 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVarMAE: Pre-training of Variational Masked Autoencoder for Domain-adaptive Language Understanding
Nov 01, 2022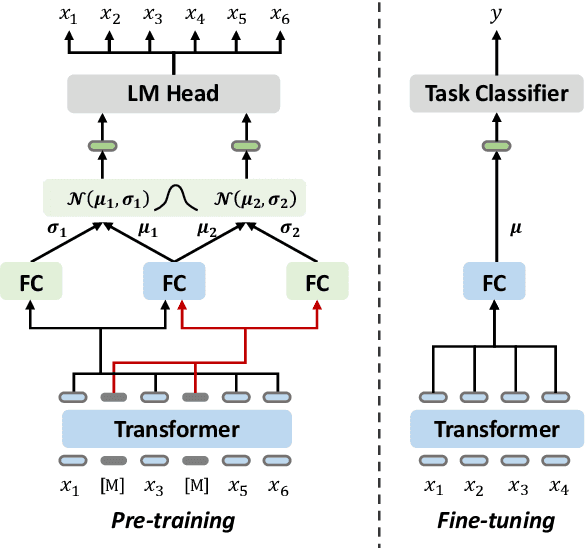
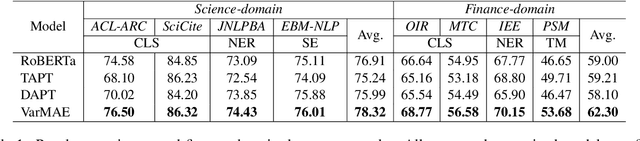

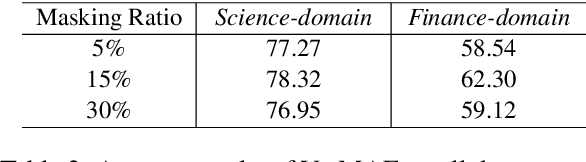
Pre-trained language models have achieved promising performance on general benchmarks, but underperform when migrated to a specific domain. Recent works perform pre-training from scratch or continual pre-training on domain corpora. However, in many specific domains, the limited corpus can hardly support obtaining precise representations. To address this issue, we propose a novel Transformer-based language model named VarMAE for domain-adaptive language understanding. Under the masked autoencoding objective, we design a context uncertainty learning module to encode the token's context into a smooth latent distribution. The module can produce diverse and well-formed contextual representations. Experiments on science- and finance-domain NLU tasks demonstrate that VarMAE can be efficiently adapted to new domains with limited resources.
MM-DFN: Multimodal Dynamic Fusion Network for Emotion Recognition in Conversations
Mar 04, 2022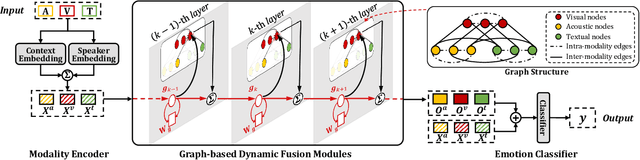


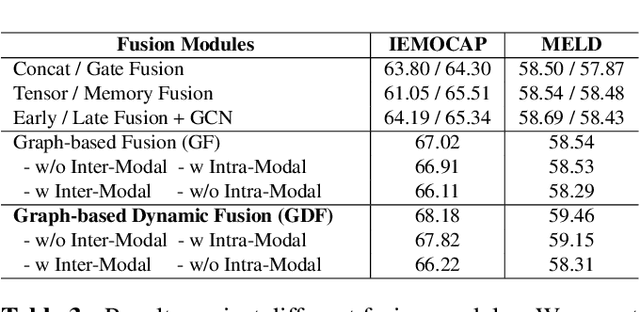
Emotion Recognition in Conversations (ERC) has considerable prospects for developing empathetic machines. For multimodal ERC, it is vital to understand context and fuse modality information in conversations. Recent graph-based fusion methods generally aggregate multimodal information by exploring unimodal and cross-modal interactions in a graph. However, they accumulate redundant information at each layer, limiting the context understanding between modalities. In this paper, we propose a novel Multimodal Dynamic Fusion Network (MM-DFN) to recognize emotions by fully understanding multimodal conversational context. Specifically, we design a new graph-based dynamic fusion module to fuse multimodal contextual features in a conversation. The module reduces redundancy and enhances complementarity between modalities by capturing the dynamics of contextual information in different semantic spaces. Extensive experiments on two public benchmark datasets demonstrate the effectiveness and superiority of MM-DFN.