 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARLA-Round: A Multi-Factor Simulation Dataset for Roundabout Trajectory Prediction
Jan 17, 2026Accurate trajectory prediction of vehicles at roundabouts is critical for reducing traffic accidents, yet it remains highly challenging due to their circular road geometry, continuous merging and yielding interactions, and absence of traffic signals. Developing accurate prediction algorithms relies on reliable, multimodal, and realistic datasets; however, such datasets for roundabout scenarios are scarce, as real-world data collection is often limited by incomplete observations and entangled factors that are difficult to isolate. We present CARLA-Round, a systematically designed simulation dataset for roundabout trajectory prediction. The dataset varies weather conditions (five types) and traffic density levels (spanning Level-of-Service A-E) in a structured manner, resulting in 25 controlled scenarios. Each scenario incorporates realistic mixtures of driving behaviors and provides explicit annotations that are largely absent from existing datasets. Unlike randomly sampled simulation data, this structured design enables precise analysis of how different conditions influence trajectory prediction performance. Validation experiments using standard baselines (LSTM, GCN, GRU+GCN) reveal traffic density dominates prediction difficulty with strong monotonic effects, while weather shows non-linear impacts. The best model achieves 0.312m ADE on real-world rounD dataset, demonstrating effective sim-to-real transfer. This systematic approach quantifies factor impacts impossible to isolate in confounded real-world datasets. Our CARLA-Round dataset is available at https://github.com/Rebecca689/CARLA-Round.
Evolving Excellence: Automated Optimization of LLM-based Agents
Dec 09, 2025Agentic AI systems built on large language models (LLMs) offer significant potential for automating complex workflows, from software development to customer support. However, LLM agents often underperform due to suboptimal configurations; poorly tuned prompts, tool descriptions, and parameters that typically require weeks of manual refinement. Existing optimization methods either are too complex for general use or treat components in isolation, missing critical interdependencies. We present ARTEMIS, a no-code evolutionary optimization platform that jointly optimizes agent configurations through semantically-aware genetic operators. Given only a benchmark script and natural language goals, ARTEMIS automatically discovers configurable components, extracts performance signals from execution logs, and evolves configurations without requiring architectural modifications. We evaluate ARTEMIS on four representative agent systems: the \emph{ALE Agent} for competitive programming on AtCoder Heuristic Contest, achieving a \textbf{$13.6\%$ improvement} in acceptance rate; the \emph{Mini-SWE Agent} for code optimization on SWE-Perf, with a statistically significant \textbf{10.1\% performance gain}; and the \emph{CrewAI Agent} for cost and mathematical reasoning on Math Odyssey, achieving a statistically significant \textbf{$36.9\%$ reduction} in the number of tokens required for evaluation. We also evaluate the \emph{MathTales-Teacher Agent} powered by a smaller open-source model (Qwen2.5-7B) on GSM8K primary-level mathematics problems, achieving a \textbf{22\% accuracy improvement} and demonstrating that ARTEMIS can optimize agents based on both commercial and local models.
EasyECR: A Library for Easy Implementation and Evaluation of Event Coreference Resolution Models
Jun 20, 2024



Event Coreference Resolution (ECR) is the task of clustering event mentions that refer to the same real-world event. Despite significant advancements, ECR research faces two main challenges: limited generalizability across domains due to narrow dataset evaluations, and difficulties in comparing models within diverse ECR pipelines. To address these issues, we develop EasyECR, the first open-source library designed to standardize data structures and abstract ECR pipelines for easy implementation and fair evaluation. More specifically, EasyECR integrates seven representative pipelines and ten popular benchmark datasets, enabling model evaluations on various datasets and promoting the development of robust ECR pipelines. By conducting extensive evaluation via our EasyECR, we find that, \lowercase\expandafter{\romannumeral1}) the representative ECR pipelines cannot generalize across multiple datasets, hence evaluating ECR pipelines on multiple datasets is necessary, \lowercase\expandafter{\romannumeral2}) all models in ECR pipelines have a great effect on pipeline performance, therefore, when one model in ECR pipelines are compared, it is essential to ensure that the other models remain consistent. Additionally, reproducing ECR results is not trivial, and the developed library can help reduce this discrepancy. The experimental results provide valuable baselines for future research.
A Low-Cost Multi-Band Waveform Security Framework in Resource-Constrained Communications
Feb 01, 2024Traditional physical layer secure beamforming is achieved via precoding before signal transmission using channel state information (CSI). However, imperfect CSI will compromise the performance with imperfect beamforming and potential information leakage. In addition, multiple RF chains and antennas are needed to support the narrow beam generation, which complicates hardware implementation and is not suitable for resource-constrained Internet-of-Things (IoT) devices. Moreover, with the advancement of hardware and artificial intelligence (AI), low-cost and intelligent eavesdropping to wireless communications is becoming increasingly detrimental. In this paper, we propose a multi-carrier based multi-band waveform-defined security (WDS) framework, independent from CSI and RF chains, to defend against AI eavesdropping. Ideally, the continuous variations of sub-band structures lead to an infinite number of spectral features, which can potentially prevent brute-force eavesdropping. Sub-band spectral pattern information is efficiently constructed at legitimate users via a proposed chaotic sequence generator. A novel security metric, termed signal classification accuracy (SCA), is used to evaluate the security robustness under AI eavesdropping. Communication error probability and complexity are also investigated to show the reliability and practical capability of the proposed framework. Finally, compared to traditional secure beamforming techniques, the proposed multi-band WDS framework reduces power consumption by up to six times.
Data Augmentation for Time-Series Classification: An Extensive Empirical Study and Comprehensive Survey
Oct 19, 2023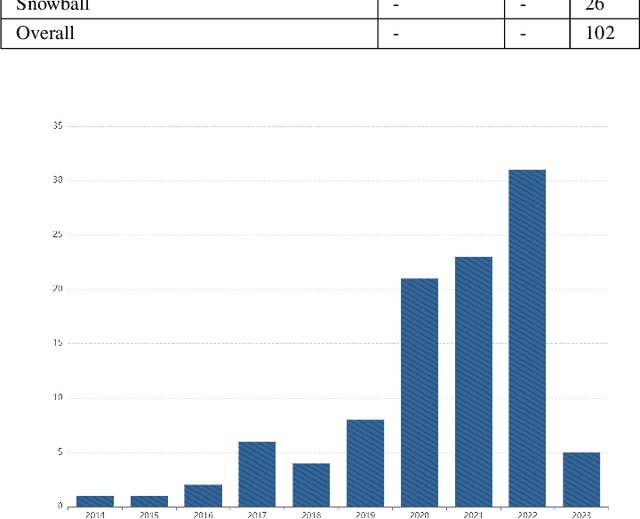
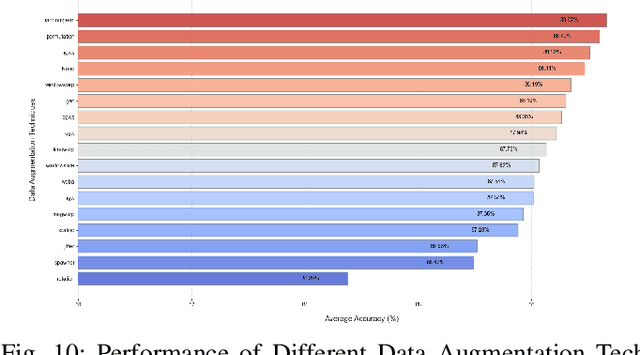
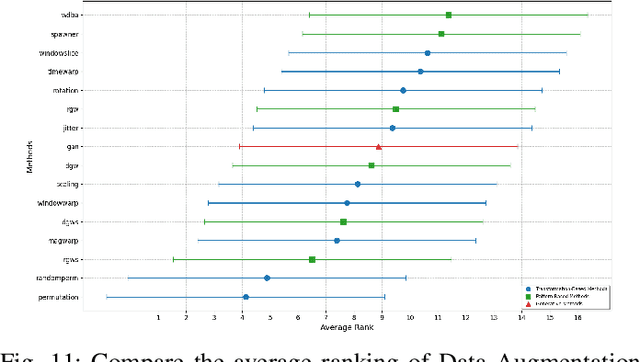
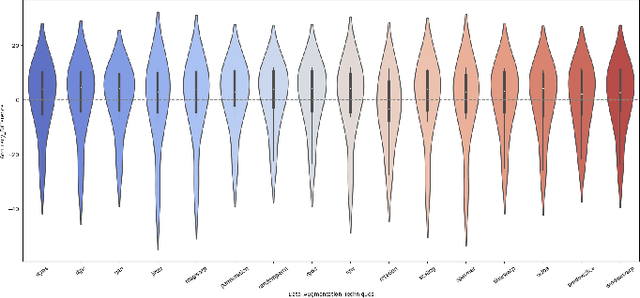
Data Augmentation (DA) has emerged as an indispensable strategy in Time Series Classification (TSC), primarily due to its capacity to amplify training samples, thereby bolstering model robustness, diversifying datasets, and curtailing overfitting. However, the current landscape of DA in TSC is plagued with fragmented literature reviews, nebulous methodological taxonomies, inadequate evaluative measures, and a dearth of accessible, user-oriented tools. In light of these challenges, this study embarks on an exhaustive dissection of DA methodologies within the TSC realm. Our initial approach involved an extensive literature review spanning a decade, revealing that contemporary surveys scarcely capture the breadth of advancements in DA for TSC, prompting us to meticulously analyze over 100 scholarly articles to distill more than 60 unique DA techniques. This rigorous analysis precipitated the formulation of a novel taxonomy, purpose-built for the intricacies of DA in TSC, categorizing techniques into five principal echelons: Transformation-Based, Pattern-Based, Generative, Decomposition-Based, and Automated Data Augmentation. Our taxonomy promises to serve as a robust navigational aid for scholars, offering clarity and direction in method selection. Addressing the conspicuous absence of holistic evaluations for prevalent DA techniques, we executed an all-encompassing empirical assessment, wherein upwards of 15 DA strategies were subjected to scrutiny across 8 UCR time-series datasets, employing ResNet and a multi-faceted evaluation paradigm encompassing Accuracy, Method Ranking, and Residual Analysis, yielding a benchmark accuracy of 88.94 +- 11.83%. Our investigation underscored the inconsistent efficacies of DA techniques, with...