 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-DFN: Multimodal Dynamic Fusion Network for Emotion Recognition in Conversations
Paper and Code
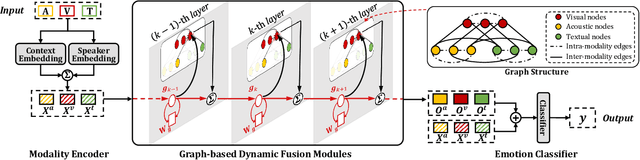


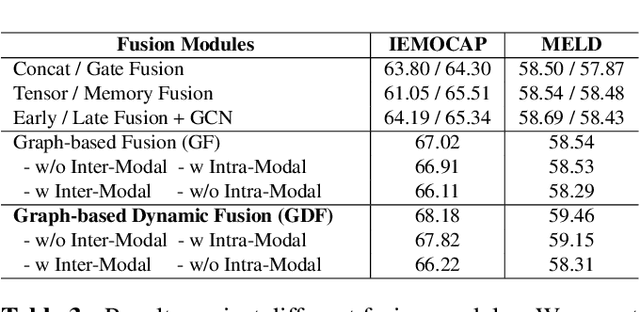
Emotion Recognition in Conversations (ERC) has considerable prospects for developing empathetic machines. For multimodal ERC, it is vital to understand context and fuse modality information in conversations. Recent graph-based fusion methods generally aggregate multimodal information by exploring unimodal and cross-modal interactions in a graph. However, they accumulate redundant information at each layer, limiting the context understanding between modalities. In this paper, we propose a novel Multimodal Dynamic Fusion Network (MM-DFN) to recognize emotions by fully understanding multimodal conversational context. Specifically, we design a new graph-based dynamic fusion module to fuse multimodal contextual features in a conversation. The module reduces redundancy and enhances complementarity between modalities by capturing the dynamics of contextual information in different semantic spaces. Extensive experiments on two public benchmark datasets demonstrate the effectiveness and superiority of MM-DFN.