 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Attention Module for Natural Language Processing
Paper and Code
Sep 07, 2021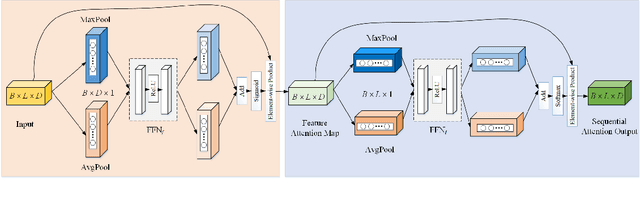


Recently, large pre-trained neural language models have attained remarkable performance on many downstream natural language processing (NLP) applications via fine-tuning. In this paper, we target at how to further improve the token representations on the language models. We, therefore, propose a simple yet effective plug-and-play module, Sequential Attention Module (SAM), on the token embeddings learned from a pre-trained language model. Our proposed SAM consists of two main attention modules deployed sequentially: Feature-wise Attention Module (FAM) and Token-wise Attention Module (TAM). More specifically, FAM can effectively identify the importance of features at each dimension and promote the effect via dot-product on the original token embeddings for downstream NLP applications. Meanwhile, TAM can further re-weight the features at the token-wise level. Moreover, we propose an adaptive filter on FAM to prevent noise impact and increase information absorption. Finally, we conduct extensive experiments to demonstrate the advantages and properties of our proposed SAM. We first show how SAM plays a primary role in the champion solution of two subtasks of SemEval'21 Task 7. After that, we apply SAM on sentiment analysis and three popular NLP tasks and demonstrate that SAM consistently outperforms the state-of-the-art baselines.