 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning-Based Approach for Measuring the Domain Similarity of Persian Texts
Paper and Code

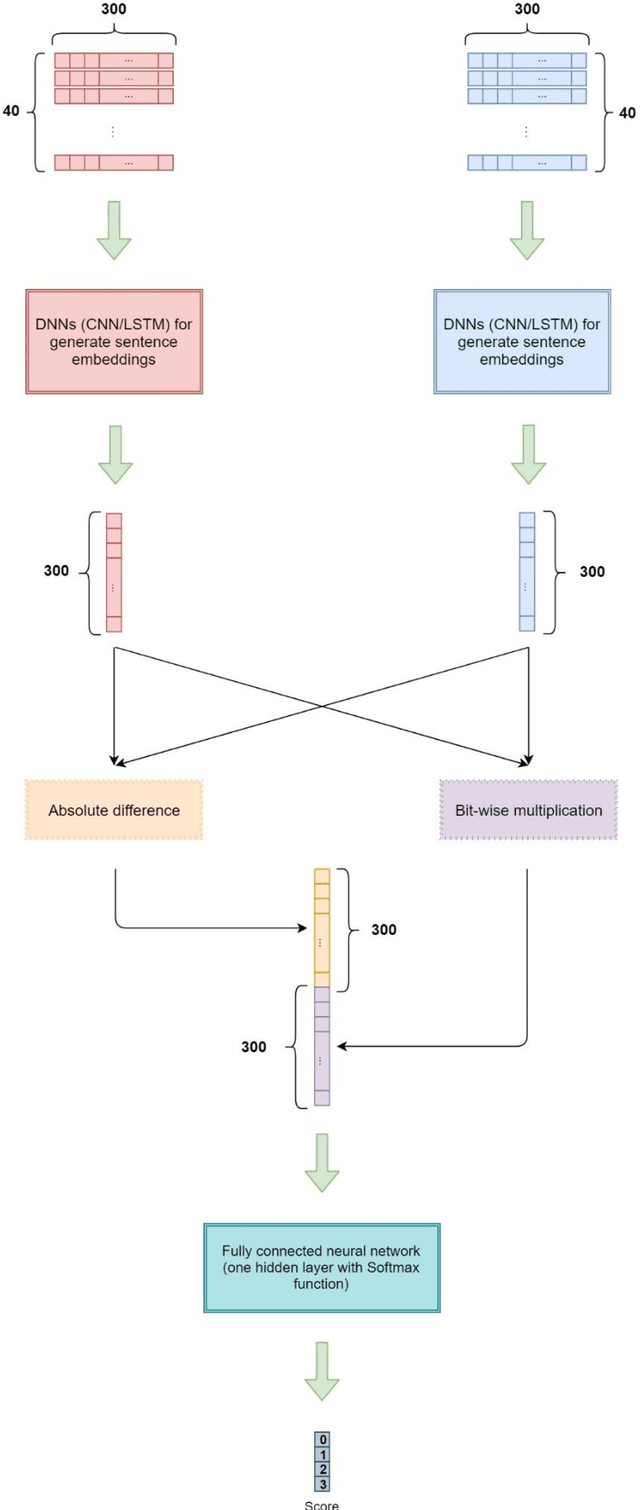
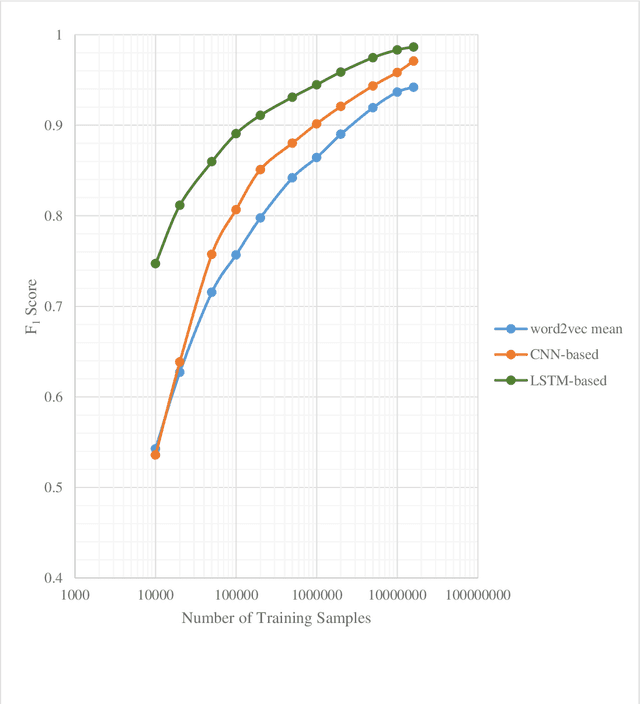

In this paper, we propose a novel approach for measuring the degree of similarity between categories of two pieces of Persian text, which were published as descriptions of two separate advertisements. We built an appropriate dataset for this work using a dataset which consists of advertisements posted on an e-commerce website. We generated a significant number of paired texts from this dataset and assigned each pair a score from 0 to 3, which demonstrates the degree of similarity between the domains of the pair. In this work, we represent words with word embedding vectors derived from word2vec. Then deep neural network models are used to represent texts. Eventually, we employ concatenation of absolute difference and bit-wise multiplication and a fully-connected neural network to produce a probability distribution vector for the score of the pairs. Through a supervised learning approach, we trained our model on a GPU, and our best model achieved an F1 score of 0.9865.