 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMA-ES with Radial Basis Function Surrogate for Black-Box Optimization
May 22, 2025Evolutionary optimization algorithms often face defects and limitations that complicate the evolution processes or even prevent them from reaching the global optimum. A notable constraint pertains to the considerable quantity of function evaluations required to achieve the intended solution. This concern assumes heightened significance when addressing costly optimization problems. However, recent research has shown that integrating machine learning methods, specifically surrogate models, with evolutionary optimization can enhance various aspects of these algorithms. Among the evolutionary algorithms, the Covariance Matrix Adaptation Evolutionary Strategy (CMA-ES) is particularly favored. This preference is due to its use of Gaussian distribution for calculating evolution and its ability to adapt optimization parameters, which reduces the need for user intervention in adjusting initial parameters. In this research endeavor, we propose the adoption of surrogate models within the CMA-ES framework called CMA-SAO to develop an initial surrogate model that facilitates the adaptation of optimization parameters through the acquisition of pertinent information derived from the associated surrogate model. Empirical validation reveals that CMA-SAO algorithm markedly diminishes the number of function evaluations in comparison to prevailing algorithms, thereby providing a significant enhancement in operational efficiency.
* 6 pages, ITNG 2025 Conference
GraPLUS: Graph-based Placement Using Semantics for Image Composition
Mar 20, 2025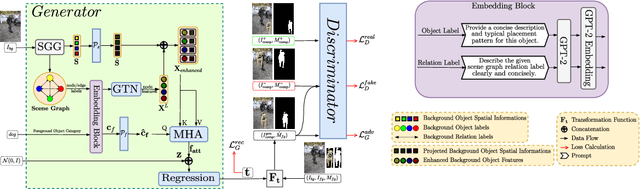
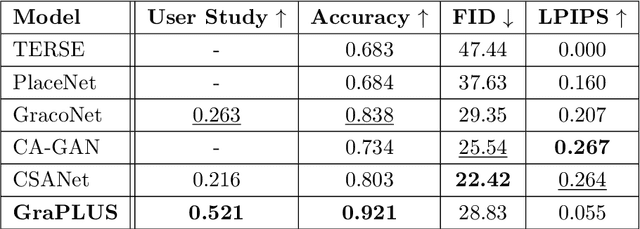
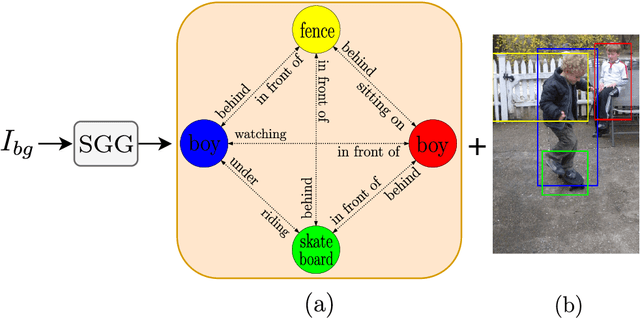
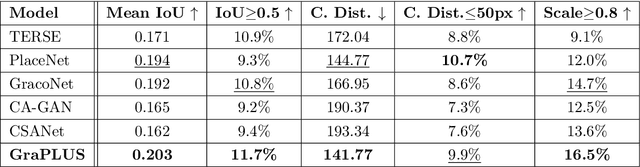
We present GraPLUS (Graph-based Placement Using Semantics), a novel framework for plausible object placement in images that leverages scene graphs and large language models. Our approach uniquely combines graph-structured scene representation with semantic understanding to determine contextually appropriate object positions. The framework employs GPT-2 to transform categorical node and edge labels into rich semantic embeddings that capture both definitional characteristics and typical spatial contexts, enabling nuanced understanding of object relationships and placement patterns. GraPLUS achieves placement accuracy of 92.1% and an FID score of 28.83 on the OPA dataset, outperforming state-of-the-art methods by 8.1% while maintaining competitive visual quality. In human evaluation studies involving 964 samples assessed by 19 participants, our method was preferred in 52.1% of cases, significantly outperforming previous approaches. The framework's key innovations include: (i) leveraging pre-trained scene graph models that transfer knowledge from other domains, (ii) edge-aware graph neural networks that process scene semantics through structured relationships, (iii) a cross-modal attention mechanism that aligns categorical embeddings with enhanced scene features, and (iv) a multiobjective training strategy incorporating semantic consistency constraints.
Knowledge Distillation on Spatial-Temporal Graph Convolutional Network for Traffic Prediction
Jan 28, 2024Efficient real-time traffic prediction is crucial for reducing transportation time. To predict traffic conditions, we employ a spatio-temporal graph neural network (ST-GNN) to model our real-time traffic data as temporal graphs. Despite its capabilities, it often encounters challenges in delivering efficient real-time predictions for real-world traffic data. Recognizing the significance of timely prediction due to the dynamic nature of real-time data, we employ knowledge distillation (KD) as a solution to enhance the execution time of ST-GNNs for traffic prediction. In this paper, We introduce a cost function designed to train a network with fewer parameters (the student) using distilled data from a complex network (the teacher) while maintaining its accuracy close to that of the teacher. We use knowledge distillation, incorporating spatial-temporal correlations from the teacher network to enable the student to learn the complex patterns perceived by the teacher. However, a challenge arises in determining the student network architecture rather than considering it inadvertently. To address this challenge, we propose an algorithm that utilizes the cost function to calculate pruning scores, addressing small network architecture search issues, and jointly fine-tunes the network resulting from each pruning stage using KD. Ultimately, we evaluate our proposed ideas on two real-world datasets, PeMSD7 and PeMSD8. The results indicate that our method can maintain the student's accuracy close to that of the teacher, even with the retention of only $3\%$ of network parameters.
Clustering based on Mixtures of Sparse Gaussian Processes
Mar 23, 2023Creating low dimensional representations of a high dimensional data set is an important component in many machine learning applications. How to cluster data using their low dimensional embedded space is still a challenging problem in machine learning. In this article, we focus on proposing a joint formulation for both clustering and dimensionality reduction. When a probabilistic model is desired, one possible solution is to use the mixture models in which both cluster indicator and low dimensional space are learned. Our algorithm is based on a mixture of sparse Gaussian processes, which is called Sparse Gaussian Process Mixture Clustering (SGP-MIC). The main advantages to our approach over existing methods are that the probabilistic nature of this model provides more advantages over existing deterministic methods, it is straightforward to construct non-linear generalizations of the model, and applying a sparse model and an efficient variational EM approximation help to speed up the algorithm.
Deep Graph Clustering via Mutual Information Maximization and Mixture Model
May 10, 2022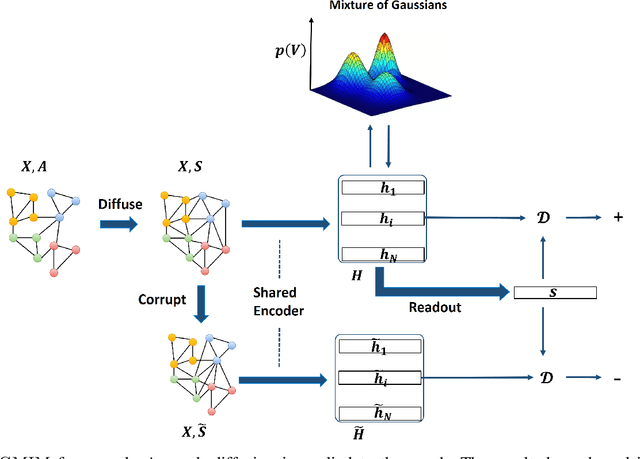


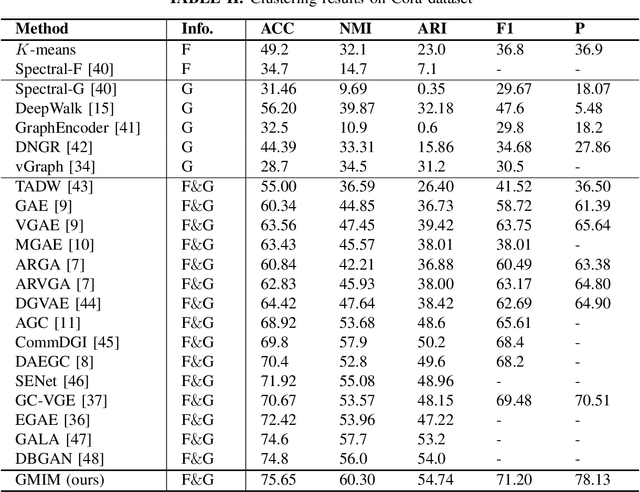
Attributed graph clustering or community detection which learns to cluster the nodes of a graph is a challenging task in graph analysis. In this paper, we introduce a contrastive learning framework for learning clustering-friendly node embedding. Although graph contrastive learning has shown outstanding performance in self-supervised graph learning, using it for graph clustering is not well explored. We propose Gaussian mixture information maximization (GMIM) which utilizes a mutual information maximization approach for node embedding. Meanwhile, it assumes that the representation space follows a Mixture of Gaussians (MoG) distribution. The clustering part of our objective tries to fit a Gaussian distribution to each community. The node embedding is jointly optimized with the parameters of MoG in a unified framework. Experiments on real-world datasets demonstrate the effectiveness of our method in community detection.
Optimized Participation of Multiple Fusion Functions in Consensus Creation: An Evolutionary Approach
May 31, 2018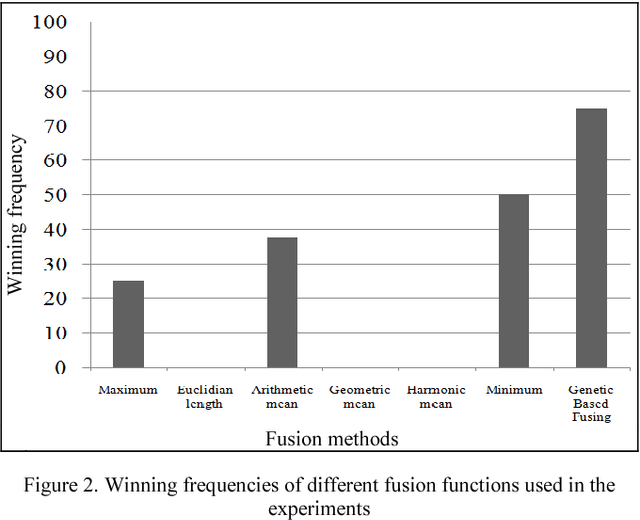

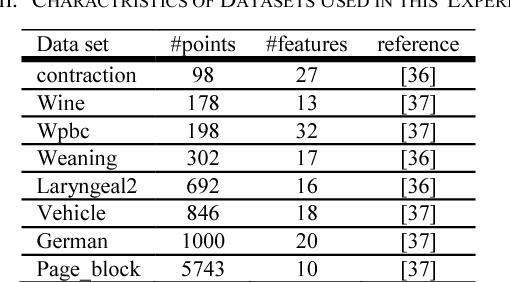
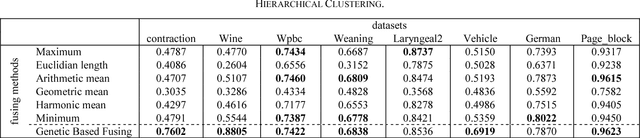
Recent studies show that ensemble methods enhance the stability and robustness of unsupervised learning. These approaches are successfully utilized to construct multiple clustering and combine them into a one representative consensus clustering of an improved quality. The quality of the consensus clustering is directly depended on fusion functions used in combination. In this article, the hierarchical clustering ensemble techniques are extended by introducing a new evolutionary fusion function. In the proposed method, multiple hierarchical clustering methods are generated via bagging. Thereafter, the consensus clustering is obtained using the search capability of genetic algorithm among different aggregated clustering methods made by different fusion functions. Putting some popular data sets to empirical study, the quality of the proposed method is compared with regular clustering ensembles. Experimental results demonstrate the accuracy improvement of the aggregated clustering results.
A Novel Multi-clustering Method for Hierarchical Clusterings, Based on Boosting
May 29, 2018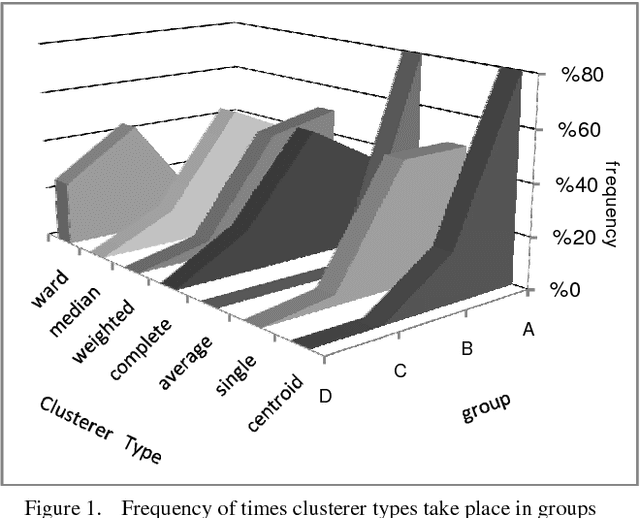
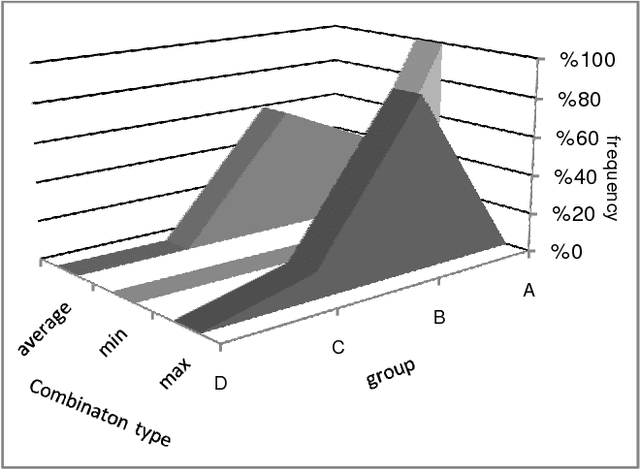
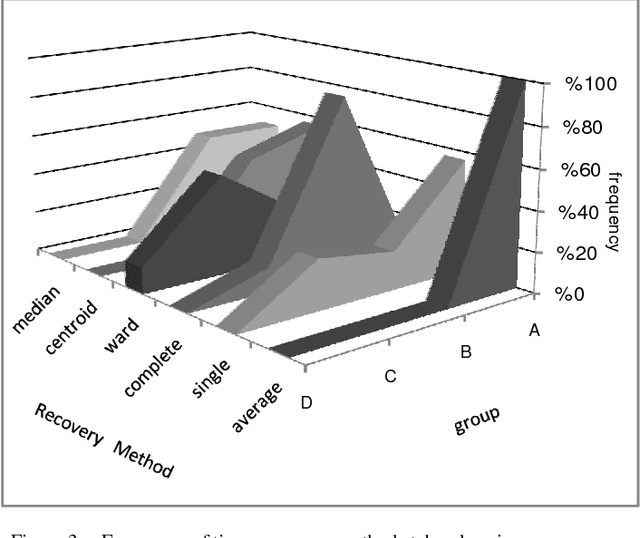
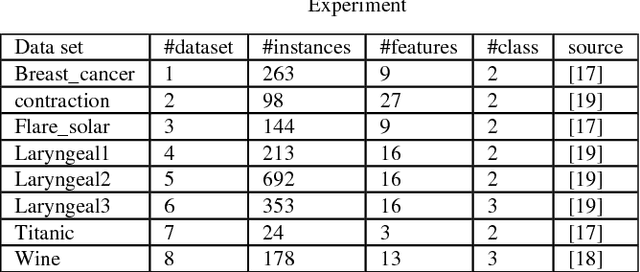
Bagging and boosting are proved to be the best methods of building multiple classifiers in classification combination problems. In the area of "flat clustering" problems, it is also recognized that multi-clustering methods based on boosting provide clusterings of an improved quality. In this paper, we introduce a novel multi-clustering method for "hierarchical clusterings" based on boosting theory, which creates a more stable hierarchical clustering of a dataset. The proposed algorithm includes a boosting iteration in which a bootstrap of samples is created by weighted random sampling of elements from the original dataset. A hierarchical clustering algorithm is then applied to selected subsample to build a dendrogram which describes the hierarchy. Finally, dissimilarity description matrices of multiple dendrogram results are combined to a consensus one, using a hierarchical-clustering-combination approach. Experiments on real popular datasets show that boosted method provides superior quality solutions compared to standard hierarchical clustering methods.
An EM Based Probabilistic Two-Dimensional CCA with Application to Face Recognition
Feb 25, 2017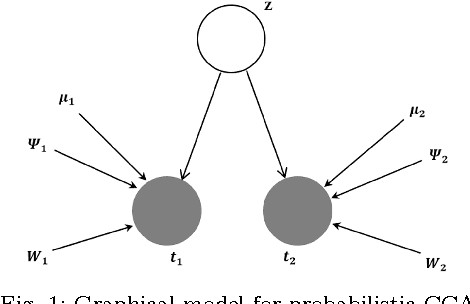
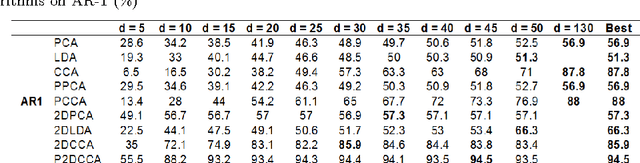

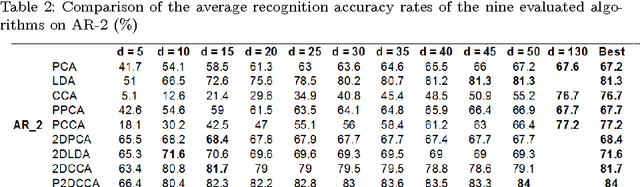
Recently, two-dimensional canonical correlation analysis (2DCCA) has been successfully applied for image feature extraction. The method instead of concatenating the columns of the images to the one-dimensional vectors, directly works with two-dimensional image matrices. Although 2DCCA works well in different recognition tasks, it lacks a probabilistic interpretation. In this paper, we present a probabilistic framework for 2DCCA called probabilistic 2DCCA (P2DCCA) and an iterative EM based algorithm for optimizing the parameters. Experimental results on synthetic and real data demonstrate superior performance in loading factor estimation for P2DCCA compared to 2DCCA. For real data, three subsets of AR face database and also the UMIST face database confirm the robustness of the proposed algorithm in face recognition tasks with different illumination conditions, facial expressions, poses and occlusions.
Generating Graphical Chain by Mutual Matching of Bayesian Network and Extracted Rules of Bayesian Network Using Genetic Algorithm
Dec 15, 2014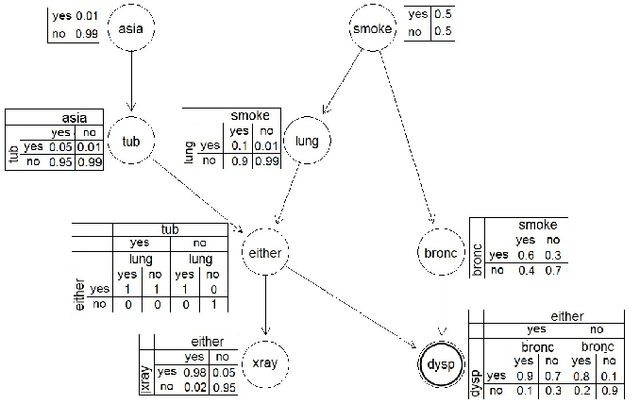
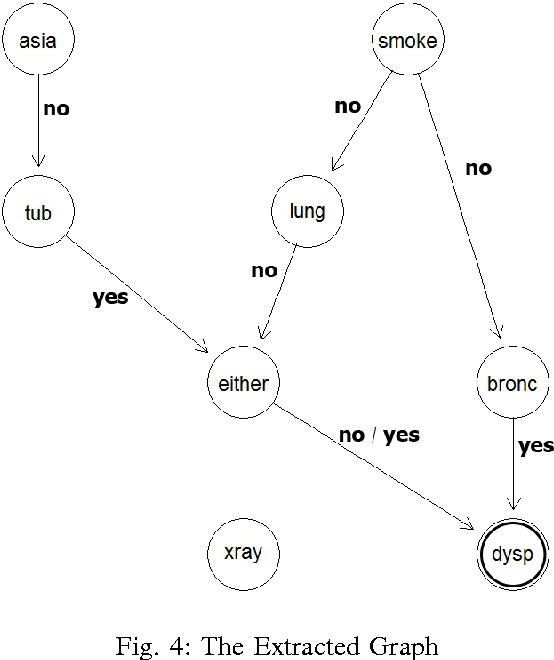
With the technology development, the need of analyze and extraction of useful information is increasing. Bayesian networks contain knowledge from data and experts that could be used for decision making processes But they are not easily understandable thus the rule extraction methods have been used but they have high computation costs. To overcome this problem we extract rules from Bayesian network using genetic algorithm. Then we generate the graphical chain by mutually matching the extracted rules and Bayesian network. This graphical chain could shows the sequence of events that lead to the target which could help the decision making process. The experimental results on small networks show that the proposed method has comparable results with brute force method which has a significantly higher computation cost.