 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced Channel Decomposition Techniques in OTFS: A GSVD Approach for Multi-User Downlink
Apr 25, 2025In this paper, we propose a multi-user downlink system for two users based on the orthogonal time frequency space (OTFS) modulation scheme. The design leverages the generalized singular value decomposition (GSVD) of the channels between the base station and the two users, applying precoding and detection matrices based on the right and left singular vectors, respectively. We derive the analytical expressions for three scenarios and present the corresponding simulation results. These results demonstrate that, in terms of bit error rate (BER), the proposed system outperforms the conventional multi-user OTFS system in two scenarios when using minimum mean square error (MMSE) equalizers or precoder, both for perfect channel state information and for a scenario with channel estimation errors. In the third scenario, the design is equivalent to zero-forcing (ZF) precoding at the transmitter.
An Information-theoretic Multi-task Representation Learning Framework for Natural Language Understanding
Mar 06, 2025
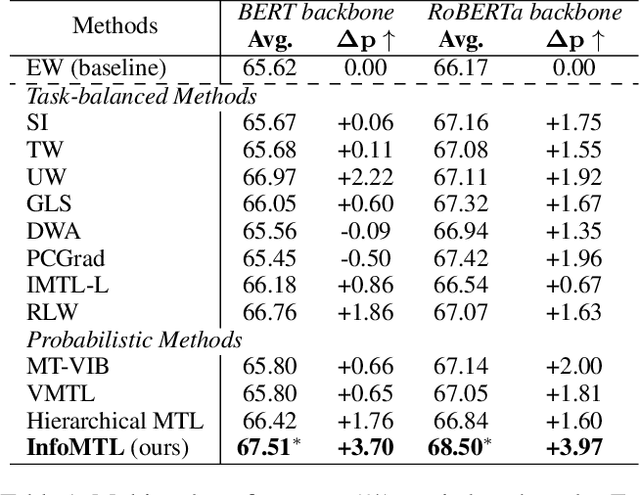

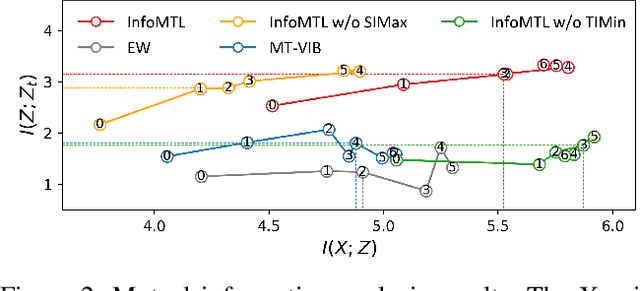
This paper proposes a new principled multi-task representation learning framework (InfoMTL) to extract noise-invariant sufficient representations for all tasks. It ensures sufficiency of shared representations for all tasks and mitigates the negative effect of redundant features, which can enhance language understanding of pre-trained language models (PLMs) under the multi-task paradigm. Firstly, a shared information maximization principle is proposed to learn more sufficient shared representations for all target tasks. It can avoid the insufficiency issue arising from representation compression in the multi-task paradigm. Secondly, a task-specific information minimization principle is designed to mitigate the negative effect of potential redundant features in the input for each task. It can compress task-irrelevant redundant information and preserve necessary information relevant to the target for multi-task prediction. Experiments on six classification benchmarks show that our method outperforms 12 comparative multi-task methods under the same multi-task settings, especially in data-constrained and noisy scenarios. Extensive experiments demonstrate that the learned representations are more sufficient, data-efficient, and robust.
eRSS-RAMP: A Rule-Adherence Motion Planner Based on Extended Responsibility-Sensitive Safety for Autonomous Driving
Sep 04, 2024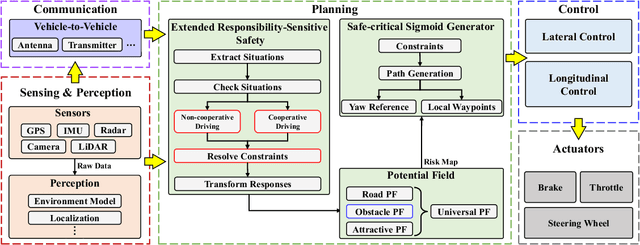
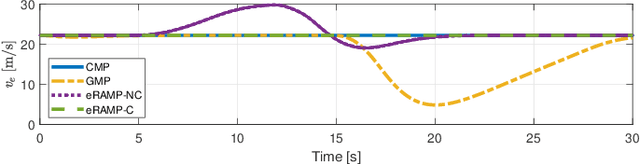
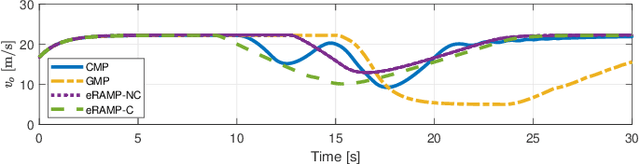
Driving safety and responsibility determination are indispensable pieces of the puzzle for autonomous driving. They are also deeply related to the allocation of right-of-way and the determination of accident liability. Therefore, Intel/Mobileye designed the responsibility-sensitive safety (RSS) framework to further enhance the safety regulation of autonomous driving, which mathematically defines rules for autonomous vehicles (AVs) behaviors in various traffic scenarios. However, the RSS framework's rules are relatively rudimentary in certain scenarios characterized by interaction uncertainty, especially those requiring collaborative driving during emergency collision avoidance. Besides, the integration of the RSS framework with motion planning is rarely discussed in current studies. Therefore, we proposed a rule-adherence motion planner (RAMP) based on the extended RSS (eRSS) regulation for non-connected and connected AVs in merging and emergency-avoiding scenarios. The simulation results indicate that the proposed method can achieve faster and safer lane merging performance (53.0% shorter merging length and a 73.5% decrease in merging time), and allows for more stable steering maneuvers in emergency collision avoidance, resulting in smoother paths for ego vehicle and surrounding vehicles.
Transferring Structure Knowledge: A New Task to Fake news Detection Towards Cold-Start Propagation
Jul 13, 2024Many fake news detection studies have achieved promising performance by extracting effective semantic and structure features from both content and propagation trees. However, it is challenging to apply them to practical situations, especially when using the trained propagation-based models to detect news with no propagation data. Towards this scenario, we study a new task named cold-start fake news detection, which aims to detect content-only samples with missing propagation. To achieve the task, we design a simple but effective Structure Adversarial Net (SAN) framework to learn transferable features from available propagation to boost the detection of content-only samples. SAN introduces a structure discriminator to estimate dissimilarities among learned features with and without propagation, and further learns structure-invariant features to enhance the generalization of existing propagation-based methods for content-only samples. We conduct qualitative and quantitative experiments on three datasets. Results show the challenge of the new task and the effectiveness of our SAN framework.
Representation Learning with Conditional Information Flow Maximization
Jun 08, 2024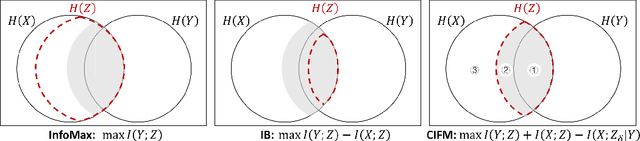
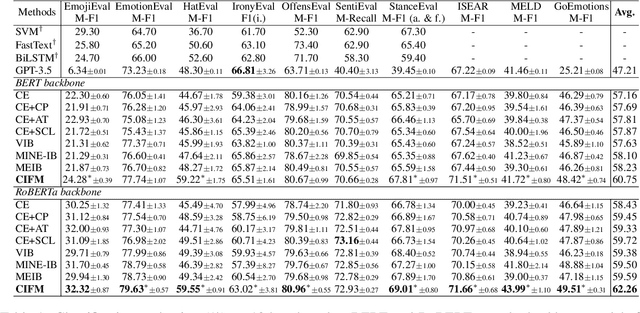

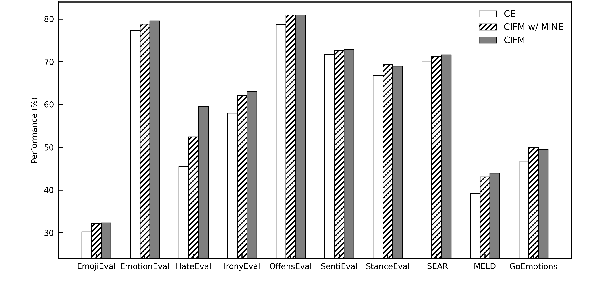
This paper proposes an information-theoretic representation learning framework, named conditional information flow maximization, to extract noise-invariant sufficient representations for the input data and target task. It promotes the learned representations have good feature uniformity and sufficient predictive ability, which can enhance the generalization of pre-trained language models (PLMs) for the target task. Firstly, an information flow maximization principle is proposed to learn more sufficient representations by simultaneously maximizing both input-representation and representation-label mutual information. In contrast to information bottleneck, we handle the input-representation information in an opposite way to avoid the over-compression issue of latent representations. Besides, to mitigate the negative effect of potential redundant features, a conditional information minimization principle is designed to eliminate negative redundant features while preserve noise-invariant features from the input. Experiments on 13 language understanding benchmarks demonstrate that our method effectively improves the performance of PLMs for classification and regression. Extensive experiments show that the learned representations are more sufficient, robust and transferable.
Structured Probabilistic Coding
Dec 25, 2023This paper presents a new supervised representation learning framework, namely structured probabilistic coding (SPC), to learn compact and informative representations from input related to the target task. SPC is an encoder-only probabilistic coding technology with a structured regularization from the target label space. It can enhance the generalization ability of pre-trained language models for better language understanding. Specifically, our probabilistic coding technology simultaneously performs information encoding and task prediction in one module to more fully utilize the effective information from input data. It uses variational inference in the output space to reduce randomness and uncertainty. Besides, to better control the probability distribution in the latent space, a structured regularization is proposed to promote class-level uniformity in the latent space. With the regularization term, SPC can preserve the Gaussian distribution structure of latent code as well as better cover the hidden space with class uniformly. Experimental results on 12 natural language understanding tasks demonstrate that our SPC effectively improves the performance of pre-trained language models for classification and regression. Extensive experiments show that SPC can enhance the generalization capability, robustness to label noise, and clustering quality of output representations.
Supervised Adversarial Contrastive Learning for Emotion Recognition in Conversations
Jun 02, 2023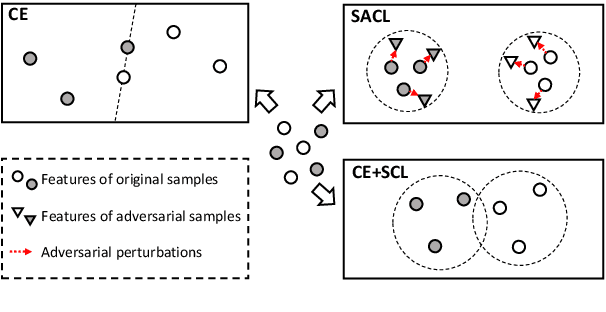
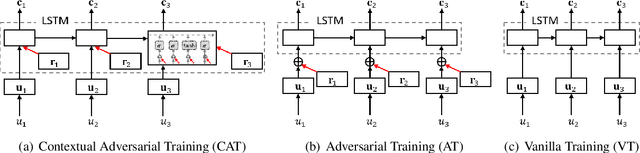
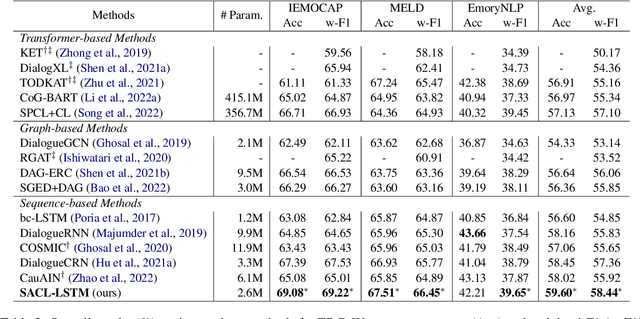
Extracting generalized and robust representations is a major challenge in emotion recognition in conversations (ERC). To address this, we propose a supervised adversarial contrastive learning (SACL) framework for learning class-spread structured representations. The framework applies contrast-aware adversarial training to generate worst-case samples and uses a joint class-spread contrastive learning objective on both original and adversarial samples. It can effectively utilize label-level feature consistency and retain fine-grained intra-class features. To avoid the negative impact of adversarial perturbations on context-dependent data, we design a contextual adversarial training strategy to learn more diverse features from context and enhance the model's context robustness. We develop a sequence-based method SACL-LSTM under this framework, to learn label-consistent and context-robust emotional features for ERC. Experiments on three datasets demonstrate that SACL-LSTM achieves state-of-the-art performance on ERC. Extended experiments prove the effectiveness of the SACL framework.
UCAS-IIE-NLP at SemEval-2023 Task 12: Enhancing Generalization of Multilingual BERT for Low-resource Sentiment Analysis
Jun 01, 2023



This paper describes our system designed for SemEval-2023 Task 12: Sentiment analysis for African languages. The challenge faced by this task is the scarcity of labeled data and linguistic resources in low-resource settings. To alleviate these, we propose a generalized multilingual system SACL-XLMR for sentiment analysis on low-resource languages. Specifically, we design a lexicon-based multilingual BERT to facilitate language adaptation and sentiment-aware representation learning. Besides, we apply a supervised adversarial contrastive learning technique to learn sentiment-spread structured representations and enhance model generalization. Our system achieved competitive results, largely outperforming baselines on both multilingual and zero-shot sentiment classification subtasks. Notably, the system obtained the 1st rank on the zero-shot classification subtask in the official ranking. Extensive experiments demonstrate the effectiveness of our system.
VarMAE: Pre-training of Variational Masked Autoencoder for Domain-adaptive Language Understanding
Nov 01, 2022
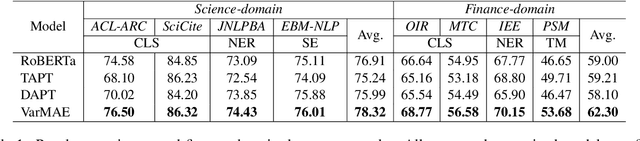

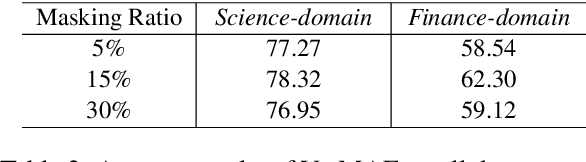
Pre-trained language models have achieved promising performance on general benchmarks, but underperform when migrated to a specific domain. Recent works perform pre-training from scratch or continual pre-training on domain corpora. However, in many specific domains, the limited corpus can hardly support obtaining precise representations. To address this issue, we propose a novel Transformer-based language model named VarMAE for domain-adaptive language understanding. Under the masked autoencoding objective, we design a context uncertainty learning module to encode the token's context into a smooth latent distribution. The module can produce diverse and well-formed contextual representations. Experiments on science- and finance-domain NLU tasks demonstrate that VarMAE can be efficiently adapted to new domains with limited resources.
PALI-NLP at SemEval-2022 Task 4: Discriminative Fine-tuning of Deep Transformers for Patronizing and Condescending Language Detection
Mar 09, 2022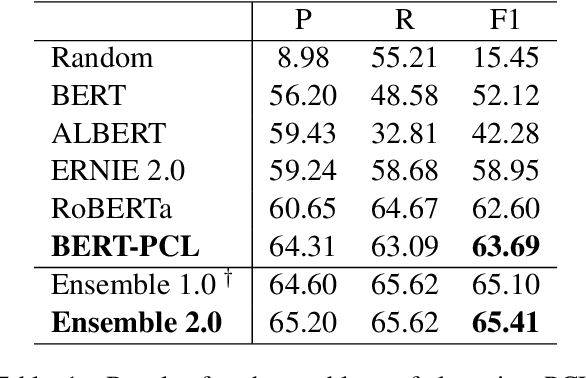
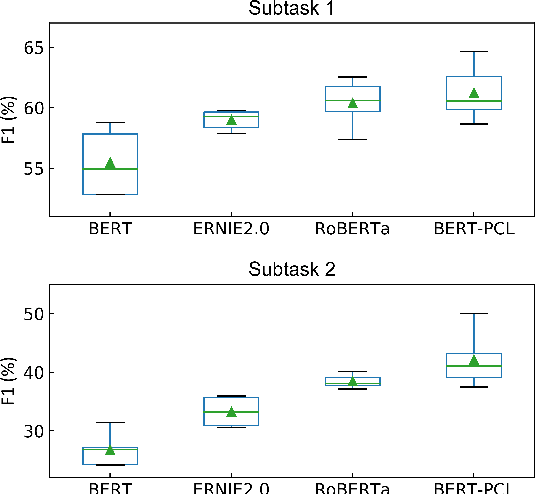
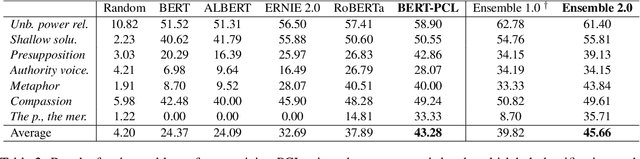
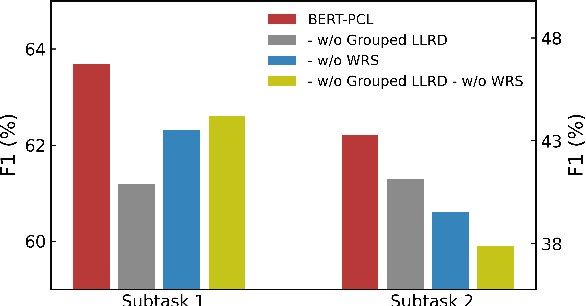
Patronizing and condescending language (PCL) has a large harmful impact and is difficult to detect, both for human judges and existing NLP systems. At SemEval-2022 Task 4, we propose a novel Transformer-based model and its ensembles to accurately understand such language context for PCL detection. To facilitate comprehension of the subtle and subjective nature of PCL, two fine-tuning strategies are applied to capture discriminative features from diverse linguistic behaviour and categorical distribution. The system achieves remarkable results on the official ranking, namely 1st in Subtask 1 and 5th in Subtask 2. Extensive experiments on the task demonstrate the effectiveness of our system and its strategies.