 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multi-Hop Fact Verification with Structured Knowledge-Augmented Large Language Models
Mar 11, 2025
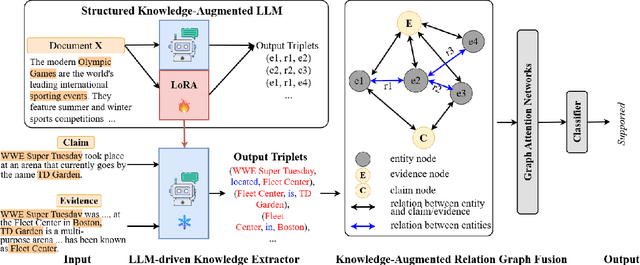
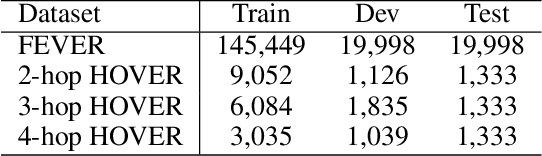
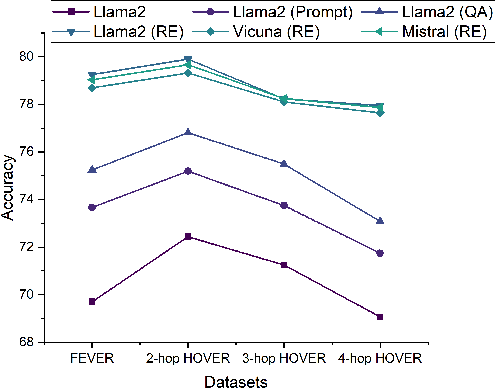
The rapid development of social platforms exacerbates the dissemination of misinformation, which stimulates the research in fact verification. Recent studies tend to leverage semantic features to solve this problem as a single-hop task. However, the process of verifying a claim requires several pieces of evidence with complicated inner logic and relations to verify the given claim in real-world situations. Recent studies attempt to improve both understanding and reasoning abilities to enhance the performance, but they overlook the crucial relations between entities that benefit models to understand better and facilitate the prediction. To emphasize the significance of relations, we resort to Large Language Models (LLMs) considering their excellent understanding ability. Instead of other methods using LLMs as the predictor, we take them as relation extractors, for they do better in understanding rather than reasoning according to the experimental results. Thus, to solve the challenges above, we propose a novel Structured Knowledge-Augmented LLM-based Network (LLM-SKAN) for multi-hop fact verification. Specifically, we utilize an LLM-driven Knowledge Extractor to capture fine-grained information, including entities and their complicated relations. Besides, we leverage a Knowledge-Augmented Relation Graph Fusion module to interact with each node and learn better claim-evidence representations comprehensively. The experimental results on four common-used datasets demonstrate the effectiveness and superiority of our model.
An Information-theoretic Multi-task Representation Learning Framework for Natural Language Understanding
Mar 06, 2025
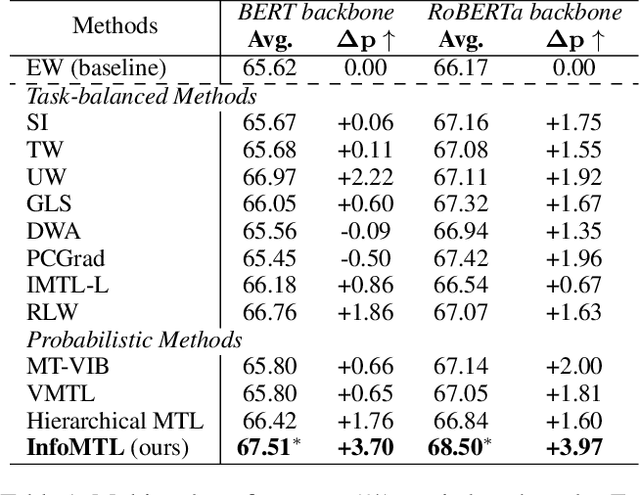

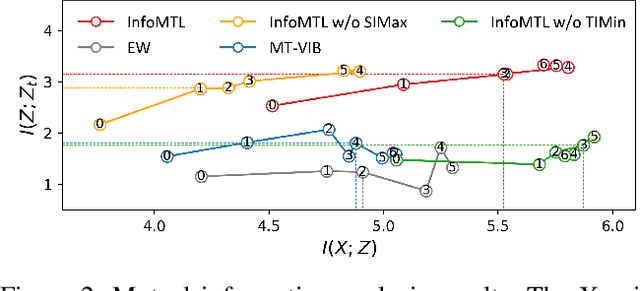
This paper proposes a new principled multi-task representation learning framework (InfoMTL) to extract noise-invariant sufficient representations for all tasks. It ensures sufficiency of shared representations for all tasks and mitigates the negative effect of redundant features, which can enhance language understanding of pre-trained language models (PLMs) under the multi-task paradigm. Firstly, a shared information maximization principle is proposed to learn more sufficient shared representations for all target tasks. It can avoid the insufficiency issue arising from representation compression in the multi-task paradigm. Secondly, a task-specific information minimization principle is designed to mitigate the negative effect of potential redundant features in the input for each task. It can compress task-irrelevant redundant information and preserve necessary information relevant to the target for multi-task prediction. Experiments on six classification benchmarks show that our method outperforms 12 comparative multi-task methods under the same multi-task settings, especially in data-constrained and noisy scenarios. Extensive experiments demonstrate that the learned representations are more sufficient, data-efficient, and robust.
Transferring Structure Knowledge: A New Task to Fake news Detection Towards Cold-Start Propagation
Jul 13, 2024Many fake news detection studies have achieved promising performance by extracting effective semantic and structure features from both content and propagation trees. However, it is challenging to apply them to practical situations, especially when using the trained propagation-based models to detect news with no propagation data. Towards this scenario, we study a new task named cold-start fake news detection, which aims to detect content-only samples with missing propagation. To achieve the task, we design a simple but effective Structure Adversarial Net (SAN) framework to learn transferable features from available propagation to boost the detection of content-only samples. SAN introduces a structure discriminator to estimate dissimilarities among learned features with and without propagation, and further learns structure-invariant features to enhance the generalization of existing propagation-based methods for content-only samples. We conduct qualitative and quantitative experiments on three datasets. Results show the challenge of the new task and the effectiveness of our SAN framework.
Representation Learning with Conditional Information Flow Maximization
Jun 08, 2024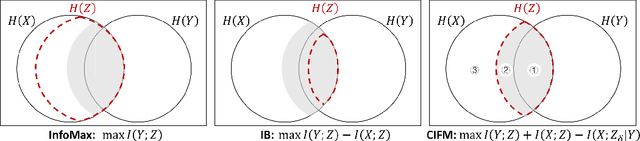
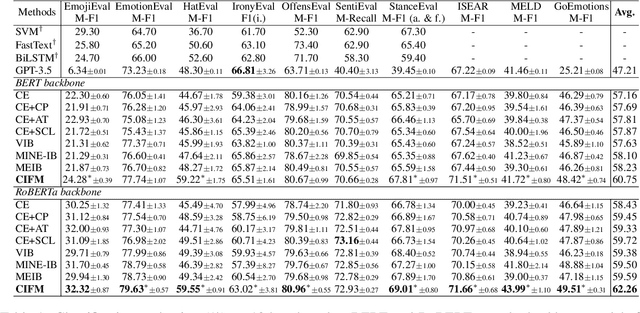

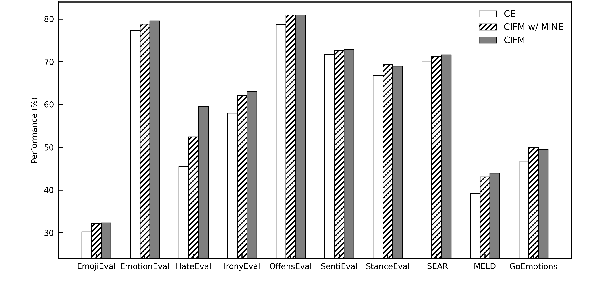
This paper proposes an information-theoretic representation learning framework, named conditional information flow maximization, to extract noise-invariant sufficient representations for the input data and target task. It promotes the learned representations have good feature uniformity and sufficient predictive ability, which can enhance the generalization of pre-trained language models (PLMs) for the target task. Firstly, an information flow maximization principle is proposed to learn more sufficient representations by simultaneously maximizing both input-representation and representation-label mutual information. In contrast to information bottleneck, we handle the input-representation information in an opposite way to avoid the over-compression issue of latent representations. Besides, to mitigate the negative effect of potential redundant features, a conditional information minimization principle is designed to eliminate negative redundant features while preserve noise-invariant features from the input. Experiments on 13 language understanding benchmarks demonstrate that our method effectively improves the performance of PLMs for classification and regression. Extensive experiments show that the learned representations are more sufficient, robust and transferable.
Structured Probabilistic Coding
Dec 25, 2023This paper presents a new supervised representation learning framework, namely structured probabilistic coding (SPC), to learn compact and informative representations from input related to the target task. SPC is an encoder-only probabilistic coding technology with a structured regularization from the target label space. It can enhance the generalization ability of pre-trained language models for better language understanding. Specifically, our probabilistic coding technology simultaneously performs information encoding and task prediction in one module to more fully utilize the effective information from input data. It uses variational inference in the output space to reduce randomness and uncertainty. Besides, to better control the probability distribution in the latent space, a structured regularization is proposed to promote class-level uniformity in the latent space. With the regularization term, SPC can preserve the Gaussian distribution structure of latent code as well as better cover the hidden space with class uniformly. Experimental results on 12 natural language understanding tasks demonstrate that our SPC effectively improves the performance of pre-trained language models for classification and regression. Extensive experiments show that SPC can enhance the generalization capability, robustness to label noise, and clustering quality of output representations.
Are Large Language Models Good Fact Checkers: A Preliminary Study
Nov 29, 2023



Recently, Large Language Models (LLMs) have drawn significant attention due to their outstanding reasoning capabilities and extensive knowledge repository, positioning them as superior in handling various natural language processing tasks compared to other language models. In this paper, we present a preliminary investigation into the potential of LLMs in fact-checking. This study aims to comprehensively evaluate various LLMs in tackling specific fact-checking subtasks, systematically evaluating their capabilities, and conducting a comparative analysis of their performance against pre-trained and state-of-the-art low-parameter models. Experiments demonstrate that LLMs achieve competitive performance compared to other small models in most scenarios. However, they encounter challenges in effectively handling Chinese fact verification and the entirety of the fact-checking pipeline due to language inconsistencies and hallucinations. These findings underscore the need for further exploration and research to enhance the proficiency of LLMs as reliable fact-checkers, unveiling the potential capability of LLMs and the possible challenges in fact-checking tasks.
Can Large Language Models Understand Content and Propagation for Misinformation Detection: An Empirical Study
Nov 21, 2023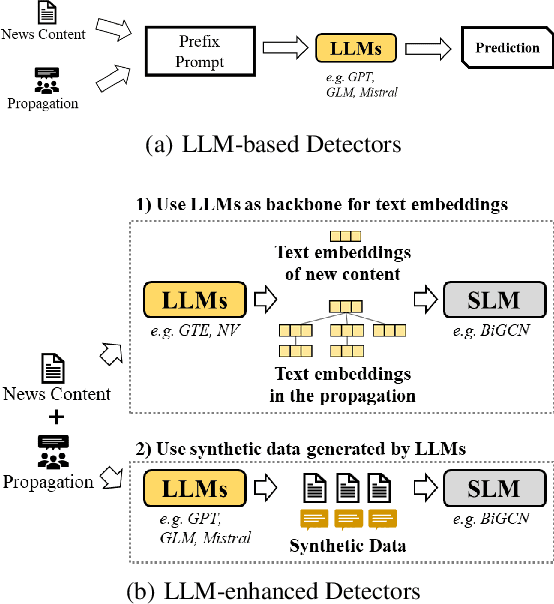
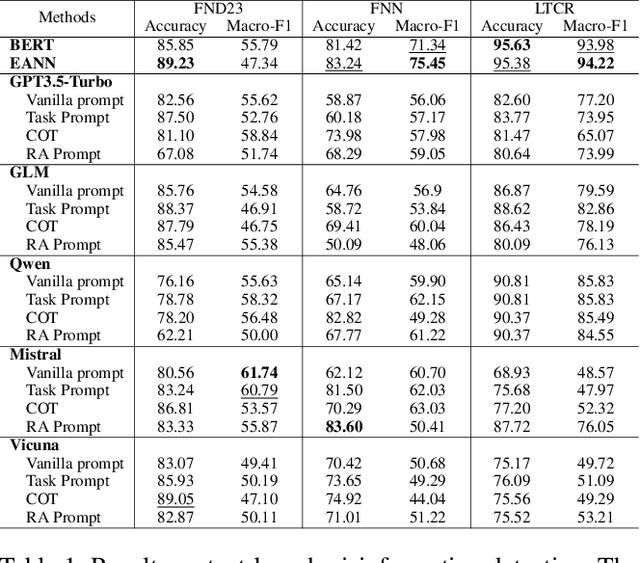
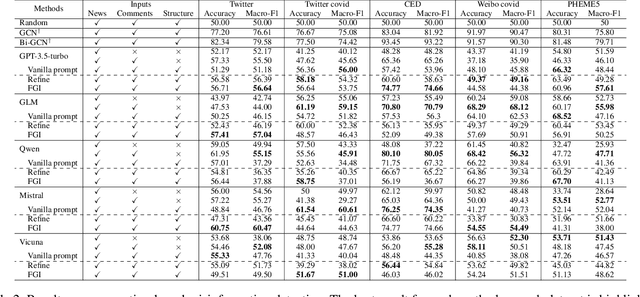
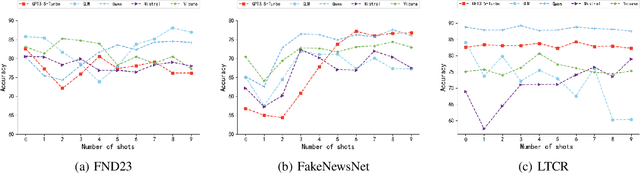
Large Language Models (LLMs) have garnered significant attention for their powerful ability in natural language understanding and reasoning. In this paper, we present a comprehensive empirical study to explore the performance of LLMs on misinformation detection tasks. This study stands as the pioneering investigation into the understanding capabilities of multiple LLMs regarding both content and propagation across social media platforms. Our empirical studies on five misinformation detection datasets show that LLMs with diverse prompts achieve comparable performance in text-based misinformation detection but exhibit notably constrained capabilities in comprehending propagation structure compared to existing models in propagation-based misinformation detection. Besides, we further design four instruction-tuned strategies to enhance LLMs for both content and propagation-based misinformation detection. These strategies boost LLMs to actively learn effective features from multiple instances or hard instances, and eliminate irrelevant propagation structures, thereby achieving better detection performance. Extensive experiments further demonstrate LLMs would play a better capacity in content and propagation structure under these proposed strategies and achieve promising detection performance. These findings highlight the potential ability of LLMs to detect misinformation.
Supervised Adversarial Contrastive Learning for Emotion Recognition in Conversations
Jun 02, 2023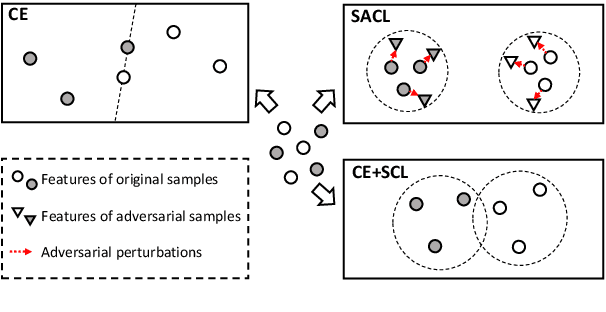
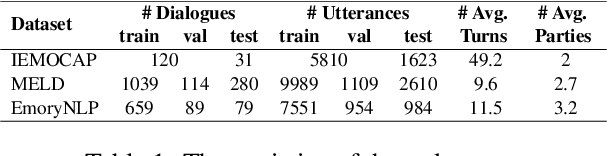
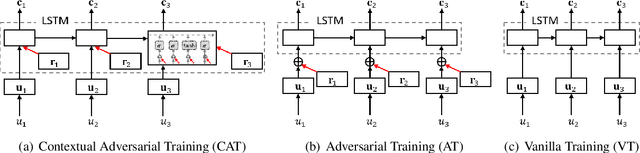
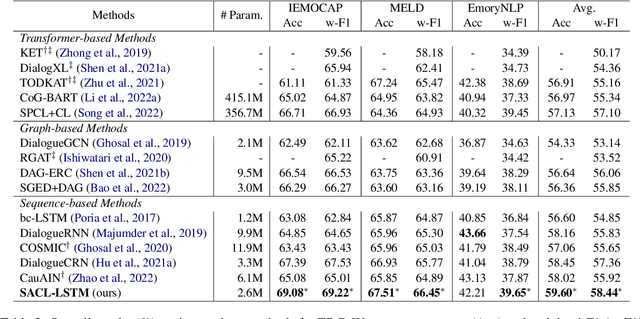
Extracting generalized and robust representations is a major challenge in emotion recognition in conversations (ERC). To address this, we propose a supervised adversarial contrastive learning (SACL) framework for learning class-spread structured representations. The framework applies contrast-aware adversarial training to generate worst-case samples and uses a joint class-spread contrastive learning objective on both original and adversarial samples. It can effectively utilize label-level feature consistency and retain fine-grained intra-class features. To avoid the negative impact of adversarial perturbations on context-dependent data, we design a contextual adversarial training strategy to learn more diverse features from context and enhance the model's context robustness. We develop a sequence-based method SACL-LSTM under this framework, to learn label-consistent and context-robust emotional features for ERC. Experiments on three datasets demonstrate that SACL-LSTM achieves state-of-the-art performance on ERC. Extended experiments prove the effectiveness of the SACL framework.
UCAS-IIE-NLP at SemEval-2023 Task 12: Enhancing Generalization of Multilingual BERT for Low-resource Sentiment Analysis
Jun 01, 2023



This paper describes our system designed for SemEval-2023 Task 12: Sentiment analysis for African languages. The challenge faced by this task is the scarcity of labeled data and linguistic resources in low-resource settings. To alleviate these, we propose a generalized multilingual system SACL-XLMR for sentiment analysis on low-resource languages. Specifically, we design a lexicon-based multilingual BERT to facilitate language adaptation and sentiment-aware representation learning. Besides, we apply a supervised adversarial contrastive learning technique to learn sentiment-spread structured representations and enhance model generalization. Our system achieved competitive results, largely outperforming baselines on both multilingual and zero-shot sentiment classification subtasks. Notably, the system obtained the 1st rank on the zero-shot classification subtask in the official ranking. Extensive experiments demonstrate the effectiveness of our system.
Speaker-Guided Encoder-Decoder Framework for Emotion Recognition in Conversation
Jun 07, 2022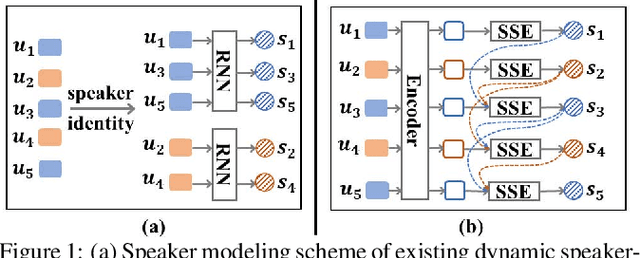
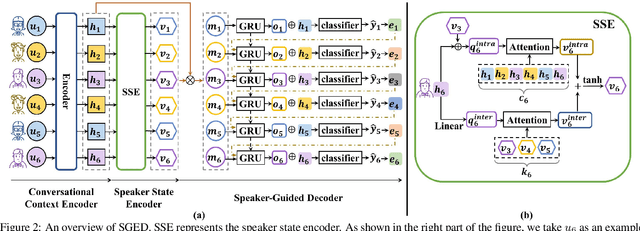
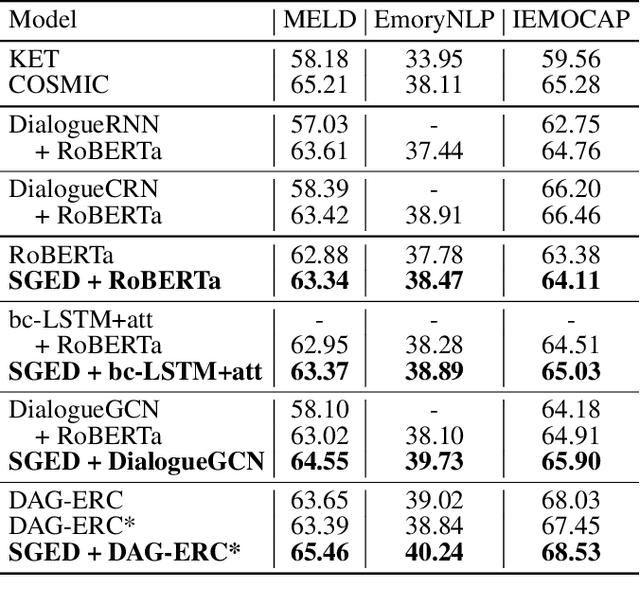
The emotion recognition in conversation (ERC) task aims to predict the emotion label of an utterance in a conversation. Since the dependencies between speakers are complex and dynamic, which consist of intra- and inter-speaker dependencies, the modeling of speaker-specific information is a vital role in ERC. Although existing researchers have proposed various methods of speaker interaction modeling, they cannot explore dynamic intra- and inter-speaker dependencies jointly, leading to the insufficient comprehension of context and further hindering emotion prediction. To this end, we design a novel speaker modeling scheme that explores intra- and inter-speaker dependencies jointly in a dynamic manner. Besides, we propose a Speaker-Guided Encoder-Decoder (SGED) framework for ERC, which fully exploits speaker information for the decoding of emotion. We use different existing methods as the conversational context encoder of our framework, showing the high scalability and flexibility of the proposed framework. Experimental results demonstrate the superiority and effectiveness of SGED.