 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReEx-SQL: Reasoning with Execution-Aware Reinforcement Learning for Text-to-SQL
May 19, 2025In Text-to-SQL, execution feedback is essential for guiding large language models (LLMs) to reason accurately and generate reliable SQL queries. However, existing methods treat execution feedback solely as a post-hoc signal for correction or selection, failing to integrate it into the generation process. This limitation hinders their ability to address reasoning errors as they occur, ultimately reducing query accuracy and robustness. To address this issue, we propose ReEx-SQL (Reasoning with Execution-Aware Reinforcement Learning), a framework for Text-to-SQL that enables models to interact with the database during decoding and dynamically adjust their reasoning based on execution feedback. ReEx-SQL introduces an execution-aware reasoning paradigm that interleaves intermediate SQL execution into reasoning paths, facilitating context-sensitive revisions. It achieves this through structured prompts with markup tags and a stepwise rollout strategy that integrates execution feedback into each stage of generation. To supervise policy learning, we develop a composite reward function that includes an exploration reward, explicitly encouraging effective database interaction. Additionally, ReEx-SQL adopts a tree-based decoding strategy to support exploratory reasoning, enabling dynamic expansion of alternative reasoning paths. Notably, ReEx-SQL achieves 88.8% on Spider and 64.9% on BIRD at the 7B scale, surpassing the standard reasoning baseline by 2.7% and 2.6%, respectively. It also shows robustness, achieving 85.2% on Spider-Realistic with leading performance. In addition, its tree-structured decoding improves efficiency and performance over linear decoding, reducing inference time by 51.9% on the BIRD development set.
Dissecting Fine-Tuning Unlearning in Large Language Models
Oct 09, 2024

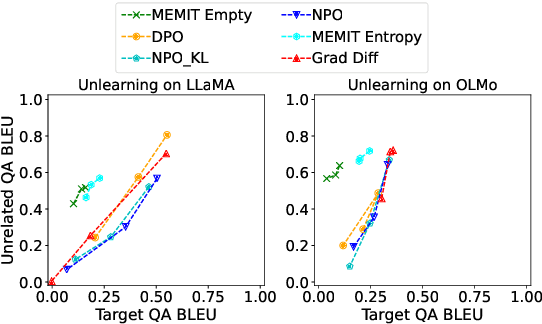

Fine-tuning-based unlearning methods prevail for preventing targeted harmful, sensitive, or copyrighted information within large language models while preserving overall capabilities. However, the true effectiveness of these methods is unclear. In this paper, we delve into the limitations of fine-tuning-based unlearning through activation patching and parameter restoration experiments. Our findings reveal that these methods alter the model's knowledge retrieval process, rather than genuinely erasing the problematic knowledge embedded in the model parameters. Furthermore, behavioral tests demonstrate that the unlearning mechanisms inevitably impact the global behavior of the models, affecting unrelated knowledge or capabilities. Our work advocates the development of more resilient unlearning techniques for truly erasing knowledge. Our code is released at https://github.com/yihuaihong/Dissecting-FT-Unlearning.
EasyECR: A Library for Easy Implementation and Evaluation of Event Coreference Resolution Models
Jun 20, 2024



Event Coreference Resolution (ECR) is the task of clustering event mentions that refer to the same real-world event. Despite significant advancements, ECR research faces two main challenges: limited generalizability across domains due to narrow dataset evaluations, and difficulties in comparing models within diverse ECR pipelines. To address these issues, we develop EasyECR, the first open-source library designed to standardize data structures and abstract ECR pipelines for easy implementation and fair evaluation. More specifically, EasyECR integrates seven representative pipelines and ten popular benchmark datasets, enabling model evaluations on various datasets and promoting the development of robust ECR pipelines. By conducting extensive evaluation via our EasyECR, we find that, \lowercase\expandafter{\romannumeral1}) the representative ECR pipelines cannot generalize across multiple datasets, hence evaluating ECR pipelines on multiple datasets is necessary, \lowercase\expandafter{\romannumeral2}) all models in ECR pipelines have a great effect on pipeline performance, therefore, when one model in ECR pipelines are compared, it is essential to ensure that the other models remain consistent. Additionally, reproducing ECR results is not trivial, and the developed library can help reduce this discrepancy. The experimental results provide valuable baselines for future research.
Intrinsic Evaluation of Unlearning Using Parametric Knowledge Traces
Jun 17, 2024

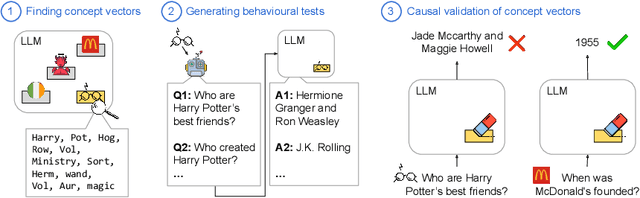

The task of "unlearning" certain concepts in large language models (LLMs) has attracted immense attention recently, due to its importance for mitigating undesirable model behaviours, such as the generation of harmful, private, or incorrect information. Current protocols to evaluate unlearning methods largely rely on behavioral tests, without monitoring the presence of unlearned knowledge within the model's parameters. This residual knowledge can be adversarially exploited to recover the erased information post-unlearning. We argue that unlearning should also be evaluated internally, by considering changes in the parametric knowledge traces of the unlearned concepts. To this end, we propose a general methodology for eliciting directions in the parameter space (termed "concept vectors") that encode concrete concepts, and construct ConceptVectors, a benchmark dataset containing hundreds of common concepts and their parametric knowledge traces within two open-source LLMs. Evaluation on ConceptVectors shows that existing unlearning methods minimally impact concept vectors, while directly ablating these vectors demonstrably removes the associated knowledge from the LLMs and significantly reduces their susceptibility to adversarial manipulation. Our results highlight limitations in behavioral-based unlearning evaluations and call for future work to include parametric-based evaluations. To support this, we release our code and benchmark at https://github.com/yihuaihong/ConceptVectors.
An Empirical Study of Benchmarking Chinese Aspect Sentiment Quad Prediction
Nov 03, 2023
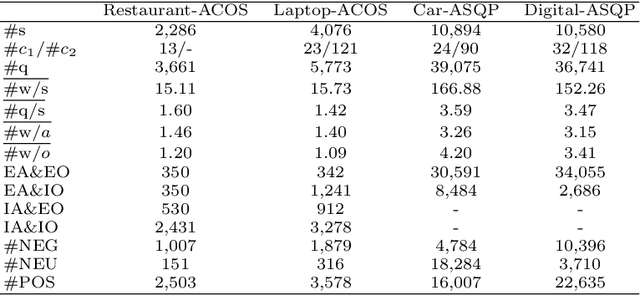


Aspect sentiment quad prediction (ASQP) is a critical subtask of aspect-level sentiment analysis. Current ASQP datasets are characterized by their small size and low quadruple density, which hinders technical development. To expand capacity, we construct two large Chinese ASQP datasets crawled from multiple online platforms. The datasets hold several significant characteristics: larger size (each with 10,000+ samples) and rich aspect categories, more words per sentence, and higher density than existing ASQP datasets. Moreover, we are the first to evaluate the performance of Generative Pre-trained Transformer (GPT) series models on ASQP and exhibit potential issues. The experiments with state-of-the-art ASQP baselines underscore the need to explore additional techniques to address ASQP, as well as the importance of further investigation into methods to improve the performance of GPTs.
Natural Language Interfaces for Tabular Data Querying and Visualization: A Survey
Oct 27, 2023



The emergence of natural language processing has revolutionized the way users interact with tabular data, enabling a shift from traditional query languages and manual plotting to more intuitive, language-based interfaces. The rise of large language models (LLMs) such as ChatGPT and its successors has further advanced this field, opening new avenues for natural language processing techniques. This survey presents a comprehensive overview of natural language interfaces for tabular data querying and visualization, which allow users to interact with data using natural language queries. We introduce the fundamental concepts and techniques underlying these interfaces with a particular emphasis on semantic parsing, the key technology facilitating the translation from natural language to SQL queries or data visualization commands. We then delve into the recent advancements in Text-to-SQL and Text-to-Vis problems from the perspectives of datasets, methodologies, metrics, and system designs. This includes a deep dive into the influence of LLMs, highlighting their strengths, limitations, and potential for future improvements. Through this survey, we aim to provide a roadmap for researchers and practitioners interested in developing and applying natural language interfaces for data interaction in the era of large language models.
D2Match: Leveraging Deep Learning and Degeneracy for Subgraph Matching
Jun 10, 2023



Subgraph matching is a fundamental building block for graph-based applications and is challenging due to its high-order combinatorial nature. Existing studies usually tackle it by combinatorial optimization or learning-based methods. However, they suffer from exponential computational costs or searching the matching without theoretical guarantees. In this paper, we develop D2Match by leveraging the efficiency of Deep learning and Degeneracy for subgraph matching. More specifically, we first prove that subgraph matching can degenerate to subtree matching, and subsequently is equivalent to finding a perfect matching on a bipartite graph. We can then yield an implementation of linear time complexity by the built-in tree-structured aggregation mechanism on graph neural networks. Moreover, circle structures and node attributes can be easily incorporated in D2Match to boost the matching performance. Finally, we conduct extensive experiments to show the superior performance of our D2Match and confirm that our D2Match indeed exploits the subtrees and differs from existing GNNs-based subgraph matching methods that depend on memorizing the data distribution divergence
A Unified One-Step Solution for Aspect Sentiment Quad Prediction
Jun 07, 2023



Aspect sentiment quad prediction (ASQP) is a challenging yet significant subtask in aspect-based sentiment analysis as it provides a complete aspect-level sentiment structure. However, existing ASQP datasets are usually small and low-density, hindering technical advancement. To expand the capacity, in this paper, we release two new datasets for ASQP, which contain the following characteristics: larger size, more words per sample, and higher density. With such datasets, we unveil the shortcomings of existing strong ASQP baselines and therefore propose a unified one-step solution for ASQP, namely One-ASQP, to detect the aspect categories and to identify the aspect-opinion-sentiment (AOS) triplets simultaneously. Our One-ASQP holds several unique advantages: (1) by separating ASQP into two subtasks and solving them independently and simultaneously, we can avoid error propagation in pipeline-based methods and overcome slow training and inference in generation-based methods; (2) by introducing sentiment-specific horns tagging schema in a token-pair-based two-dimensional matrix, we can exploit deeper interactions between sentiment elements and efficiently decode the AOS triplets; (3) we design ``[NULL]'' token can help us effectively identify the implicit aspects or opinions. Experiments on two benchmark datasets and our released two datasets demonstrate the advantages of our One-ASQP. The two new datasets are publicly released at \url{https://www.github.com/Datastory-CN/ASQP-Datasets}.
A Diffusion Model for Event Skeleton Generation
May 27, 2023



Event skeleton generation, aiming to induce an event schema skeleton graph with abstracted event nodes and their temporal relations from a set of event instance graphs, is a critical step in the temporal complex event schema induction task. Existing methods effectively address this task from a graph generation perspective but suffer from noise-sensitive and error accumulation, e.g., the inability to correct errors while generating schema. We, therefore, propose a novel Diffusion Event Graph Model~(DEGM) to address these issues. Our DEGM is the first workable diffusion model for event skeleton generation, where the embedding and rounding techniques with a custom edge-based loss are introduced to transform a discrete event graph into learnable latent representation. Furthermore, we propose a denoising training process to maintain the model's robustness. Consequently, DEGM derives the final schema, where error correction is guaranteed by iteratively refining the latent representation during the schema generation process. Experimental results on three IED bombing datasets demonstrate that our DEGM achieves better results than other state-of-the-art baselines. Our code and data are available at https://github.com/zhufq00/EventSkeletonGeneration.
Towards Effective Collaborative Learning in Long-Tailed Recognition
May 05, 2023



Real-world data usually suffers from severe class imbalance and long-tailed distributions, where minority classes are significantly underrepresented compared to the majority ones. Recent research prefers to utilize multi-expert architectures to mitigate the model uncertainty on the minority, where collaborative learning is employed to aggregate the knowledge of experts, i.e., online distillation. In this paper, we observe that the knowledge transfer between experts is imbalanced in terms of class distribution, which results in limited performance improvement of the minority classes. To address it, we propose a re-weighted distillation loss by comparing two classifiers' predictions, which are supervised by online distillation and label annotations, respectively. We also emphasize that feature-level distillation will significantly improve model performance and increase feature robustness. Finally, we propose an Effective Collaborative Learning (ECL) framework that integrates a contrastive proxy task branch to further improve feature quality. Quantitative and qualitative experiments on four standard datasets demonstrate that ECL achieves state-of-the-art performance and the detailed ablation studies manifest the effectiveness of each component in ECL.