 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation on Spatial-Temporal Graph Convolutional Network for Traffic Prediction
Jan 28, 2024Efficient real-time traffic prediction is crucial for reducing transportation time. To predict traffic conditions, we employ a spatio-temporal graph neural network (ST-GNN) to model our real-time traffic data as temporal graphs. Despite its capabilities, it often encounters challenges in delivering efficient real-time predictions for real-world traffic data. Recognizing the significance of timely prediction due to the dynamic nature of real-time data, we employ knowledge distillation (KD) as a solution to enhance the execution time of ST-GNNs for traffic prediction. In this paper, We introduce a cost function designed to train a network with fewer parameters (the student) using distilled data from a complex network (the teacher) while maintaining its accuracy close to that of the teacher. We use knowledge distillation, incorporating spatial-temporal correlations from the teacher network to enable the student to learn the complex patterns perceived by the teacher. However, a challenge arises in determining the student network architecture rather than considering it inadvertently. To address this challenge, we propose an algorithm that utilizes the cost function to calculate pruning scores, addressing small network architecture search issues, and jointly fine-tunes the network resulting from each pruning stage using KD. Ultimately, we evaluate our proposed ideas on two real-world datasets, PeMSD7 and PeMSD8. The results indicate that our method can maintain the student's accuracy close to that of the teacher, even with the retention of only $3\%$ of network parameters.
Stateless and Rule-Based Verification For Compliance Checking Applications
Apr 28, 2022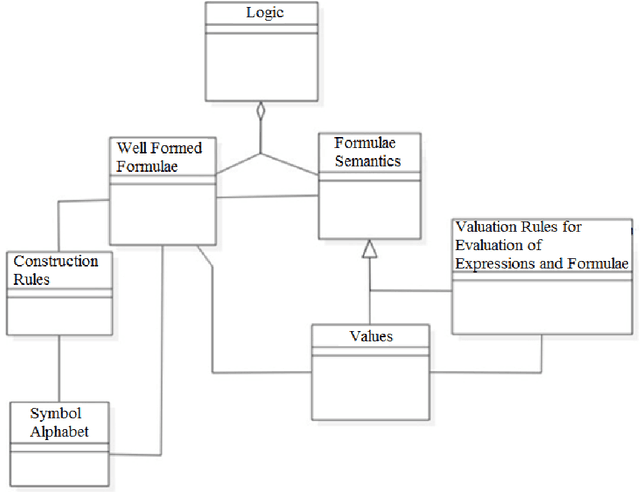
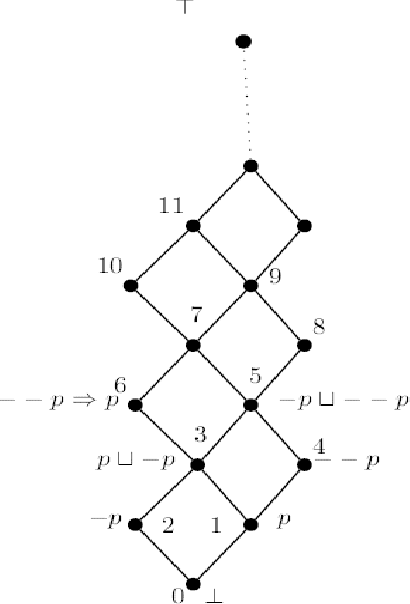
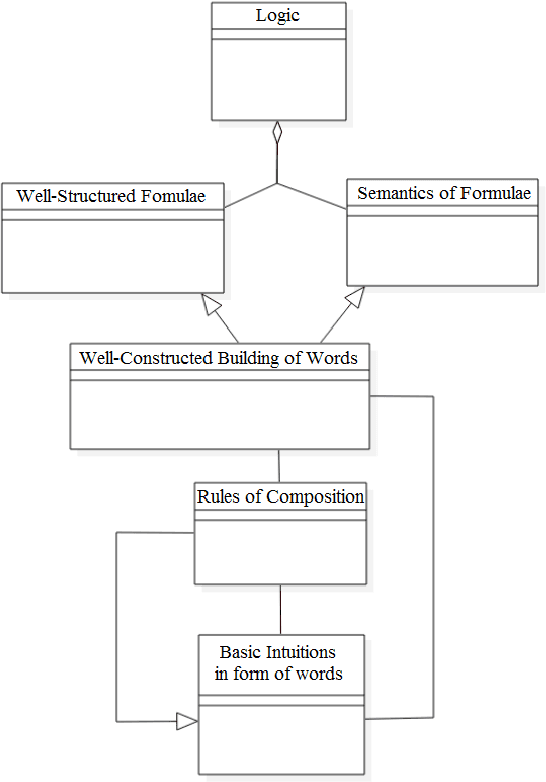
Underlying computational model has an important role in any computation. The state and transition (such as in automata) and rule and value (such as in Lisp and logic programming) are two comparable and counterpart computational models. Both of deductive and model checking verification techniques are relying on a notion of state and as a result, their underlying computational models are state dependent. Some verification problems (such as compliance checking by which an under compliance system is verified against some regulations and rules) have not a strong notion of state nor transition. Behalf of it, these systems have a strong notion of value symbols and declarative rules defined on them. SARV (Stateless And Rule-Based Verification) is a verification framework that designed to simplify the overall process of verification for stateless and rule-based verification problems (e.g. compliance checking). In this paper, a formal logic-based framework for creating intelligent compliance checking systems is presented. We define and introduce this framework, report a case study and present results of an experiment on it. The case study is about protocol compliance checking for smart cities. Using this solution, a Rescue Scenario use case and its compliance checking are sketched and modeled. An automation engine for and a compliance solution with SARV are introduced. Based on 300 data experiments, the SARV-based compliance solution outperforms famous machine learning methods on a 3125-records software quality dataset.
SELM: Software Engineering of Machine Learning Models
Mar 20, 2021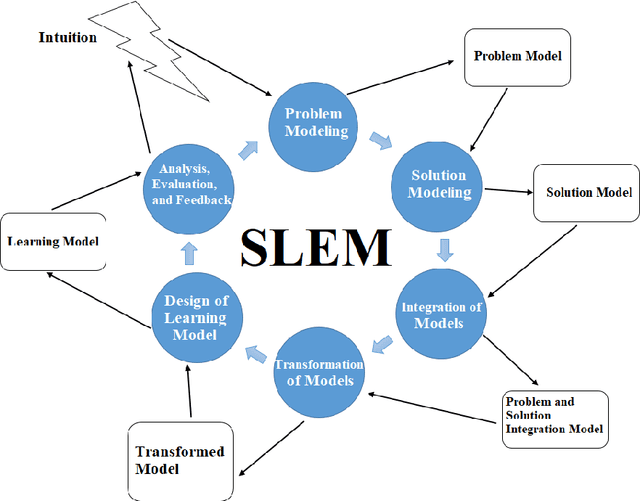
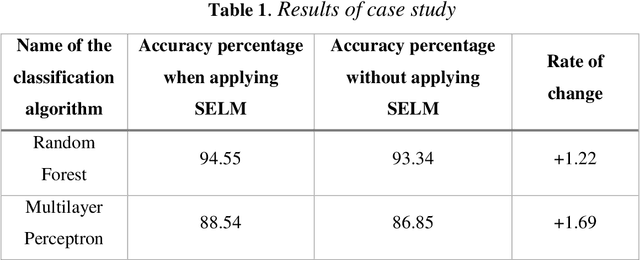
One of the pillars of any machine learning model is its concepts. Using software engineering, we can engineer these concepts and then develop and expand them. In this article, we present a SELM framework for Software Engineering of machine Learning Models. We then evaluate this framework through a case study. Using the SELM framework, we can improve a machine learning process efficiency and provide more accuracy in learning with less processing hardware resources and a smaller training dataset. This issue highlights the importance of an interdisciplinary approach to machine learning. Therefore, in this article, we have provided interdisciplinary teams' proposals for machine learning.
Phishing Detection Using Machine Learning Techniques
Sep 20, 2020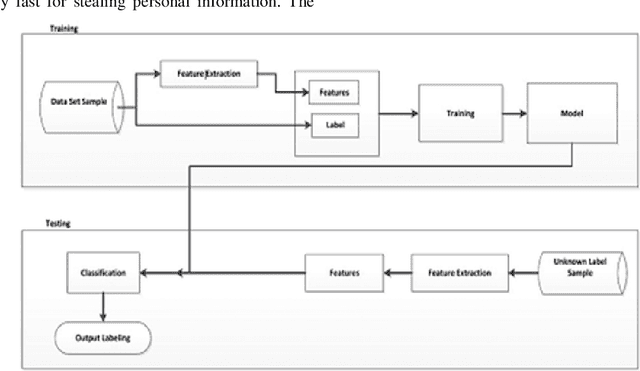
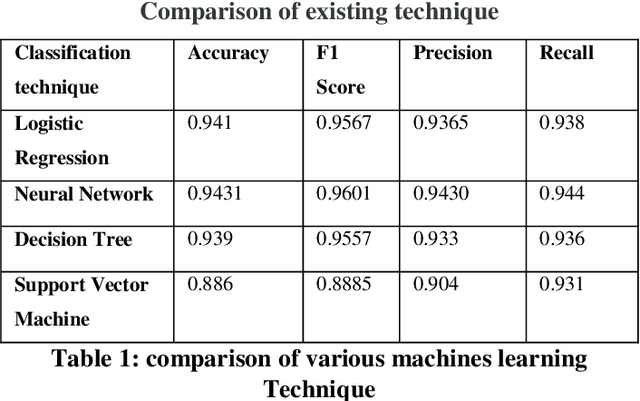
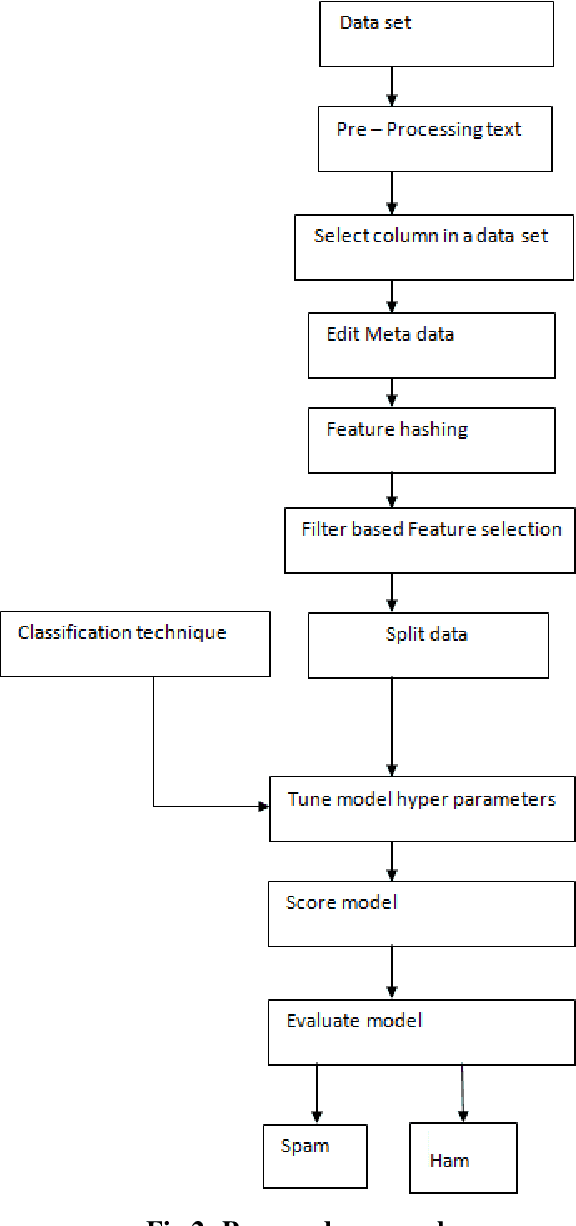
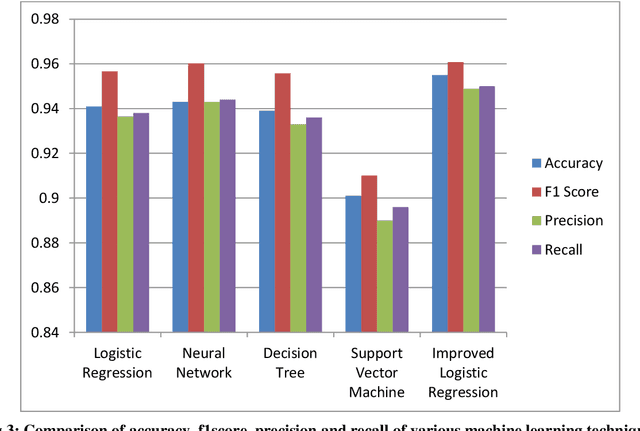
The Internet has become an indispensable part of our life, However, It also has provided opportunities to anonymously perform malicious activities like Phishing. Phishers try to deceive their victims by social engineering or creating mock-up websites to steal information such as account ID, username, password from individuals and organizations. Although many methods have been proposed to detect phishing websites, Phishers have evolved their methods to escape from these detection methods. One of the most successful methods for detecting these malicious activities is Machine Learning. This is because most Phishing attacks have some common characteristics which can be identified by machine learning methods. In this paper, we compared the results of multiple machine learning methods for predicting phishing websites.
DAST Model: Deciding About Semantic Complexity of a Text
Oct 01, 2019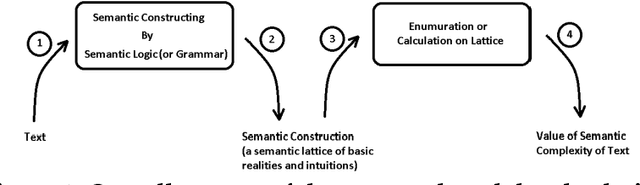
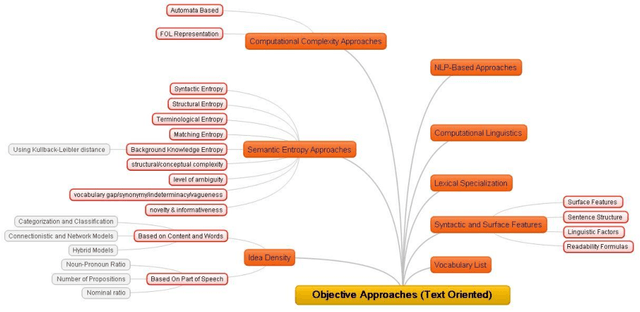
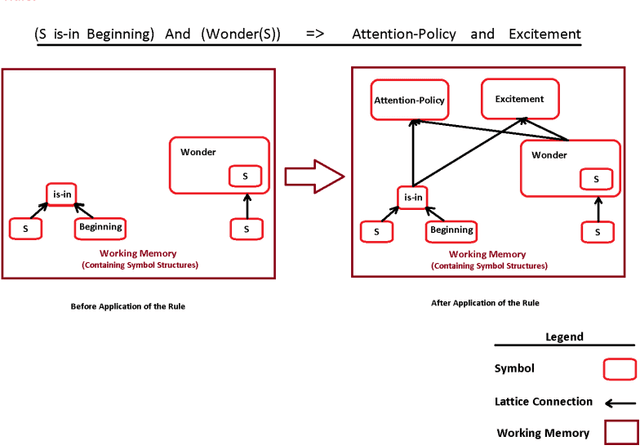
Measuring text complexity is an essential task in several fields and applications (such as NLP, semantic web, smart education, etc.). The semantic layer of text is more tacit than its syntactic structure and, as a result, calculation of semantic complexity is more difficult than syntactic complexity. While there are famous and powerful academic and commercial syntactic complexity measures, the problem of measuring semantic complexity is still a challenging one. In this paper, we introduce the DAST model, which stands for Deciding About Semantic Complexity of a Text. DAST proposes an intuitionistic approach to semantics that lets us have a well-defined model for the semantics of a text and its complexity: semantic is considered as a lattice of intuitions and, as a result, semantic complexity is defined as the result of a calculation on this lattice. A set theoretic formal definition of semantic complexity, as a 6-tuple formal system, is provided. By using this formal system, a method for measuring semantic complexity is presented. The evaluation of the proposed approach is done by a set of three human-judgment experiments. The results show that DAST model is capable of deciding about semantic complexity of text. Furthermore, the analysis of the results leads us to introduce a Markovian model for the process of common-sense, multiple-steps and semantic-complexity reasoning in people. The results of Experiments demonstrate that our method outperforms the random baseline with improvement in precision and accuracy.
A Deep Learning-Based Approach for Measuring the Domain Similarity of Persian Texts
Sep 24, 2019
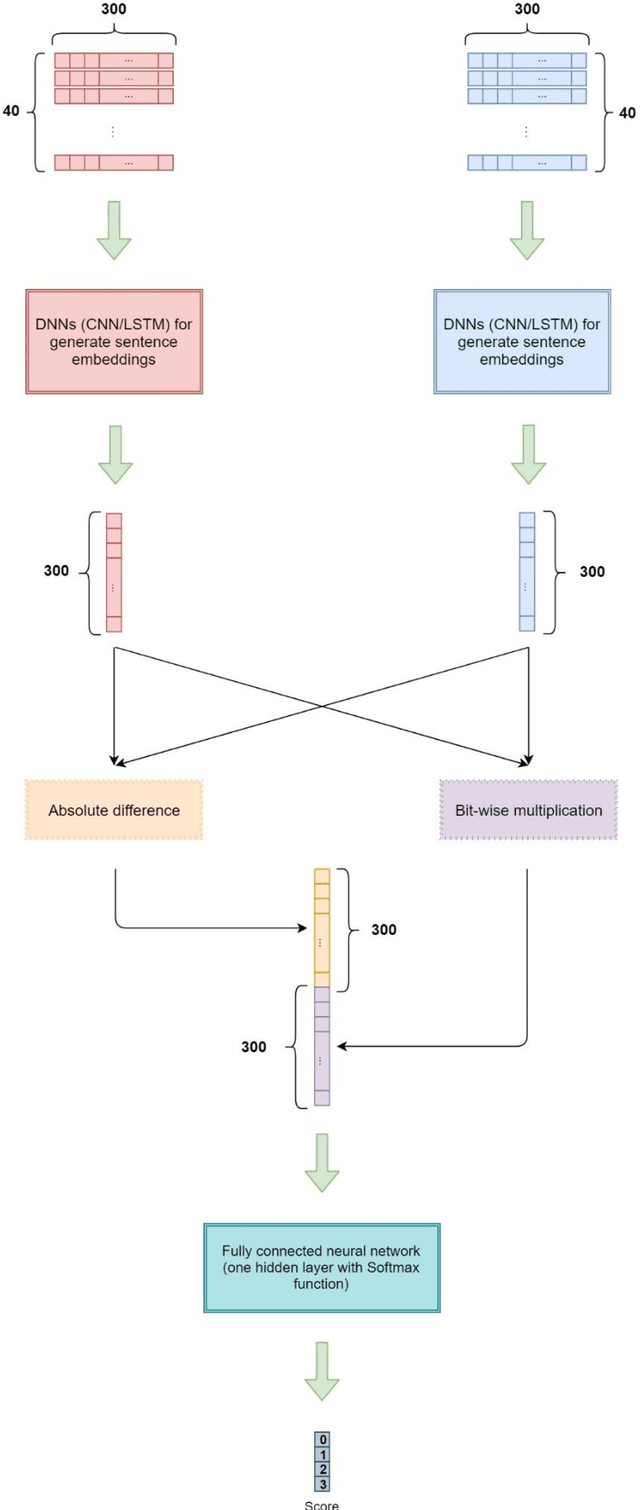
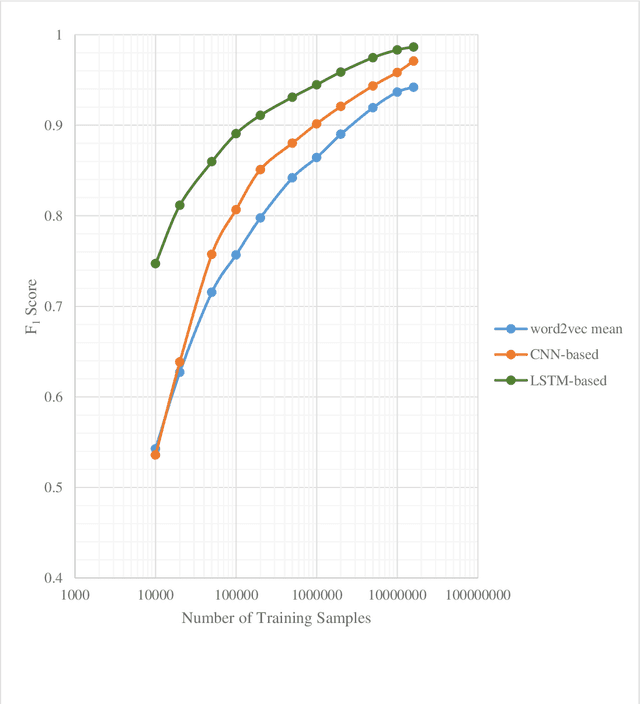

In this paper, we propose a novel approach for measuring the degree of similarity between categories of two pieces of Persian text, which were published as descriptions of two separate advertisements. We built an appropriate dataset for this work using a dataset which consists of advertisements posted on an e-commerce website. We generated a significant number of paired texts from this dataset and assigned each pair a score from 0 to 3, which demonstrates the degree of similarity between the domains of the pair. In this work, we represent words with word embedding vectors derived from word2vec. Then deep neural network models are used to represent texts. Eventually, we employ concatenation of absolute difference and bit-wise multiplication and a fully-connected neural network to produce a probability distribution vector for the score of the pairs. Through a supervised learning approach, we trained our model on a GPU, and our best model achieved an F1 score of 0.9865.