 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning with Conditional Information Flow Maximization
Paper and Code
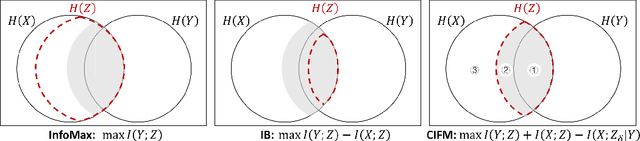
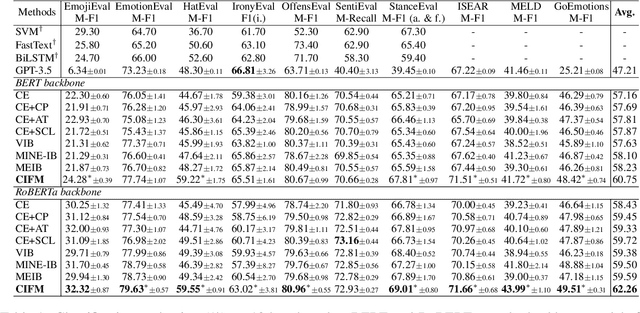

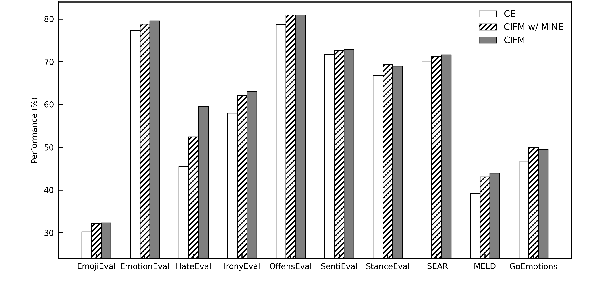
This paper proposes an information-theoretic representation learning framework, named conditional information flow maximization, to extract noise-invariant sufficient representations for the input data and target task. It promotes the learned representations have good feature uniformity and sufficient predictive ability, which can enhance the generalization of pre-trained language models (PLMs) for the target task. Firstly, an information flow maximization principle is proposed to learn more sufficient representations by simultaneously maximizing both input-representation and representation-label mutual information. In contrast to information bottleneck, we handle the input-representation information in an opposite way to avoid the over-compression issue of latent representations. Besides, to mitigate the negative effect of potential redundant features, a conditional information minimization principle is designed to eliminate negative redundant features while preserve noise-invariant features from the input. Experiments on 13 language understanding benchmarks demonstrate that our method effectively improves the performance of PLMs for classification and regression. Extensive experiments show that the learned representations are more sufficient, robust and transferable.