 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiview Point Cloud Registration Based on Minimum Potential Energy for Free-Form Blade Measurement
Feb 11, 2025Point cloud registration is an essential step for free-form blade reconstruction in industrial measurement. Nonetheless, measuring defects of the 3D acquisition system unavoidably result in noisy and incomplete point cloud data, which renders efficient and accurate registration challenging. In this paper, we propose a novel global registration method that is based on the minimum potential energy (MPE) method to address these problems. The basic strategy is that the objective function is defined as the minimum potential energy optimization function of the physical registration system. The function distributes more weight to the majority of inlier points and less weight to the noise and outliers, which essentially reduces the influence of perturbations in the mathematical formulation. We decompose the solution into a globally optimal approximation procedure and a fine registration process with the trimmed iterative closest point algorithm to boost convergence. The approximation procedure consists of two main steps. First, according to the construction of the force traction operator, we can simply compute the position of the potential energy minimum. Second, to find the MPE point, we propose a new theory that employs two flags to observe the status of the registration procedure. We demonstrate the performance of the proposed algorithm on four types of blades. The proposed method outperforms the other global methods in terms of both accuracy and noise resistance.
VarMAE: Pre-training of Variational Masked Autoencoder for Domain-adaptive Language Understanding
Nov 01, 2022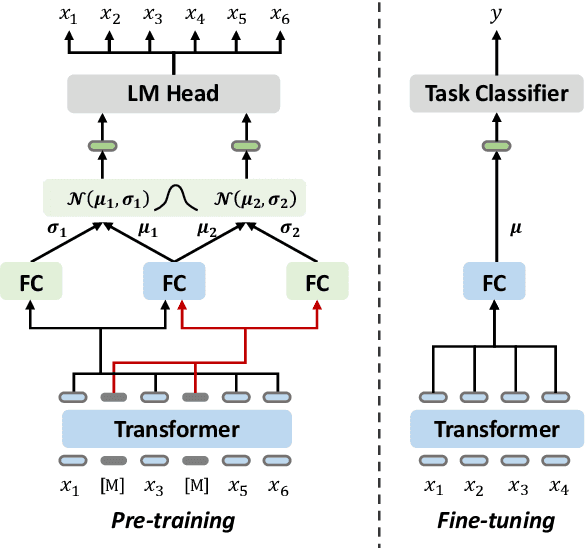
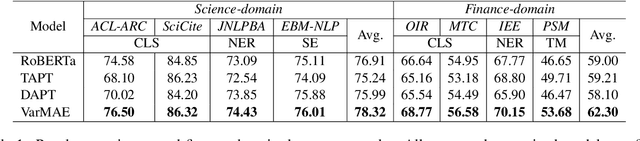

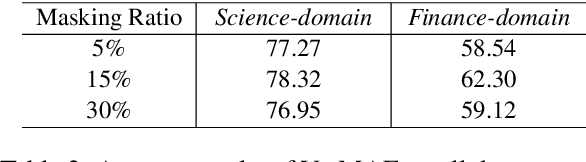
Pre-trained language models have achieved promising performance on general benchmarks, but underperform when migrated to a specific domain. Recent works perform pre-training from scratch or continual pre-training on domain corpora. However, in many specific domains, the limited corpus can hardly support obtaining precise representations. To address this issue, we propose a novel Transformer-based language model named VarMAE for domain-adaptive language understanding. Under the masked autoencoding objective, we design a context uncertainty learning module to encode the token's context into a smooth latent distribution. The module can produce diverse and well-formed contextual representations. Experiments on science- and finance-domain NLU tasks demonstrate that VarMAE can be efficiently adapted to new domains with limited resources.
PALI-NLP at SemEval-2022 Task 4: Discriminative Fine-tuning of Deep Transformers for Patronizing and Condescending Language Detection
Mar 09, 2022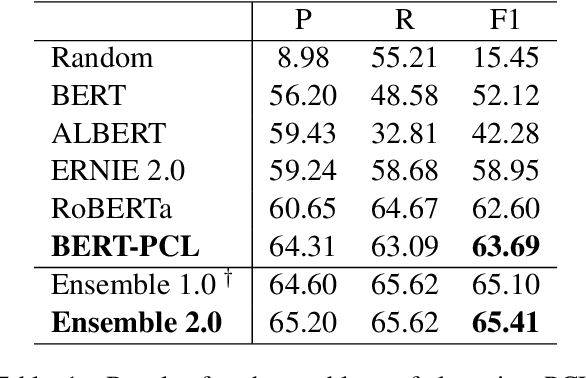
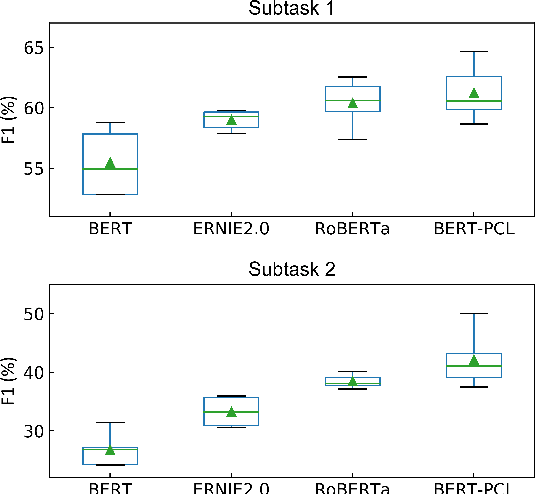
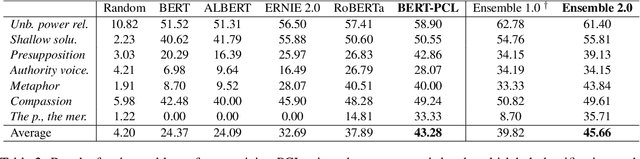
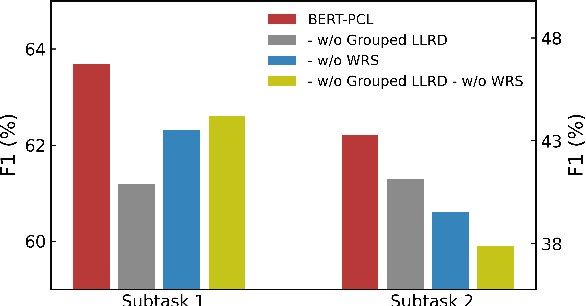
Patronizing and condescending language (PCL) has a large harmful impact and is difficult to detect, both for human judges and existing NLP systems. At SemEval-2022 Task 4, we propose a novel Transformer-based model and its ensembles to accurately understand such language context for PCL detection. To facilitate comprehension of the subtle and subjective nature of PCL, two fine-tuning strategies are applied to capture discriminative features from diverse linguistic behaviour and categorical distribution. The system achieves remarkable results on the official ranking, namely 1st in Subtask 1 and 5th in Subtask 2. Extensive experiments on the task demonstrate the effectiveness of our system and its strategies.
MM-DFN: Multimodal Dynamic Fusion Network for Emotion Recognition in Conversations
Mar 04, 2022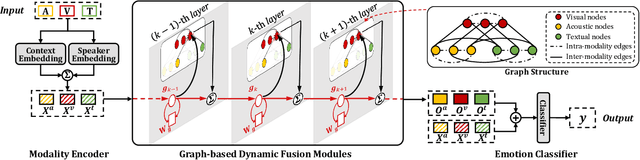


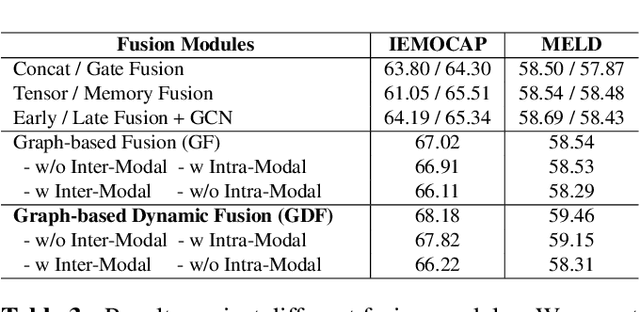
Emotion Recognition in Conversations (ERC) has considerable prospects for developing empathetic machines. For multimodal ERC, it is vital to understand context and fuse modality information in conversations. Recent graph-based fusion methods generally aggregate multimodal information by exploring unimodal and cross-modal interactions in a graph. However, they accumulate redundant information at each layer, limiting the context understanding between modalities. In this paper, we propose a novel Multimodal Dynamic Fusion Network (MM-DFN) to recognize emotions by fully understanding multimodal conversational context. Specifically, we design a new graph-based dynamic fusion module to fuse multimodal contextual features in a conversation. The module reduces redundancy and enhances complementarity between modalities by capturing the dynamics of contextual information in different semantic spaces. Extensive experiments on two public benchmark datasets demonstrate the effectiveness and superiority of MM-DFN.
Sequential Attention Module for Natural Language Processing
Sep 07, 2021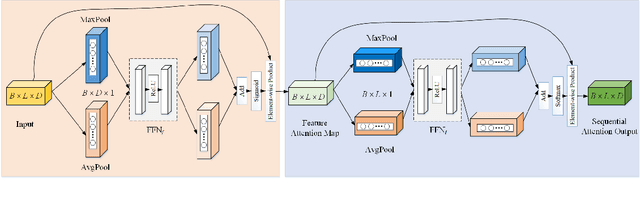


Recently, large pre-trained neural language models have attained remarkable performance on many downstream natural language processing (NLP) applications via fine-tuning. In this paper, we target at how to further improve the token representations on the language models. We, therefore, propose a simple yet effective plug-and-play module, Sequential Attention Module (SAM), on the token embeddings learned from a pre-trained language model. Our proposed SAM consists of two main attention modules deployed sequentially: Feature-wise Attention Module (FAM) and Token-wise Attention Module (TAM). More specifically, FAM can effectively identify the importance of features at each dimension and promote the effect via dot-product on the original token embeddings for downstream NLP applications. Meanwhile, TAM can further re-weight the features at the token-wise level. Moreover, we propose an adaptive filter on FAM to prevent noise impact and increase information absorption. Finally, we conduct extensive experiments to demonstrate the advantages and properties of our proposed SAM. We first show how SAM plays a primary role in the champion solution of two subtasks of SemEval'21 Task 7. After that, we apply SAM on sentiment analysis and three popular NLP tasks and demonstrate that SAM consistently outperforms the state-of-the-art baselines.
RefBERT: Compressing BERT by Referencing to Pre-computed Representations
Jun 11, 2021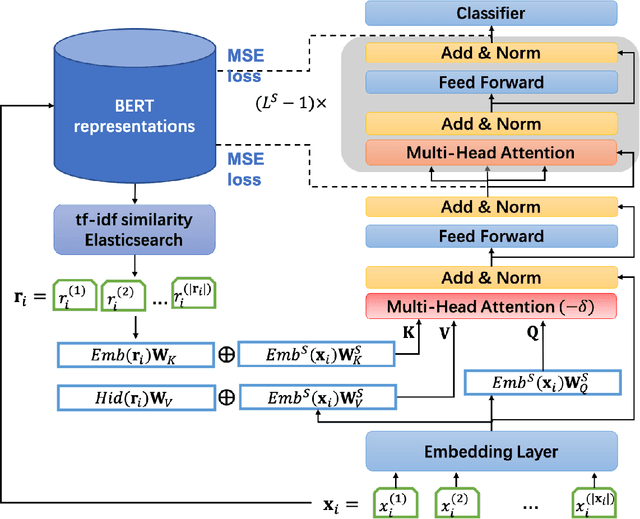
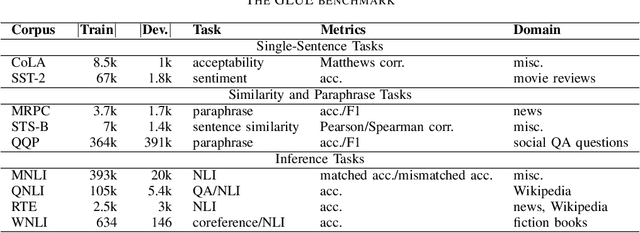

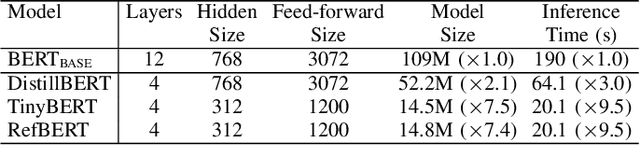
Recently developed large pre-trained language models, e.g., BERT, have achieved remarkable performance in many downstream natural language processing applications. These pre-trained language models often contain hundreds of millions of parameters and suffer from high computation and latency in real-world applications. It is desirable to reduce the computation overhead of the models for fast training and inference while keeping the model performance in downstream applications. Several lines of work utilize knowledge distillation to compress the teacher model to a smaller student model. However, they usually discard the teacher's knowledge when in inference. Differently, in this paper, we propose RefBERT to leverage the knowledge learned from the teacher, i.e., facilitating the pre-computed BERT representation on the reference sample and compressing BERT into a smaller student model. To guarantee our proposal, we provide theoretical justification on the loss function and the usage of reference samples. Significantly, the theoretical result shows that including the pre-computed teacher's representations on the reference samples indeed increases the mutual information in learning the student model. Finally, we conduct the empirical evaluation and show that our RefBERT can beat the vanilla TinyBERT over 8.1\% and achieves more than 94\% of the performance of $\BERTBASE$ on the GLUE benchmark. Meanwhile, RefBERT is 7.4x smaller and 9.5x faster on inference than BERT$_{\rm BASE}$.
PALI at SemEval-2021 Task 2: Fine-Tune XLM-RoBERTa for Word in Context Disambiguation
Apr 21, 2021

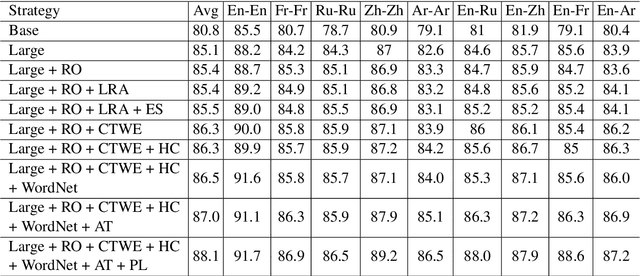
This paper presents the PALI team's winning system for SemEval-2021 Task 2: Multilingual and Cross-lingual Word-in-Context Disambiguation. We fine-tune XLM-RoBERTa model to solve the task of word in context disambiguation, i.e., to determine whether the target word in the two contexts contains the same meaning or not. In the implementation, we first specifically design an input tag to emphasize the target word in the contexts. Second, we construct a new vector on the fine-tuned embeddings from XLM-RoBERTa and feed it to a fully-connected network to output the probability of whether the target word in the context has the same meaning or not. The new vector is attained by concatenating the embedding of the [CLS] token and the embeddings of the target word in the contexts. In training, we explore several tricks, such as the Ranger optimizer, data augmentation, and adversarial training, to improve the model prediction. Consequently, we attain first place in all four cross-lingual tasks.
Sattiy at SemEval-2021 Task 9: An Ensemble Solution for Statement Verification and Evidence Finding with Tables
Apr 21, 2021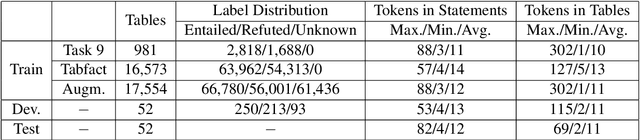
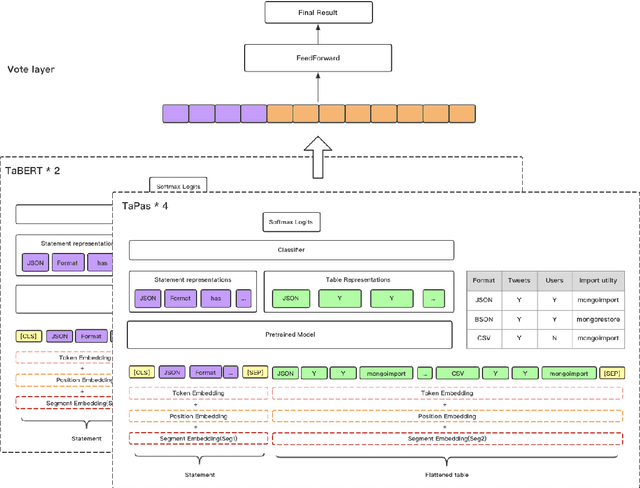
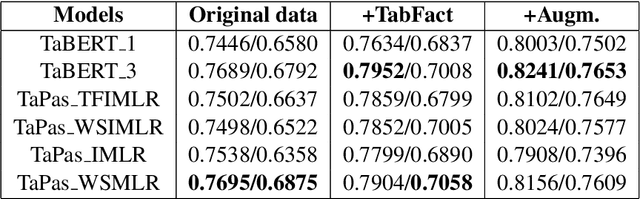
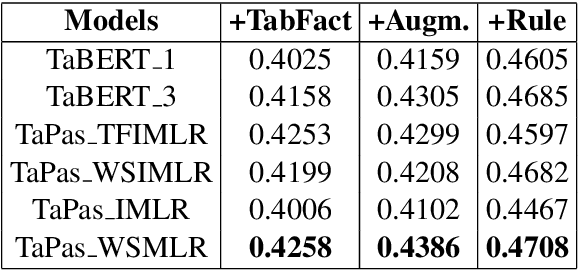
Question answering from semi-structured tables can be seen as a semantic parsing task and is significant and practical for pushing the boundary of natural language understanding. Existing research mainly focuses on understanding contents from unstructured evidence, e.g., news, natural language sentences, and documents. The task of verification from structured evidence, such as tables, charts, and databases, is still less explored. This paper describes sattiy team's system in SemEval-2021 task 9: Statement Verification and Evidence Finding with Tables (SEM-TAB-FACT). This competition aims to verify statements and to find evidence from tables for scientific articles and to promote the proper interpretation of the surrounding article. In this paper, we exploited ensemble models of pre-trained language models over tables, TaPas and TaBERT, for Task A and adjust the result based on some rules extracted for Task B. Finally, in the leaderboard, we attain the F1 scores of 0.8496 and 0.7732 in Task A for the 2-way and 3-way evaluation, respectively, and the F1 score of 0.4856 in Task B.
MagicPai at SemEval-2021 Task 7: Method for Detecting and Rating Humor Based on Multi-Task Adversarial Training
Apr 21, 2021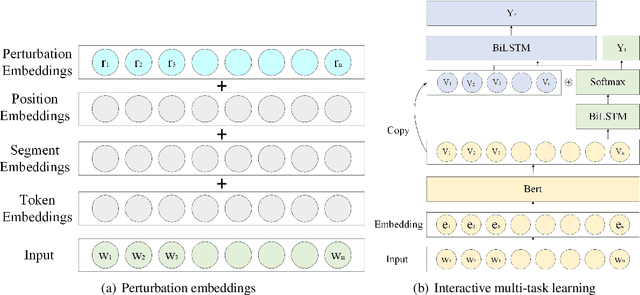
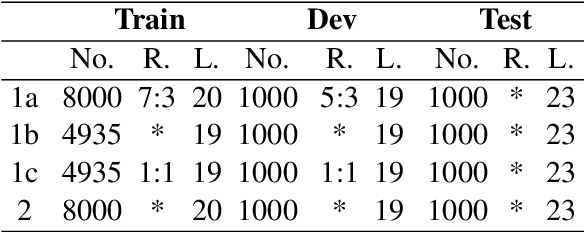
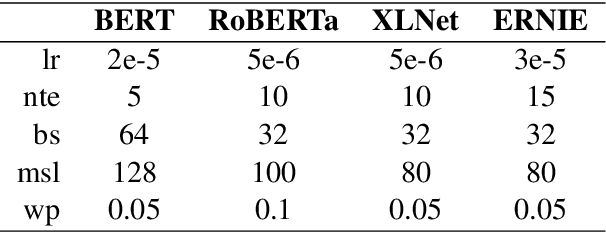
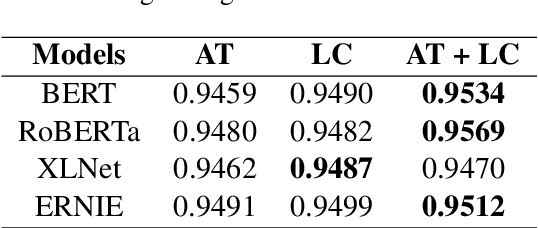
This paper describes MagicPai's system for SemEval 2021 Task 7, HaHackathon: Detecting and Rating Humor and Offense. This task aims to detect whether the text is humorous and how humorous it is. There are four subtasks in the competition. In this paper, we mainly present our solution, a multi-task learning model based on adversarial examples, for task 1a and 1b. More specifically, we first vectorize the cleaned dataset and add the perturbation to obtain more robust embedding representations. We then correct the loss via the confidence level. Finally, we perform interactive joint learning on multiple tasks to capture the relationship between whether the text is humorous and how humorous it is. The final result shows the effectiveness of our system.
* 7 pages, 1 figure, 4 tables