 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraPLUS: Graph-based Placement Using Semantics for Image Composition
Mar 20, 2025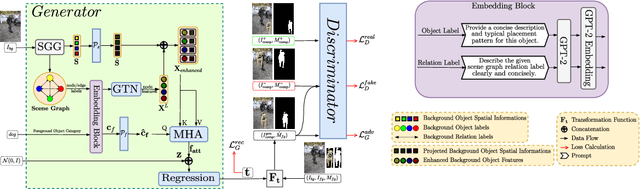
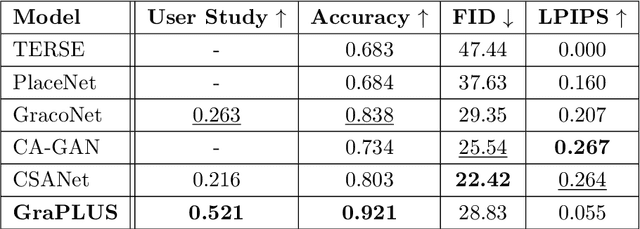
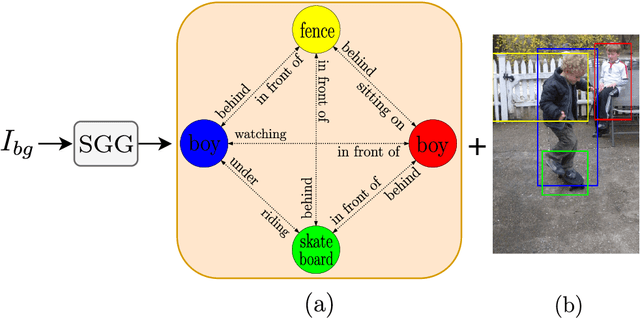
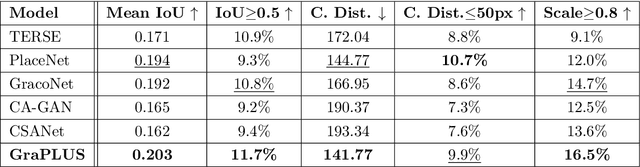
We present GraPLUS (Graph-based Placement Using Semantics), a novel framework for plausible object placement in images that leverages scene graphs and large language models. Our approach uniquely combines graph-structured scene representation with semantic understanding to determine contextually appropriate object positions. The framework employs GPT-2 to transform categorical node and edge labels into rich semantic embeddings that capture both definitional characteristics and typical spatial contexts, enabling nuanced understanding of object relationships and placement patterns. GraPLUS achieves placement accuracy of 92.1% and an FID score of 28.83 on the OPA dataset, outperforming state-of-the-art methods by 8.1% while maintaining competitive visual quality. In human evaluation studies involving 964 samples assessed by 19 participants, our method was preferred in 52.1% of cases, significantly outperforming previous approaches. The framework's key innovations include: (i) leveraging pre-trained scene graph models that transfer knowledge from other domains, (ii) edge-aware graph neural networks that process scene semantics through structured relationships, (iii) a cross-modal attention mechanism that aligns categorical embeddings with enhanced scene features, and (iv) a multiobjective training strategy incorporating semantic consistency constraints.
Unpaired Image-to-Image Translation with Content Preserving Perspective: A Review
Feb 11, 2025Image-to-image translation (I2I) transforms an image from a source domain to a target domain while preserving source content. Most computer vision applications are in the field of image-to-image translation, such as style transfer, image segmentation, and photo enhancement. The degree of preservation of the content of the source images in the translation process can be different according to the problem and the intended application. From this point of view, in this paper, we divide the different tasks in the field of image-to-image translation into three categories: Fully Content preserving, Partially Content preserving, and Non-Content preserving. We present different tasks, datasets, methods, results of methods for these three categories in this paper. We make a categorization for I2I methods based on the architecture of different models and study each category separately. In addition, we introduce well-known evaluation criteria in the I2I translation field. Specifically, nearly 70 different I2I models were analyzed, and more than 10 quantitative evaluation metrics and 30 distinct tasks and datasets relevant to the I2I translation problem were both introduced and assessed. Translating from simulation to real images could be well viewed as an application of fully content preserving or partially content preserving unsupervised image-to-image translation methods. So, we provide a benchmark for Sim-to-Real translation, which can be used to evaluate different methods. In general, we conclude that because of the different extent of the obligation to preserving content in various applications, it is better to consider this issue in choosing a suitable I2I model for a specific application.
OPSD: an Offensive Persian Social media Dataset and its baseline evaluations
Apr 08, 2024



The proliferation of hate speech and offensive comments on social media has become increasingly prevalent due to user activities. Such comments can have detrimental effects on individuals' psychological well-being and social behavior. While numerous datasets in the English language exist in this domain, few equivalent resources are available for Persian language. To address this gap, this paper introduces two offensive datasets. The first dataset comprises annotations provided by domain experts, while the second consists of a large collection of unlabeled data obtained through web crawling for unsupervised learning purposes. To ensure the quality of the former dataset, a meticulous three-stage labeling process was conducted, and kappa measures were computed to assess inter-annotator agreement. Furthermore, experiments were performed on the dataset using state-of-the-art language models, both with and without employing masked language modeling techniques, as well as machine learning algorithms, in order to establish the baselines for the dataset using contemporary cutting-edge approaches. The obtained F1-scores for the three-class and two-class versions of the dataset were 76.9% and 89.9% for XLM-RoBERTa, respectively.
Knowledge Distillation on Spatial-Temporal Graph Convolutional Network for Traffic Prediction
Jan 28, 2024Efficient real-time traffic prediction is crucial for reducing transportation time. To predict traffic conditions, we employ a spatio-temporal graph neural network (ST-GNN) to model our real-time traffic data as temporal graphs. Despite its capabilities, it often encounters challenges in delivering efficient real-time predictions for real-world traffic data. Recognizing the significance of timely prediction due to the dynamic nature of real-time data, we employ knowledge distillation (KD) as a solution to enhance the execution time of ST-GNNs for traffic prediction. In this paper, We introduce a cost function designed to train a network with fewer parameters (the student) using distilled data from a complex network (the teacher) while maintaining its accuracy close to that of the teacher. We use knowledge distillation, incorporating spatial-temporal correlations from the teacher network to enable the student to learn the complex patterns perceived by the teacher. However, a challenge arises in determining the student network architecture rather than considering it inadvertently. To address this challenge, we propose an algorithm that utilizes the cost function to calculate pruning scores, addressing small network architecture search issues, and jointly fine-tunes the network resulting from each pruning stage using KD. Ultimately, we evaluate our proposed ideas on two real-world datasets, PeMSD7 and PeMSD8. The results indicate that our method can maintain the student's accuracy close to that of the teacher, even with the retention of only $3\%$ of network parameters.
HDGL: A hierarchical dynamic graph representation learning model for brain disorder classification
Nov 06, 2023The human brain can be considered as complex networks, composed of various regions that continuously exchange their information with each other, forming the brain network graph, from which nodes and edges are extracted using resting-state functional magnetic resonance imaging (rs-fMRI). Therefore, this graph can potentially depict abnormal patterns that have emerged under the influence of brain disorders. So far, numerous studies have attempted to find embeddings for brain network graphs and subsequently classify samples with brain disorders from healthy ones, which include limitations such as: not considering the relationship between samples, not utilizing phenotype information, lack of temporal analysis, using static functional connectivity (FC) instead of dynamic ones and using a fixed graph structure. We propose a hierarchical dynamic graph representation learning (HDGL) model, which is the first model designed to address all the aforementioned challenges. HDGL consists of two levels, where at the first level, it constructs brain network graphs and learns their spatial and temporal embeddings, and at the second level, it forms population graphs and performs classification after embedding learning. Furthermore, based on how these two levels are trained, four methods have been introduced, some of which are suggested for reducing memory complexity. We evaluated the performance of the proposed model on the ABIDE and ADHD-200 datasets, and the results indicate the improvement of this model compared to several state-of-the-art models in terms of various evaluation metrics.
Clustering based on Mixtures of Sparse Gaussian Processes
Mar 23, 2023Creating low dimensional representations of a high dimensional data set is an important component in many machine learning applications. How to cluster data using their low dimensional embedded space is still a challenging problem in machine learning. In this article, we focus on proposing a joint formulation for both clustering and dimensionality reduction. When a probabilistic model is desired, one possible solution is to use the mixture models in which both cluster indicator and low dimensional space are learned. Our algorithm is based on a mixture of sparse Gaussian processes, which is called Sparse Gaussian Process Mixture Clustering (SGP-MIC). The main advantages to our approach over existing methods are that the probabilistic nature of this model provides more advantages over existing deterministic methods, it is straightforward to construct non-linear generalizations of the model, and applying a sparse model and an efficient variational EM approximation help to speed up the algorithm.
Deep Graph Clustering via Mutual Information Maximization and Mixture Model
May 10, 2022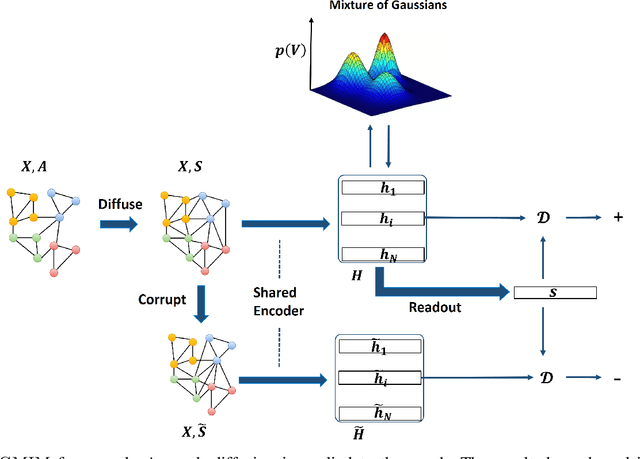


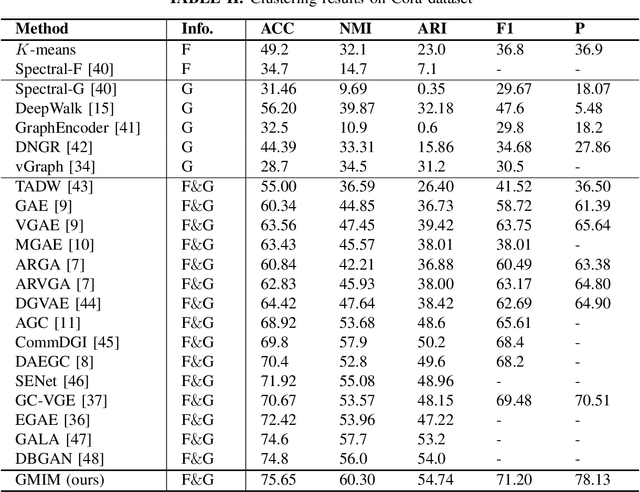
Attributed graph clustering or community detection which learns to cluster the nodes of a graph is a challenging task in graph analysis. In this paper, we introduce a contrastive learning framework for learning clustering-friendly node embedding. Although graph contrastive learning has shown outstanding performance in self-supervised graph learning, using it for graph clustering is not well explored. We propose Gaussian mixture information maximization (GMIM) which utilizes a mutual information maximization approach for node embedding. Meanwhile, it assumes that the representation space follows a Mixture of Gaussians (MoG) distribution. The clustering part of our objective tries to fit a Gaussian distribution to each community. The node embedding is jointly optimized with the parameters of MoG in a unified framework. Experiments on real-world datasets demonstrate the effectiveness of our method in community detection.
Joint Sentiment/Topic Modeling on Text Data Using Boosted Restricted Boltzmann Machine
Nov 10, 2017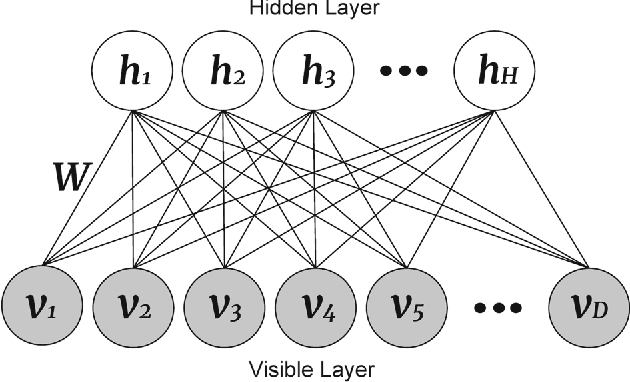
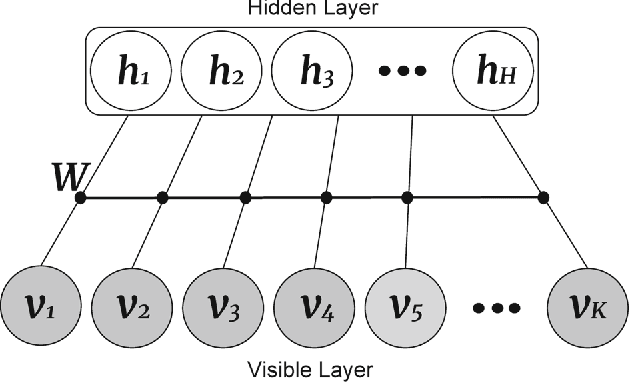
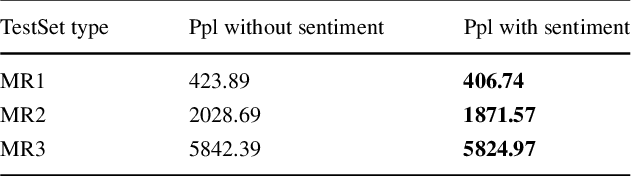
Recently by the development of the Internet and the Web, different types of social media such as web blogs become an immense source of text data. Through the processing of these data, it is possible to discover practical information about different topics, individuals opinions and a thorough understanding of the society. Therefore, applying models which can automatically extract the subjective information from the documents would be efficient and helpful. Topic modeling methods, also sentiment analysis are the most raised topics in the natural language processing and text mining fields. In this paper a new structure for joint sentiment-topic modeling based on Restricted Boltzmann Machine (RBM) which is a type of neural networks is proposed. By modifying the structure of RBM as well as appending a layer which is analogous to sentiment of text data to it, we propose a generative structure for joint sentiment topic modeling based on neutral networks. The proposed method is supervised and trained by the Contrastive Divergence algorithm. The new attached layer in the proposed model is a layer with the multinomial probability distribution which can be used in text data sentiment classification or any other supervised application. The proposed model is compared with existing models in the experiments such as evaluating as a generative model, sentiment classification, information retrieval and the corresponding results demonstrate the efficiency of the method.
A Latent Variable Model for Two-Dimensional Canonical Correlation Analysis and its Variational Inference
Aug 04, 2017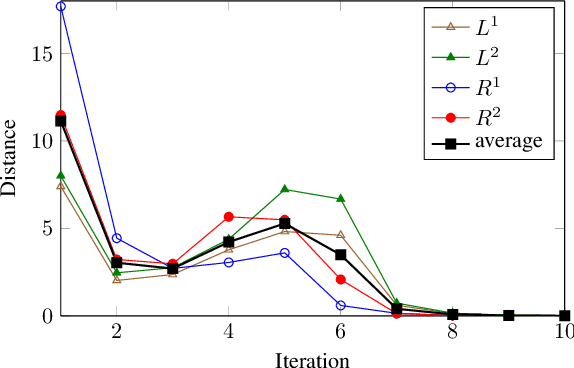
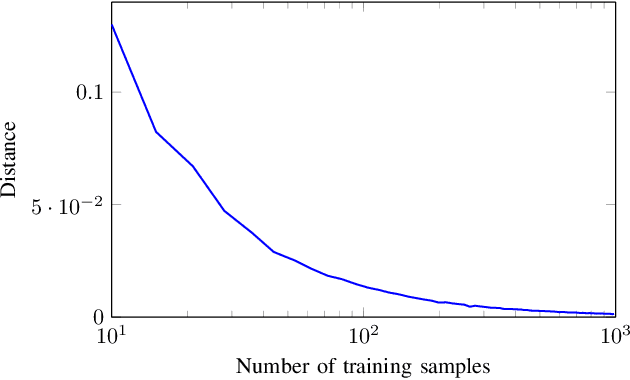
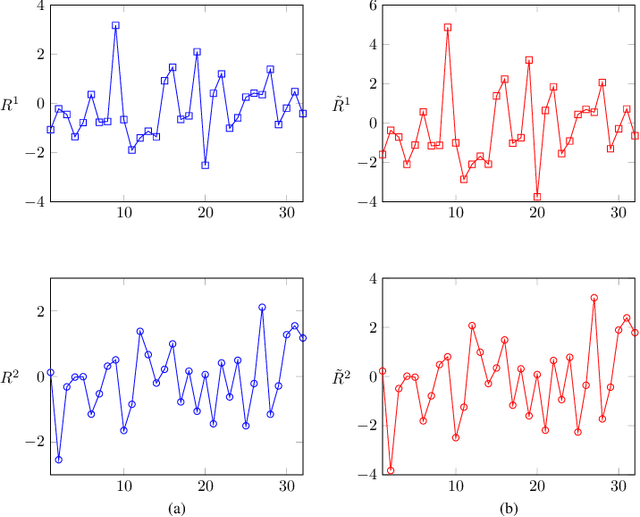
Describing the dimension reduction (DR) techniques by means of probabilistic models has recently been given special attention. Probabilistic models, in addition to a better interpretability of the DR methods, provide a framework for further extensions of such algorithms. One of the new approaches to the probabilistic DR methods is to preserving the internal structure of data. It is meant that it is not necessary that the data first be converted from the matrix or tensor format to the vector format in the process of dimensionality reduction. In this paper, a latent variable model for matrix-variate data for canonical correlation analysis (CCA) is proposed. Since in general there is not any analytical maximum likelihood solution for this model, we present two approaches for learning the parameters. The proposed methods are evaluated using the synthetic data in terms of convergence and quality of mappings. Also, real data set is employed for assessing the proposed methods with several probabilistic and none-probabilistic CCA based approaches. The results confirm the superiority of the proposed methods with respect to the competing algorithms. Moreover, this model can be considered as a framework for further extensions.
An EM Based Probabilistic Two-Dimensional CCA with Application to Face Recognition
Feb 25, 2017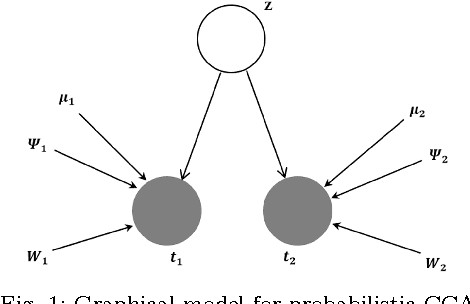
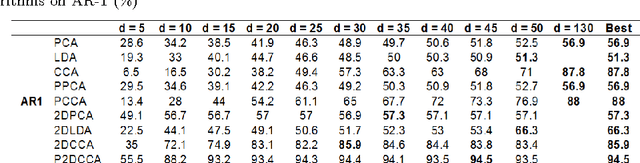

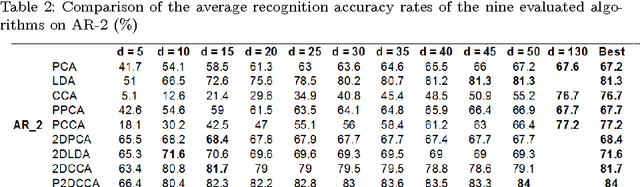
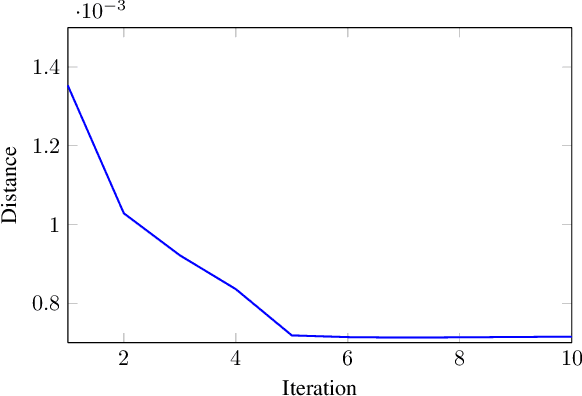
Recently, two-dimensional canonical correlation analysis (2DCCA) has been successfully applied for image feature extraction. The method instead of concatenating the columns of the images to the one-dimensional vectors, directly works with two-dimensional image matrices. Although 2DCCA works well in different recognition tasks, it lacks a probabilistic interpretation. In this paper, we present a probabilistic framework for 2DCCA called probabilistic 2DCCA (P2DCCA) and an iterative EM based algorithm for optimizing the parameters. Experimental results on synthetic and real data demonstrate superior performance in loading factor estimation for P2DCCA compared to 2DCCA. For real data, three subsets of AR face database and also the UMIST face database confirm the robustness of the proposed algorithm in face recognition tasks with different illumination conditions, facial expressions, poses and occlusions.