRL and improves generalizability through the use of novel feature-based models and an enhanced actor-critic framework. Simulations in both urban and agricultural applications demonstrate that FM-EAC consistently outperforms many state-of-the-art MBRL and MFRL methods. More importantly, different sub-networks can be customized within FM-EAC according to user-specific requirements.
You Share Beliefs, I Adapt: Progressive Heterogeneous Collaborative Perception
Sep 11, 2025Collaborative perception enables vehicles to overcome individual perception limitations by sharing information, allowing them to see further and through occlusions. In real-world scenarios, models on different vehicles are often heterogeneous due to manufacturer variations. Existing methods for heterogeneous collaborative perception address this challenge by fine-tuning adapters or the entire network to bridge the domain gap. However, these methods are impractical in real-world applications, as each new collaborator must undergo joint training with the ego vehicle on a dataset before inference, or the ego vehicle stores models for all potential collaborators in advance. Therefore, we pose a new question: Can we tackle this challenge directly during inference, eliminating the need for joint training? To answer this, we introduce Progressive Heterogeneous Collaborative Perception (PHCP), a novel framework that formulates the problem as few-shot unsupervised domain adaptation. Unlike previous work, PHCP dynamically aligns features by self-training an adapter during inference, eliminating the need for labeled data and joint training. Extensive experiments on the OPV2V dataset demonstrate that PHCP achieves strong performance across diverse heterogeneous scenarios. Notably, PHCP achieves performance comparable to SOTA methods trained on the entire dataset while using only a small amount of unlabeled data.