 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Effective EU E-Participation: The Development of AskThePublic
Apr 04, 2025E-participation platforms can be an important asset for governments in increasing trust and fostering democratic societies. By engaging non-governmental and private institutions, domain experts, and even the general public, policymakers can make informed and inclusive decisions. Drawing on the Media Richness Theory and applying the Design Science Research method, we explore how a chatbot can be designed to improve the effectiveness of the policy-making process of existing citizen involvement platforms. Leveraging the Have Your Say platform, which solicits feedback on European Commission initiatives and regulations, a Large Language Model based chatbot, called AskThePublic is created, providing policymakers, journalists, researchers, and interested citizens with a convenient channel to explore and engage with public input. By conducting 11 semistructured interviews, the results show that the participants value the interactive and structured responses as well as enhanced language capabilities, thus increasing their likelihood of engaging with AskThePublic over the existing platform. An outlook for future iterations is provided and discussed with regard to the perspectives of the different stakeholders.
Clustering and attention model based for Intelligent Trading
Jul 06, 2021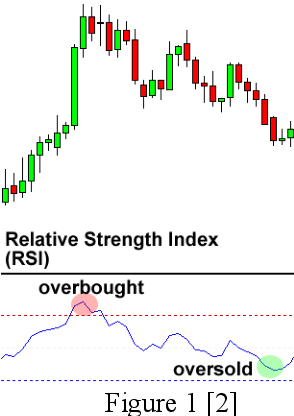



The foreign exchange market has taken an important role in the global financial market. While foreign exchange trading brings high-yield opportunities to investors, it also brings certain risks. Since the establishment of the foreign exchange market in the 20th century, foreign exchange rate forecasting has become a hot issue studied by scholars from all over the world. Due to the complexity and number of factors affecting the foreign exchange market, technical analysis cannot respond to administrative intervention or unexpected events. Our team chose several pairs of foreign currency historical data and derived technical indicators from 2005 to 2021 as the dataset and established different machine learning models for event-driven price prediction for oversold scenario.
AirRL: A Reinforcement Learning Approach to Urban Air Quality Inference
Mar 27, 2020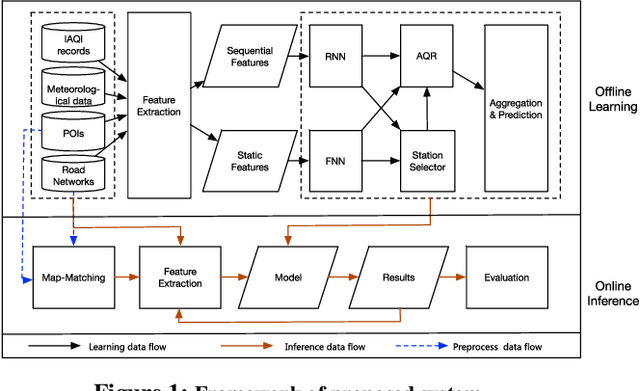
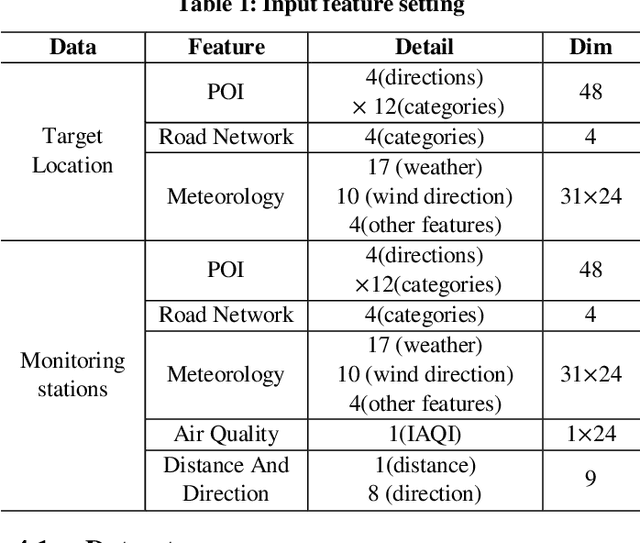
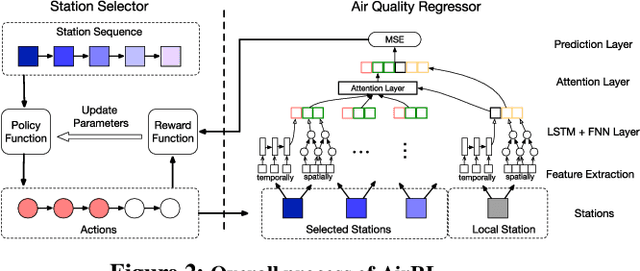
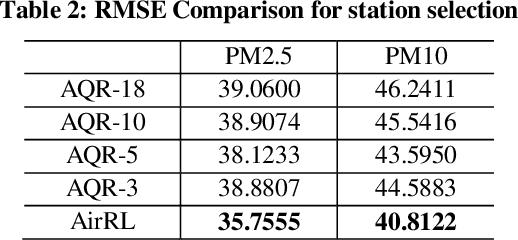
Urban air pollution has become a major environmental problem that threatens public health. It has become increasingly important to infer fine-grained urban air quality based on existing monitoring stations. One of the challenges is how to effectively select some relevant stations for air quality inference. In this paper, we propose a novel model based on reinforcement learning for urban air quality inference. The model consists of two modules: a station selector and an air quality regressor. The station selector dynamically selects the most relevant monitoring stations when inferring air quality. The air quality regressor takes in the selected stations and makes air quality inference with deep neural network. We conduct experiments on a real-world air quality dataset and our approach achieves the highest performance compared with several popular solutions, and the experiments show significant effectiveness of proposed model in tackling problems of air quality inference.
A Joint Model for Aspect-Category Sentiment Analysis with Contextualized Aspect Embedding
Aug 29, 2019
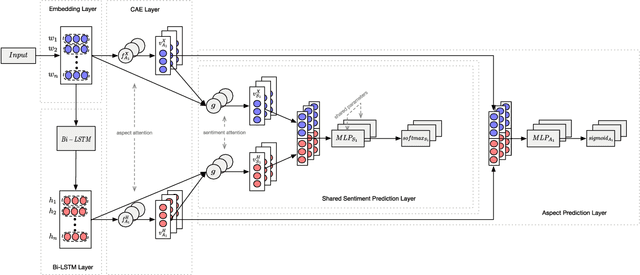


Aspect-category sentiment analysis (ACSA) aims to identify all the aspect categories mentioned in the text and their corresponding sentiment polarities. Some joint models have been proposed to address this task. However, these joint models do not solve the following two problems well: mismatching between the aspect categories and the sentiment words, and data deficiency of some aspect categories. To solve them, we propose a novel joint model which contains a contextualized aspect embedding layer and a shared sentiment prediction layer. The contextualized aspect embedding layer extracts the aspect category related information, which is used to generate aspect-specific representations for sentiment classification like traditional context-independent aspect embedding (CIAE) and is therefore called contextualized aspect embedding (CAE). The CAE can mitigate the mismatching problem because it is semantically more related to sentiment words than CIAE. The shared sentiment prediction layer transfers sentiment knowledge between aspect categories and alleviates the problem caused by data deficiency. Experiments conducted on SemEval 2016 Datasets show that our proposed model achieves state-of-the-art performance.