 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise Augmented Fine Tuning for Mitigating Hallucinations in Large Language Models
Apr 04, 2025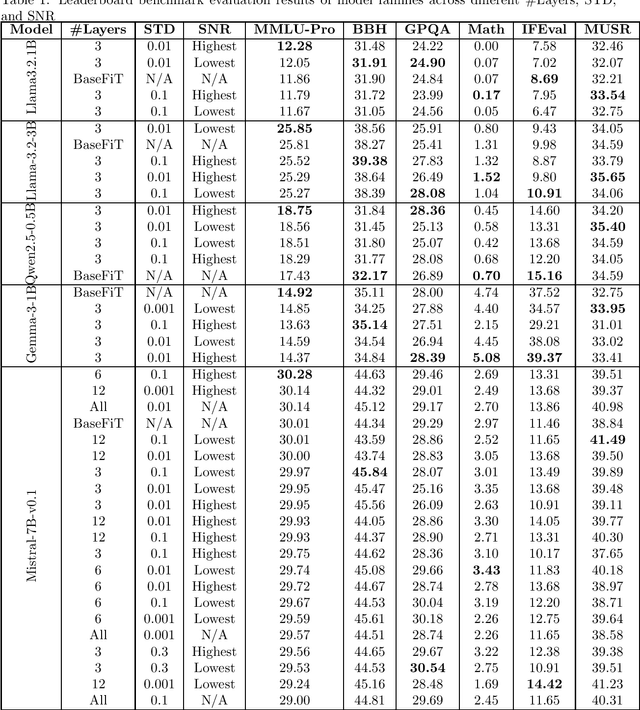
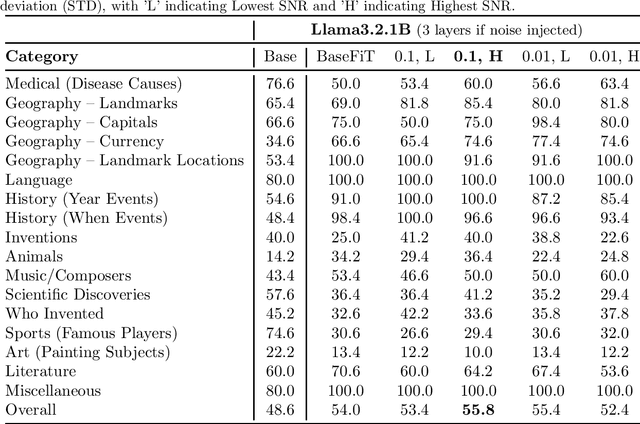
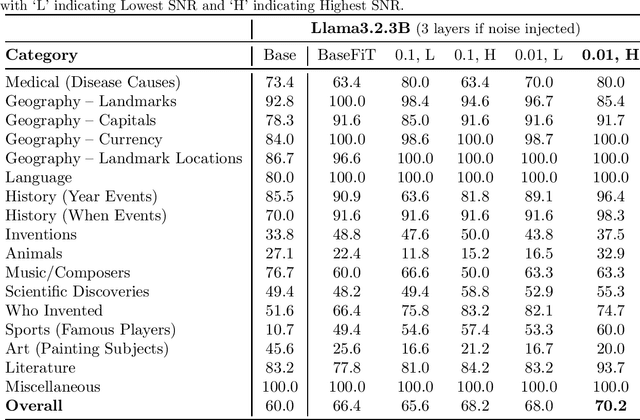
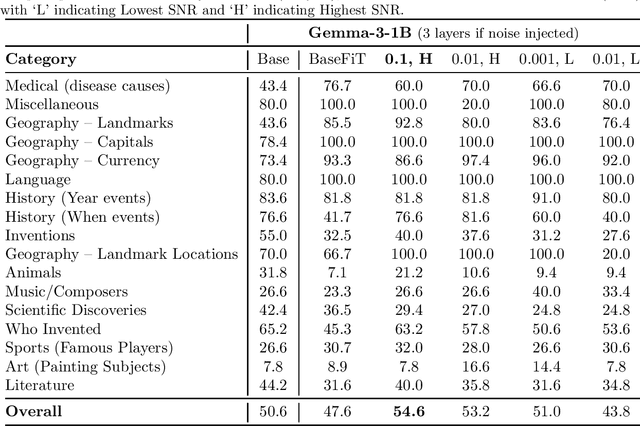
Large language models (LLMs) often produce inaccurate or misleading content-hallucinations. To address this challenge, we introduce Noise-Augmented Fine-Tuning (NoiseFiT), a novel framework that leverages adaptive noise injection based on the signal-to-noise ratio (SNR) to enhance model robustness. In particular, NoiseFiT selectively perturbs layers identified as either high-SNR (more robust) or low-SNR (potentially under-regularized) using a dynamically scaled Gaussian noise. We further propose a hybrid loss that combines standard cross-entropy, soft cross-entropy, and consistency regularization to ensure stable and accurate outputs under noisy training conditions. Our theoretical analysis shows that adaptive noise injection is both unbiased and variance-preserving, providing strong guarantees for convergence in expectation. Empirical results on multiple test and benchmark datasets demonstrate that NoiseFiT significantly reduces hallucination rates, often improving or matching baseline performance in key tasks. These findings highlight the promise of noise-driven strategies for achieving robust, trustworthy language modeling without incurring prohibitive computational overhead. Given the comprehensive and detailed nature of our experiments, we have publicly released the fine-tuning logs, benchmark evaluation artifacts, and source code online at W&B, Hugging Face, and GitHub, respectively, to foster further research, accessibility and reproducibility.
Towards Effective EU E-Participation: The Development of AskThePublic
Apr 04, 2025E-participation platforms can be an important asset for governments in increasing trust and fostering democratic societies. By engaging non-governmental and private institutions, domain experts, and even the general public, policymakers can make informed and inclusive decisions. Drawing on the Media Richness Theory and applying the Design Science Research method, we explore how a chatbot can be designed to improve the effectiveness of the policy-making process of existing citizen involvement platforms. Leveraging the Have Your Say platform, which solicits feedback on European Commission initiatives and regulations, a Large Language Model based chatbot, called AskThePublic is created, providing policymakers, journalists, researchers, and interested citizens with a convenient channel to explore and engage with public input. By conducting 11 semistructured interviews, the results show that the participants value the interactive and structured responses as well as enhanced language capabilities, thus increasing their likelihood of engaging with AskThePublic over the existing platform. An outlook for future iterations is provided and discussed with regard to the perspectives of the different stakeholders.
CognArtive: Large Language Models for Automating Art Analysis and Decoding Aesthetic Elements
Feb 04, 2025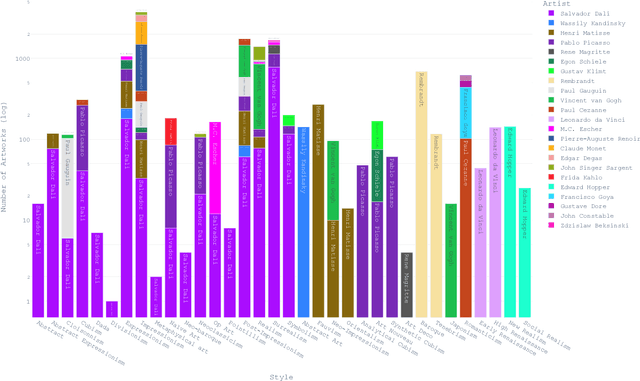
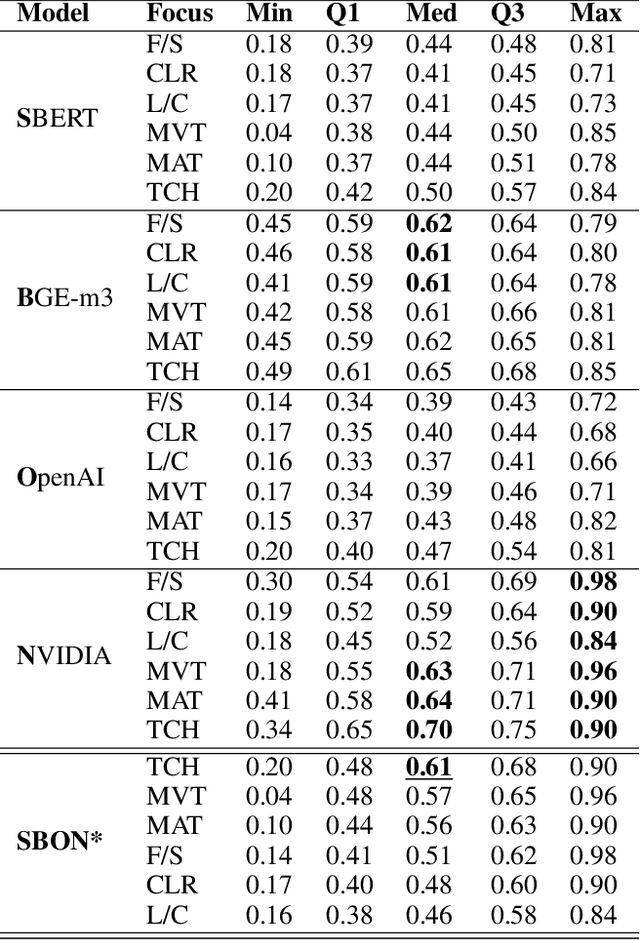
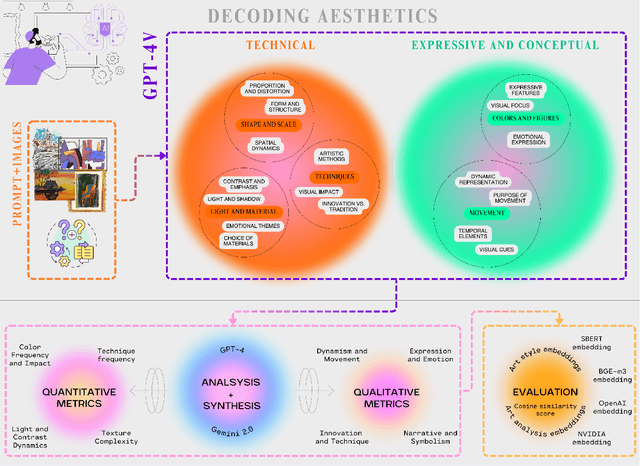

Art, as a universal language, can be interpreted in diverse ways, with artworks embodying profound meanings and nuances. The advent of Large Language Models (LLMs) and the availability of Multimodal Large Language Models (MLLMs) raise the question of how these transformative models can be used to assess and interpret the artistic elements of artworks. While research has been conducted in this domain, to the best of our knowledge, a deep and detailed understanding of the technical and expressive features of artworks using LLMs has not been explored. In this study, we investigate the automation of a formal art analysis framework to analyze a high-throughput number of artworks rapidly and examine how their patterns evolve over time. We explore how LLMs can decode artistic expressions, visual elements, composition, and techniques, revealing emerging patterns that develop across periods. Finally, we discuss the strengths and limitations of LLMs in this context, emphasizing their ability to process vast quantities of art-related data and generate insightful interpretations. Due to the exhaustive and granular nature of the results, we have developed interactive data visualizations, available online https://cognartive.github.io/, to enhance understanding and accessibility.
Bridging Smart Meter Gaps: A Benchmark of Statistical, Machine Learning and Time Series Foundation Models for Data Imputation
Jan 13, 2025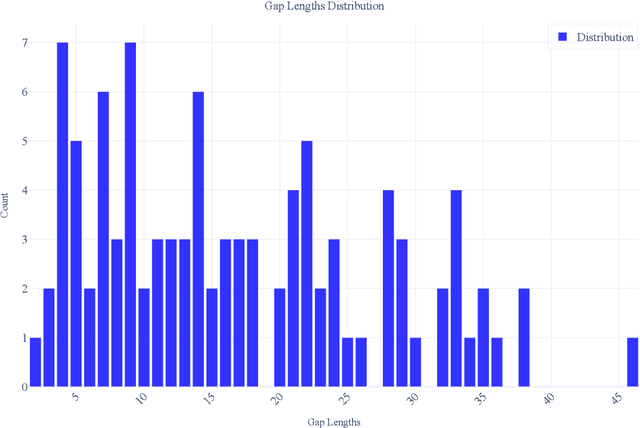
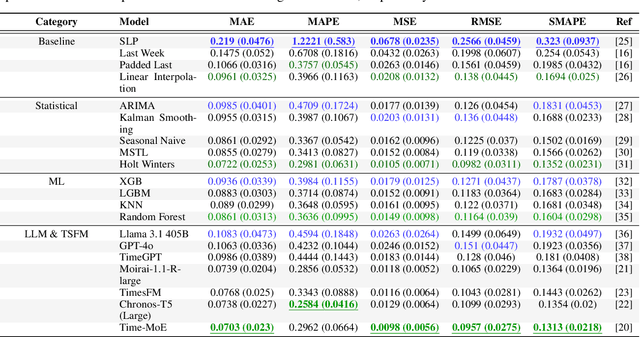

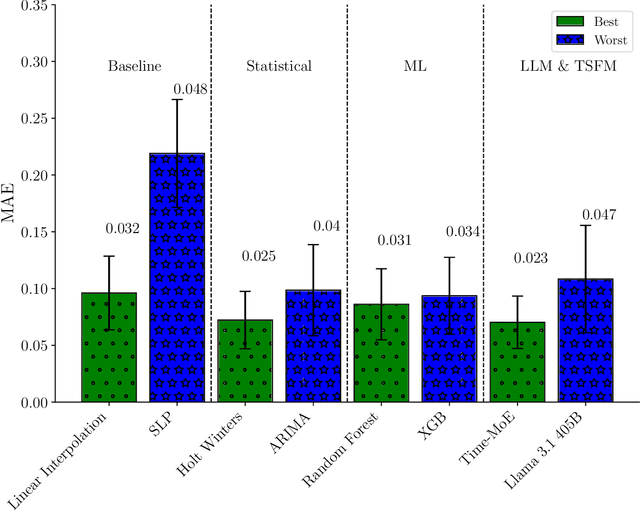
The integrity of time series data in smart grids is often compromised by missing values due to sensor failures, transmission errors, or disruptions. Gaps in smart meter data can bias consumption analyses and hinder reliable predictions, causing technical and economic inefficiencies. As smart meter data grows in volume and complexity, conventional techniques struggle with its nonlinear and nonstationary patterns. In this context, Generative Artificial Intelligence offers promising solutions that may outperform traditional statistical methods. In this paper, we evaluate two general-purpose Large Language Models and five Time Series Foundation Models for smart meter data imputation, comparing them with conventional Machine Learning and statistical models. We introduce artificial gaps (30 minutes to one day) into an anonymized public dataset to test inference capabilities. Results show that Time Series Foundation Models, with their contextual understanding and pattern recognition, could significantly enhance imputation accuracy in certain cases. However, the trade-off between computational cost and performance gains remains a critical consideration.
OPSD: an Offensive Persian Social media Dataset and its baseline evaluations
Apr 08, 2024



The proliferation of hate speech and offensive comments on social media has become increasingly prevalent due to user activities. Such comments can have detrimental effects on individuals' psychological well-being and social behavior. While numerous datasets in the English language exist in this domain, few equivalent resources are available for Persian language. To address this gap, this paper introduces two offensive datasets. The first dataset comprises annotations provided by domain experts, while the second consists of a large collection of unlabeled data obtained through web crawling for unsupervised learning purposes. To ensure the quality of the former dataset, a meticulous three-stage labeling process was conducted, and kappa measures were computed to assess inter-annotator agreement. Furthermore, experiments were performed on the dataset using state-of-the-art language models, both with and without employing masked language modeling techniques, as well as machine learning algorithms, in order to establish the baselines for the dataset using contemporary cutting-edge approaches. The obtained F1-scores for the three-class and two-class versions of the dataset were 76.9% and 89.9% for XLM-RoBERTa, respectively.
Exploring the Potential of Machine Translation for Generating Named Entity Datasets: A Case Study between Persian and English
Feb 19, 2023This study focuses on the generation of Persian named entity datasets through the application of machine translation on English datasets. The generated datasets were evaluated by experimenting with one monolingual and one multilingual transformer model. Notably, the CoNLL 2003 dataset has achieved the highest F1 score of 85.11%. In contrast, the WNUT 2017 dataset yielded the lowest F1 score of 40.02%. The results of this study highlight the potential of machine translation in creating high-quality named entity recognition datasets for low-resource languages like Persian. The study compares the performance of these generated datasets with English named entity recognition systems and provides insights into the effectiveness of machine translation for this task. Additionally, this approach could be used to augment data in low-resource language or create noisy data to make named entity systems more robust and improve them.
An Evaluation of Persian-English Machine Translation Datasets with Transformers
Feb 01, 2023



Nowadays, many researchers are focusing their attention on the subject of machine translation (MT). However, Persian machine translation has remained unexplored despite a vast amount of research being conducted in languages with high resources, such as English. Moreover, while a substantial amount of research has been undertaken in statistical machine translation for some datasets in Persian, there is currently no standard baseline for transformer-based text2text models on each corpus. This study collected and analysed the most popular and valuable parallel corpora, which were used for Persian-English translation. Furthermore, we fine-tuned and evaluated two state-of-the-art attention-based seq2seq models on each dataset separately (48 results). We hope this paper will assist researchers in comparing their Persian to English and vice versa machine translation results to a standard baseline.