 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasyECR: A Library for Easy Implementation and Evaluation of Event Coreference Resolution Models
Jun 20, 2024



Event Coreference Resolution (ECR) is the task of clustering event mentions that refer to the same real-world event. Despite significant advancements, ECR research faces two main challenges: limited generalizability across domains due to narrow dataset evaluations, and difficulties in comparing models within diverse ECR pipelines. To address these issues, we develop EasyECR, the first open-source library designed to standardize data structures and abstract ECR pipelines for easy implementation and fair evaluation. More specifically, EasyECR integrates seven representative pipelines and ten popular benchmark datasets, enabling model evaluations on various datasets and promoting the development of robust ECR pipelines. By conducting extensive evaluation via our EasyECR, we find that, \lowercase\expandafter{\romannumeral1}) the representative ECR pipelines cannot generalize across multiple datasets, hence evaluating ECR pipelines on multiple datasets is necessary, \lowercase\expandafter{\romannumeral2}) all models in ECR pipelines have a great effect on pipeline performance, therefore, when one model in ECR pipelines are compared, it is essential to ensure that the other models remain consistent. Additionally, reproducing ECR results is not trivial, and the developed library can help reduce this discrepancy. The experimental results provide valuable baselines for future research.
Next-Generation Full Duplex Networking System Empowered by Reconfigurable Intelligent Surfaces
May 02, 2023Full duplex (FD) radio has attracted extensive attention due to its co-time and co-frequency transceiving capability. {However, the potential gain brought by FD radios is closely related to the management of self-interference (SI), which imposes high or even stringent requirements on SI cancellation (SIC) techniques. When the FD deployment evolves into next-generation mobile networking, the SI problem becomes more complicated, significantly limiting its potential gains.} In this paper, we conceive a multi-cell FD networking scheme by deploying a reconfigurable intelligent surface (RIS) at the cell boundary to configure the radio environment proactively. To achieve the full potential of the system, we aim to maximize the sum rate (SR) of multiple cells by jointly optimizing the transmit precoding (TPC) matrices at FD base stations (BSs) and users and the phase shift matrix at RIS. Since the original problem is non-convex, we reformulate and decouple it into a pair of subproblems by utilizing the relationship between the SR and minimum mean square error (MMSE). The optimal solutions of TPC matrices are obtained in closed form, while both complex circle manifold (CCM) and successive convex approximation (SCA) based algorithms are developed to resolve the phase shift matrix suboptimally. Our simulation results show that introducing an RIS into an FD networking system not only improves the overall SR significantly but also enhances the cell edge performance prominently. More importantly, we validate that the RIS deployment with optimized phase shifts can reduce the requirement for SIC and the number of BS antennas, which further reduces the hardware cost and power consumption, especially with a sufficient number of reflecting elements. As a result, the utilization of an RIS enables the originally cumbersome FD networking system to become efficient and practical.
A Better Choice: Entire-space Datasets for Aspect Sentiment Triplet Extraction
Dec 18, 2022



Aspect sentiment triplet extraction (ASTE) aims to extract aspect term, sentiment and opinion term triplets from sentences. Since the initial datasets used to evaluate models on ASTE had flaws, several studies later corrected the initial datasets and released new versions of the datasets independently. As a result, different studies select different versions of datasets to evaluate their methods, which makes ASTE-related works hard to follow. In this paper, we analyze the relation between different versions of datasets and suggest that the entire-space version should be used for ASTE. Besides the sentences containing triplets and the triplets in the sentences, the entire-space version additionally includes the sentences without triplets and the aspect terms which do not belong to any triplets. Hence, the entire-space version is consistent with real-world scenarios and evaluating models on the entire-space version can better reflect the models' performance in real-world scenarios. In addition, experimental results show that evaluating models on non-entire-space datasets inflates the performance of existing models and models trained on the entire-space version can obtain better performance.
Modeling User Repeat Consumption Behavior for Online Novel Recommendation
Sep 05, 2022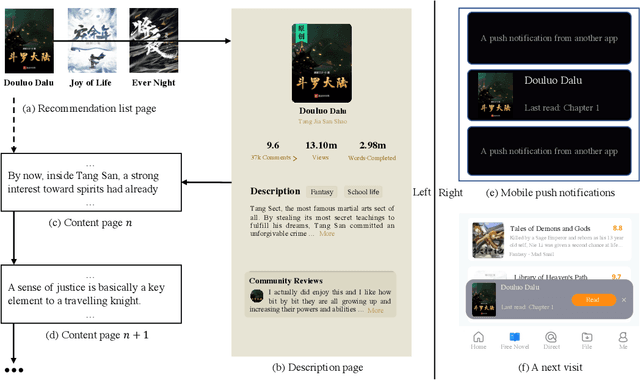

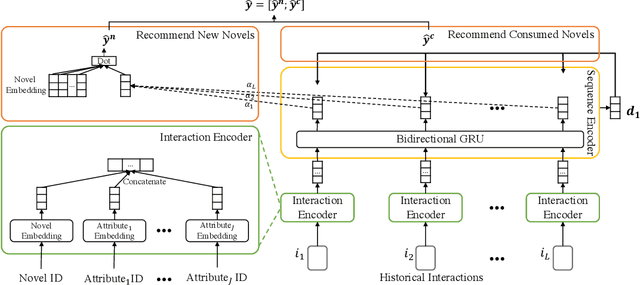
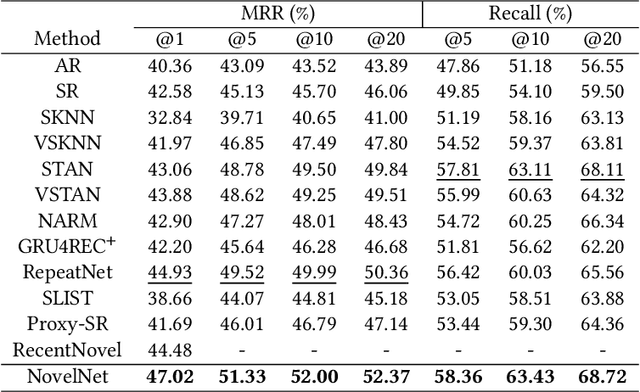
Given a user's historical interaction sequence, online novel recommendation suggests the next novel the user may be interested in. Online novel recommendation is important but underexplored. In this paper, we concentrate on recommending online novels to new users of an online novel reading platform, whose first visits to the platform occurred in the last seven days. We have two observations about online novel recommendation for new users. First, repeat novel consumption of new users is a common phenomenon. Second, interactions between users and novels are informative. To accurately predict whether a user will reconsume a novel, it is crucial to characterize each interaction at a fine-grained level. Based on these two observations, we propose a neural network for online novel recommendation, called NovelNet. NovelNet can recommend the next novel from both the user's consumed novels and new novels simultaneously. Specifically, an interaction encoder is used to obtain accurate interaction representation considering fine-grained attributes of interaction, and a pointer network with a pointwise loss is incorporated into NovelNet to recommend previously-consumed novels. Moreover, an online novel recommendation dataset is built from a well-known online novel reading platform and is released for public use as a benchmark. Experimental results on the dataset demonstrate the effectiveness of NovelNet.
Training Entire-Space Models for Target-oriented Opinion Words Extraction
Apr 15, 2022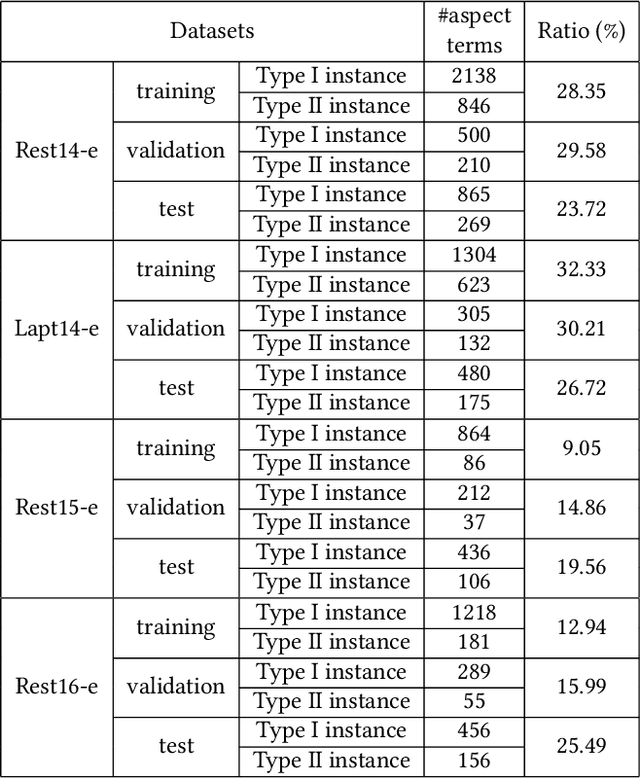
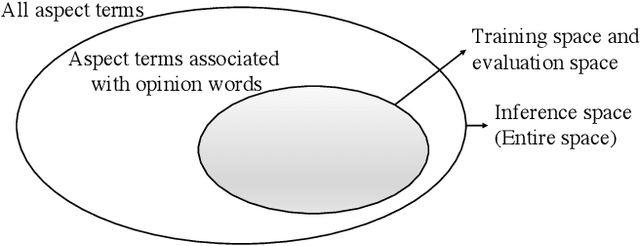
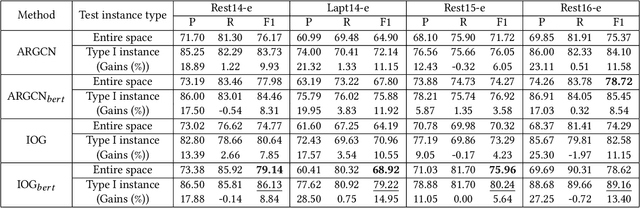
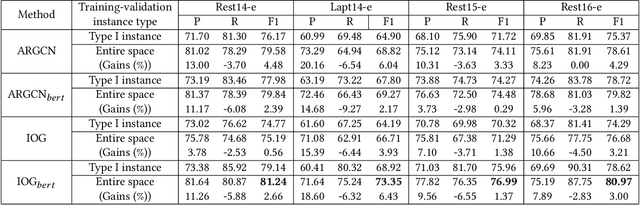
Target-oriented opinion words extraction (TOWE) is a subtask of aspect-based sentiment analysis (ABSA). Given a sentence and an aspect term occurring in the sentence, TOWE extracts the corresponding opinion words for the aspect term. TOWE has two types of instance. In the first type, aspect terms are associated with at least one opinion word, while in the second type, aspect terms do not have corresponding opinion words. However, previous researches trained and evaluated their models with only the first type of instance, resulting in a sample selection bias problem. Specifically, TOWE models were trained with only the first type of instance, while these models would be utilized to make inference on the entire space with both the first type of instance and the second type of instance. Thus, the generalization performance will be hurt. Moreover, the performance of these models on the first type of instance cannot reflect their performance on entire space. To validate the sample selection bias problem, four popular TOWE datasets containing only aspect terms associated with at least one opinion word are extended and additionally include aspect terms without corresponding opinion words. Experimental results on these datasets show that training TOWE models on entire space will significantly improve model performance and evaluating TOWE models only on the first type of instance will overestimate model performance.
Aspect-Sentiment-Multiple-Opinion Triplet Extraction
Oct 14, 2021
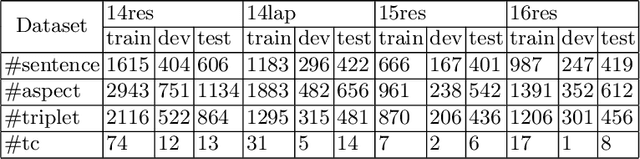
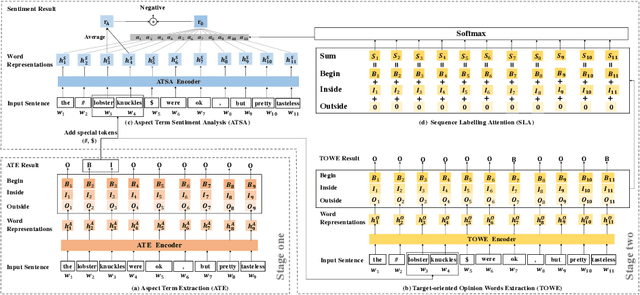
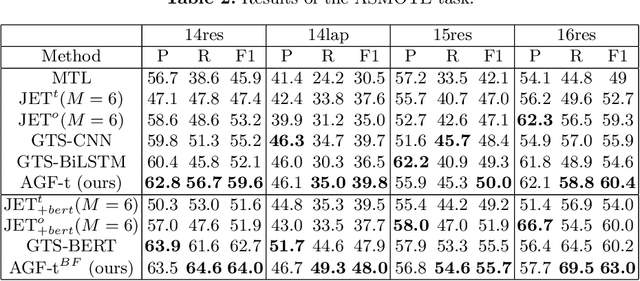
Aspect Sentiment Triplet Extraction (ASTE) aims to extract aspect term (aspect), sentiment and opinion term (opinion) triplets from sentences and can tell a complete story, i.e., the discussed aspect, the sentiment toward the aspect, and the cause of the sentiment. ASTE is a charming task, however, one triplet extracted by ASTE only includes one opinion of the aspect, but an aspect in a sentence may have multiple corresponding opinions and one opinion only provides part of the reason why the aspect has this sentiment, as a consequence, some triplets extracted by ASTE are hard to understand, and provide erroneous information for downstream tasks. In this paper, we introduce a new task, named Aspect Sentiment Multiple Opinions Triplet Extraction (ASMOTE). ASMOTE aims to extract aspect, sentiment and multiple opinions triplets. Specifically, one triplet extracted by ASMOTE contains all opinions about the aspect and can tell the exact reason that the aspect has the sentiment. We propose an Aspect-Guided Framework (AGF) to address this task. AGF first extracts aspects, then predicts their opinions and sentiments. Moreover, with the help of the proposed Sequence Labeling Attention(SLA), AGF improves the performance of the sentiment classification using the extracted opinions. Experimental results on multiple datasets demonstrate the effectiveness of our approach.
A More Fine-Grained Aspect-Sentiment-Opinion Triplet Extraction Task
Apr 16, 2021
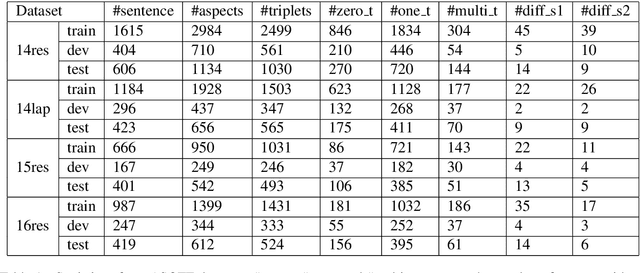
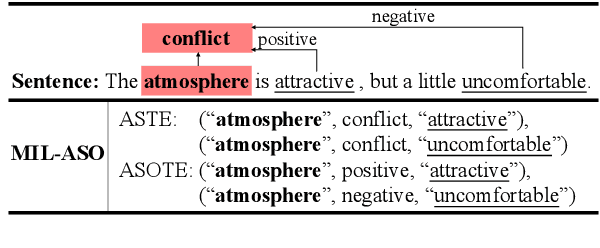
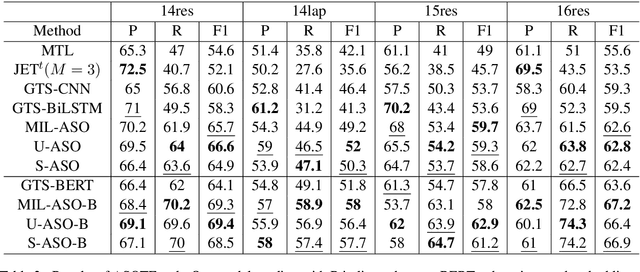
Aspect Sentiment Triplet Extraction (ASTE) aims to extract aspect term, sentiment and opinion term triplets from sentences and tries to provide a complete solution for aspect-based sentiment analysis (ABSA). However, some triplets extracted by ASTE are confusing, since the sentiment in a triplet extracted by ASTE is the sentiment that the sentence expresses toward the aspect term rather than the sentiment of the aspect term and opinion term pair. In this paper, we introduce a more fine-grained Aspect-Sentiment-Opinion Triplet Extraction (ASOTE) Task. ASOTE also extracts aspect term, sentiment and opinion term triplets. However, the sentiment in a triplet extracted by ASOTE is the sentiment of the aspect term and opinion term pair. We build four datasets for ASOTE based on several popular ABSA benchmarks. We propose two methods for ASOTE. The first method extracts the opinion terms of an aspect term and predicts the sentiments of the aspect term and opinion term pairs jointly with a unified tag schema. The second method is based on multiple instance learning, which is trained on ASTE datasets, but can also perform the ASOTE task. Experimental results on the four datasets demonstrate the effectiveness of our methods.
Multi-Instance Multi-Label Learning Networks for Aspect-Category Sentiment Analysis
Oct 06, 2020
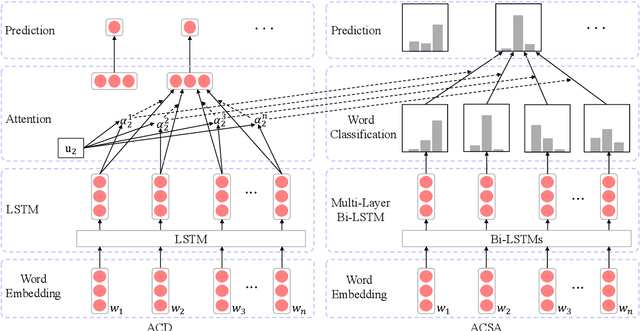
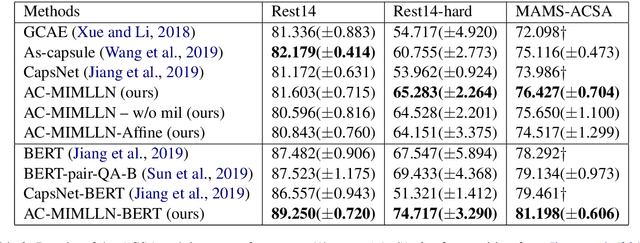
Aspect-category sentiment analysis (ACSA) aims to predict sentiment polarities of sentences with respect to given aspect categories. To detect the sentiment toward a particular aspect category in a sentence, most previous methods first generate an aspect category-specific sentence representation for the aspect category, then predict the sentiment polarity based on the representation. These methods ignore the fact that the sentiment of an aspect category mentioned in a sentence is an aggregation of the sentiments of the words indicating the aspect category in the sentence, which leads to suboptimal performance. In this paper, we propose a Multi-Instance Multi-Label Learning Network for Aspect-Category sentiment analysis (AC-MIMLLN), which treats sentences as bags, words as instances, and the words indicating an aspect category as the key instances of the aspect category. Given a sentence and the aspect categories mentioned in the sentence, AC-MIMLLN first predicts the sentiments of the instances, then finds the key instances for the aspect categories, finally obtains the sentiments of the sentence toward the aspect categories by aggregating the key instance sentiments. Experimental results on three public datasets demonstrate the effectiveness of AC-MIMLLN.
Sentence Constituent-Aware Aspect-Category Sentiment Analysis with Graph Attention Networks
Oct 04, 2020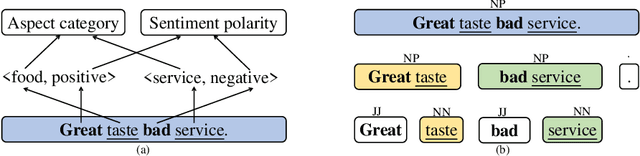
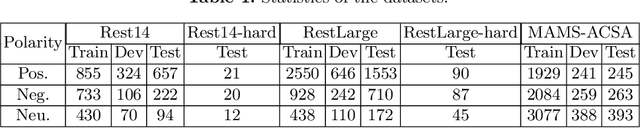
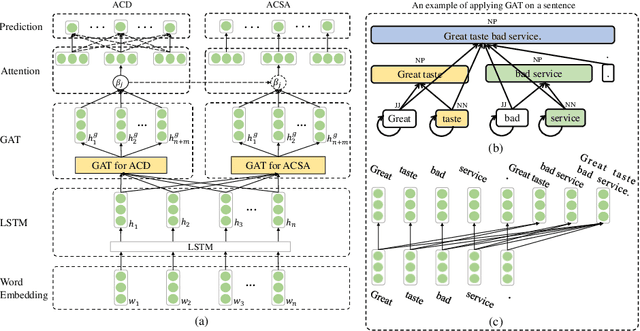
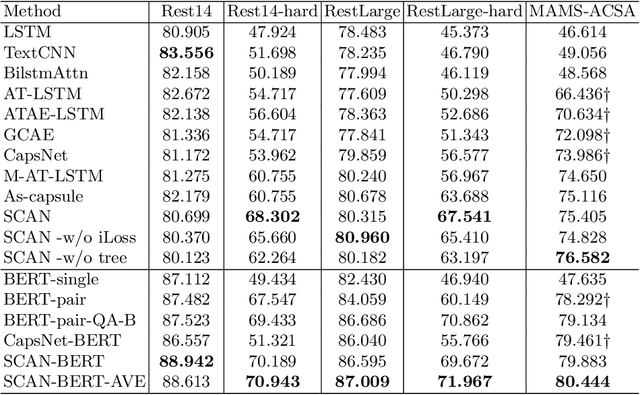
Aspect category sentiment analysis (ACSA) aims to predict the sentiment polarities of the aspect categories discussed in sentences. Since a sentence usually discusses one or more aspect categories and expresses different sentiments toward them, various attention-based methods have been developed to allocate the appropriate sentiment words for the given aspect category and obtain promising results. However, most of these methods directly use the given aspect category to find the aspect category-related sentiment words, which may cause mismatching between the sentiment words and the aspect categories when an unrelated sentiment word is semantically meaningful for the given aspect category. To mitigate this problem, we propose a Sentence Constituent-Aware Network (SCAN) for aspect-category sentiment analysis. SCAN contains two graph attention modules and an interactive loss function. The graph attention modules generate representations of the nodes in sentence constituency parse trees for the aspect category detection (ACD) task and the ACSA task, respectively. ACD aims to detect aspect categories discussed in sentences and is a auxiliary task. For a given aspect category, the interactive loss function helps the ACD task to find the nodes which can predict the aspect category but can't predict other aspect categories. The sentiment words in the nodes then are used to predict the sentiment polarity of the aspect category by the ACSA task. The experimental results on five public datasets demonstrate the effectiveness of SCAN.
A Joint Model for Aspect-Category Sentiment Analysis with Contextualized Aspect Embedding
Aug 29, 2019
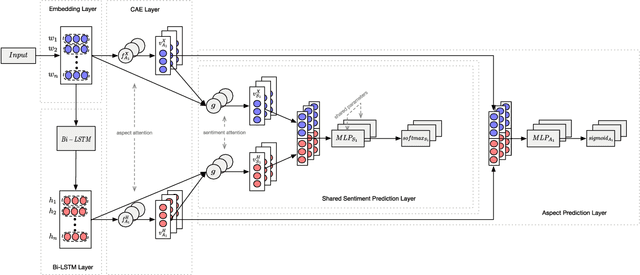


Aspect-category sentiment analysis (ACSA) aims to identify all the aspect categories mentioned in the text and their corresponding sentiment polarities. Some joint models have been proposed to address this task. However, these joint models do not solve the following two problems well: mismatching between the aspect categories and the sentiment words, and data deficiency of some aspect categories. To solve them, we propose a novel joint model which contains a contextualized aspect embedding layer and a shared sentiment prediction layer. The contextualized aspect embedding layer extracts the aspect category related information, which is used to generate aspect-specific representations for sentiment classification like traditional context-independent aspect embedding (CIAE) and is therefore called contextualized aspect embedding (CAE). The CAE can mitigate the mismatching problem because it is semantically more related to sentiment words than CIAE. The shared sentiment prediction layer transfers sentiment knowledge between aspect categories and alleviates the problem caused by data deficiency. Experiments conducted on SemEval 2016 Datasets show that our proposed model achieves state-of-the-art performance.