 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeasible and Desirable Counterfactual Generation by Preserving Human Defined Constraints
Oct 12, 2022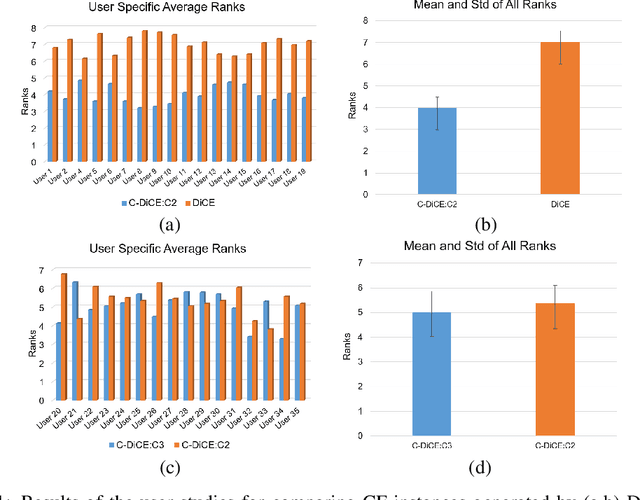
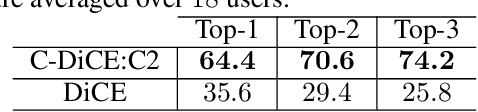
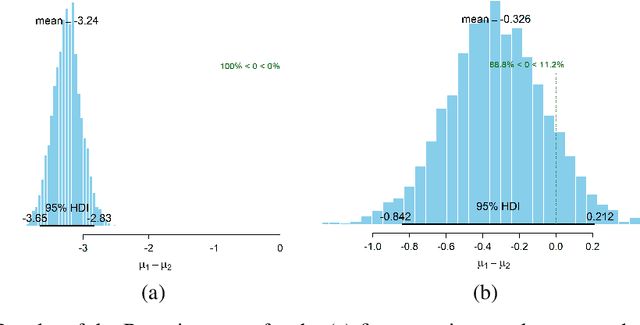
We present a human-in-the-loop approach to generate counterfactual (CF) explanations that preserve global and local feasibility constraints. Global feasibility constraints refer to the causal constraints that are necessary for generating actionable CF explanation. Assuming a domain expert with knowledge on unary and binary causal constraints, our approach efficiently employs this knowledge to generate CF explanation by rejecting gradient steps that violate these constraints. Local feasibility constraints encode end-user's constraints for generating desirable CF explanation. We extract these constraints from the end-user of the model and exploit them during CF generation via user-defined distance metric. Through user studies, we demonstrate that incorporating causal constraints during CF generation results in significantly better explanations in terms of feasibility and desirability for participants. Adopting local and global feasibility constraints simultaneously, although improves user satisfaction, does not significantly improve desirability of the participants compared to only incorporating global constraints.
Making Bayesian Predictive Models Interpretable: A Decision Theoretic Approach
Oct 21, 2019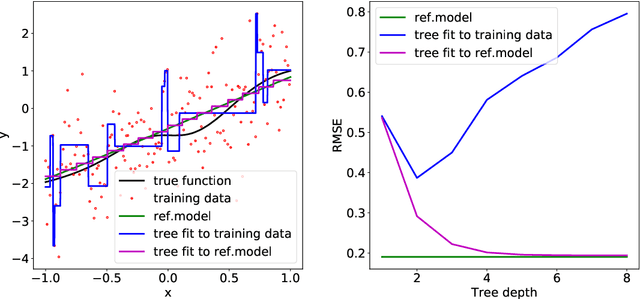
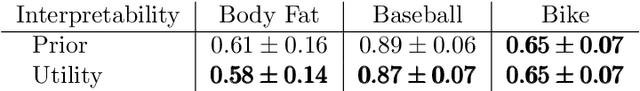
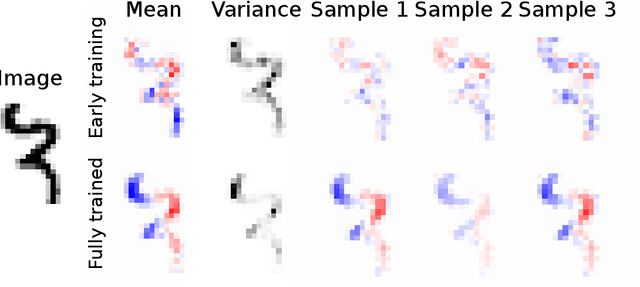
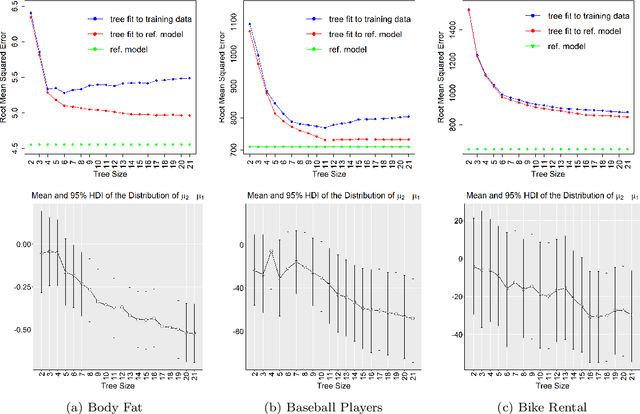
A salient approach to interpretable machine learning is to restrict modeling to simple and hence understandable models. In the Bayesian framework, this can be pursued by restricting the model structure and prior to favor interpretable models. Fundamentally, however, interpretability is about users' preferences, not the data generation mechanism: it is more natural to formulate interpretability as a utility function. In this work, we propose an interpretability utility, which explicates the trade-off between explanation fidelity and interpretability in the Bayesian framework. The method consists of two steps. First, a reference model, possibly a black-box Bayesian predictive model compromising no accuracy, is constructed and fitted to the training data. Second, a proxy model from an interpretable model family that best mimics the predictive behaviour of the reference model is found by optimizing the interpretability utility function. The approach is model agnostic - neither the interpretable model nor the reference model are restricted to be from a certain class of models - and the optimization problem can be solved using standard tools in the chosen model family. Through experiments on real-word data sets using decision trees as interpretable models and Bayesian additive regression models as reference models, we show that for the same level of interpretability, our approach generates more accurate models than the earlier alternative of restricting the prior. We also propose a systematic way to measure stabilities of interpretabile models constructed by different interpretability approaches and show that our proposed approach generates more stable models.
Human-in-the-loop Active Covariance Learning for Improving Prediction in Small Data Sets
Mar 18, 2019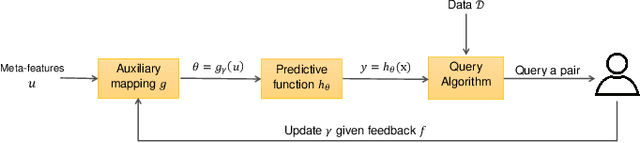
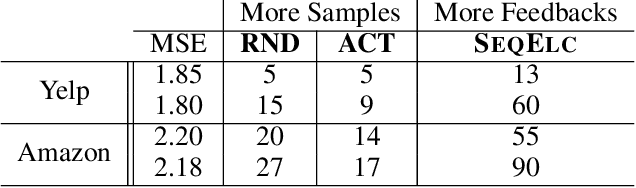
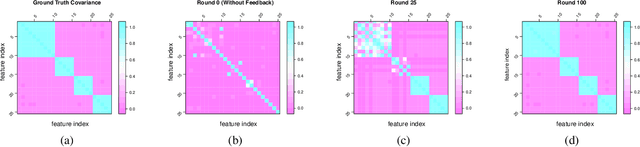
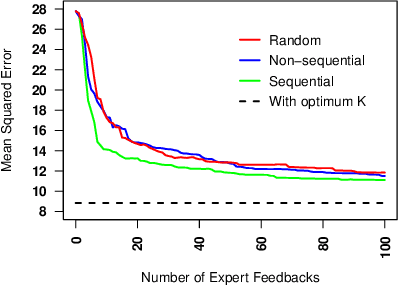
Learning predictive models from small high-dimensional data sets is a key problem in high-dimensional statistics. Expert knowledge elicitation can help, and a strong line of work focuses on directly eliciting informative prior distributions for parameters. This either requires considerable statistical expertise or is laborious, as the emphasis has been on accuracy and not on efficiency of the process. Another line of work queries about importance of features one at a time, assuming them to be independent and hence missing covariance information. In contrast, we propose eliciting expert knowledge about pairwise feature similarities, to borrow statistical strength in the predictions, and using sequential decision making techniques to minimize the effort of the expert. Empirical results demonstrate improvement in predictive performance on both simulated and real data, in high-dimensional linear regression tasks, where we learn the covariance structure with a Gaussian process, based on sequential elicitation.
Improving drug sensitivity predictions in precision medicine through active expert knowledge elicitation
May 09, 2017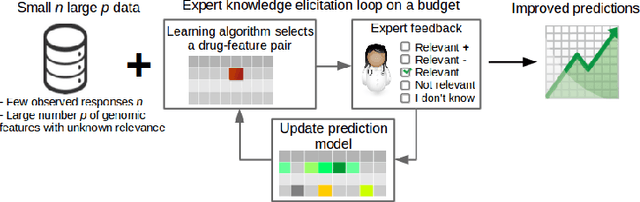

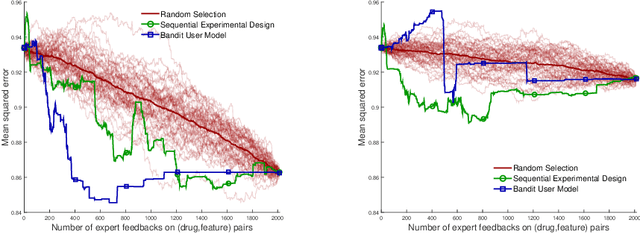

Predicting the efficacy of a drug for a given individual, using high-dimensional genomic measurements, is at the core of precision medicine. However, identifying features on which to base the predictions remains a challenge, especially when the sample size is small. Incorporating expert knowledge offers a promising alternative to improve a prediction model, but collecting such knowledge is laborious to the expert if the number of candidate features is very large. We introduce a probabilistic model that can incorporate expert feedback about the impact of genomic measurements on the sensitivity of a cancer cell for a given drug. We also present two methods to intelligently collect this feedback from the expert, using experimental design and multi-armed bandit models. In a multiple myeloma blood cancer data set (n=51), expert knowledge decreased the prediction error by 8%. Furthermore, the intelligent approaches can be used to reduce the workload of feedback collection to less than 30% on average compared to a naive approach.
Interactive Prior Elicitation of Feature Similarities for Small Sample Size Prediction
Feb 28, 2017
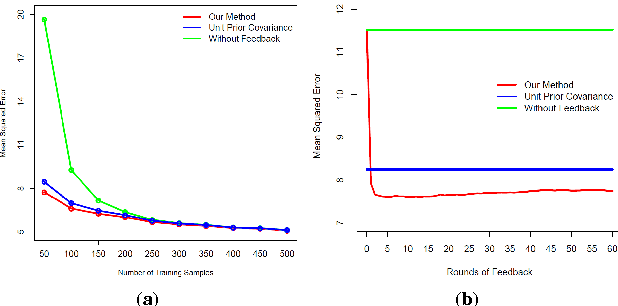
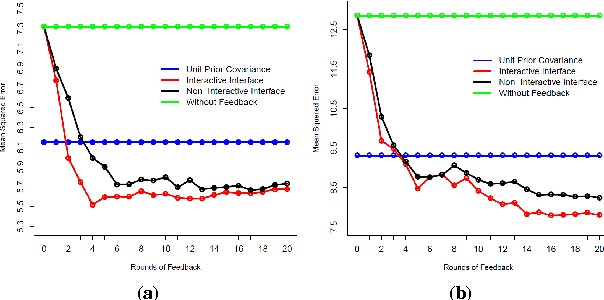
Regression under the "small $n$, large $p$" conditions, of small sample size $n$ and large number of features $p$ in the learning data set, is a recurring setting in which learning from data is difficult. With prior knowledge about relationships of the features, $p$ can effectively be reduced, but explicating such prior knowledge is difficult for experts. In this paper we introduce a new method for eliciting expert prior knowledge about the similarity of the roles of features in the prediction task. The key idea is to use an interactive multidimensional-scaling (MDS) type scatterplot display of the features to elicit the similarity relationships, and then use the elicited relationships in the prior distribution of prediction parameters. Specifically, for learning to predict a target variable with Bayesian linear regression, the feature relationships are used to construct a Gaussian prior with a full covariance matrix for the regression coefficients. Evaluation of our method in experiments with simulated and real users on text data confirm that prior elicitation of feature similarities improves prediction accuracy. Furthermore, elicitation with an interactive scatterplot display outperforms straightforward elicitation where the users choose feature pairs from a feature list.
An EM Based Probabilistic Two-Dimensional CCA with Application to Face Recognition
Feb 25, 2017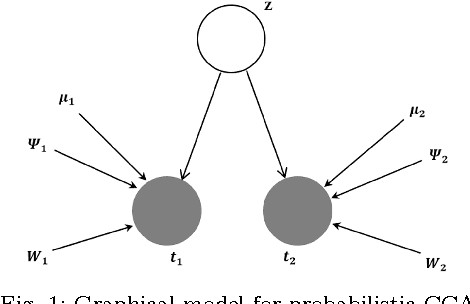
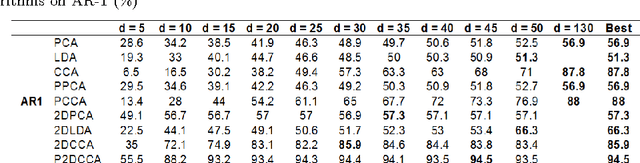

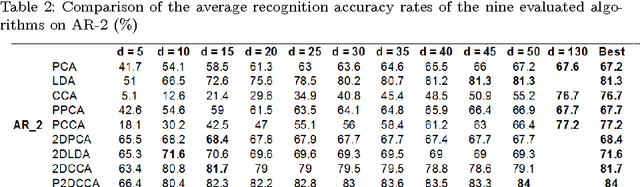
Recently, two-dimensional canonical correlation analysis (2DCCA) has been successfully applied for image feature extraction. The method instead of concatenating the columns of the images to the one-dimensional vectors, directly works with two-dimensional image matrices. Although 2DCCA works well in different recognition tasks, it lacks a probabilistic interpretation. In this paper, we present a probabilistic framework for 2DCCA called probabilistic 2DCCA (P2DCCA) and an iterative EM based algorithm for optimizing the parameters. Experimental results on synthetic and real data demonstrate superior performance in loading factor estimation for P2DCCA compared to 2DCCA. For real data, three subsets of AR face database and also the UMIST face database confirm the robustness of the proposed algorithm in face recognition tasks with different illumination conditions, facial expressions, poses and occlusions.
Fuzzy Least Squares Twin Support Vector Machines
Jul 22, 2016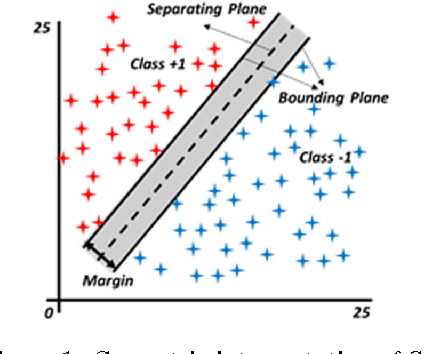

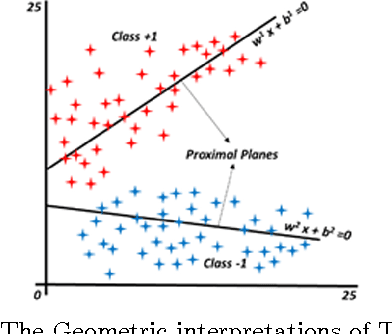
Least Squares Twin Support Vector Machine (LSTSVM) is an extremely efficient and fast version of SVM algorithm for binary classification. LSTSVM combines the idea of Least Squares SVM and Twin SVM in which two non-parallel hyperplanes are found by solving two systems of linear equations. Although the algorithm is very fast and efficient in many classification tasks, it is unable to cope with two features of real-world problems. First, in many real-world classification problems, it is almost impossible to assign data points to a single class. Second, data points in real-world problems may have different importance. In this study, we propose a novel version of LSTSVM based on fuzzy concepts to deal with these two characteristics of real-world data. The algorithm is called Fuzzy LSTSVM (FLSTSVM) which provides more flexibility than the binary classification of LSTSVM. Two models are proposed for the algorithm. In the first model, a fuzzy membership value is assigned to each data point and the hyperplanes are optimized based on these fuzzy samples. In the second model we construct fuzzy hyperplanes to classify data. Finally, we apply our proposed FLSTSVM to an artificial as well as three real-world datasets. Results demonstrate that FLSTSVM obtains better performance than SVM and LSTSVM.
Visualizations Relevant to The User By Multi-View Latent Variable Factorization
Jan 25, 2016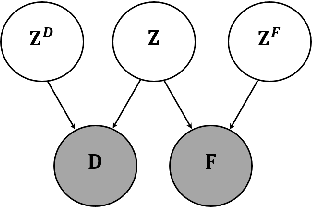
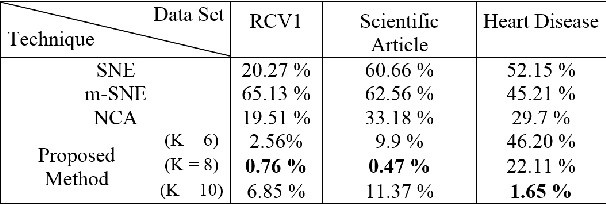
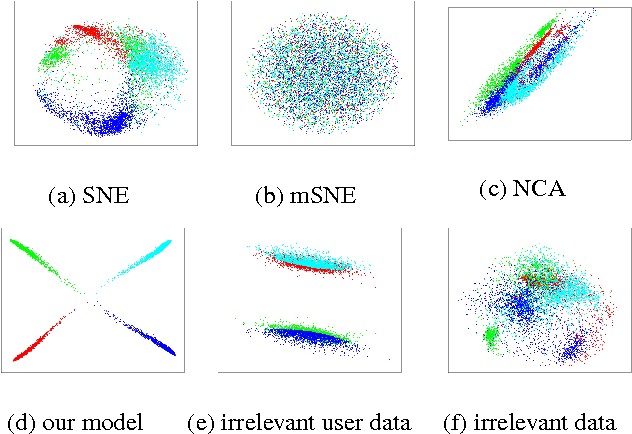
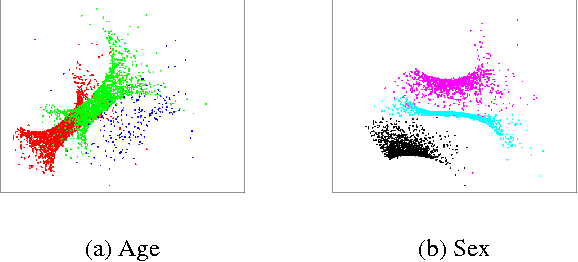
A main goal of data visualization is to find, from among all the available alternatives, mappings to the 2D/3D display which are relevant to the user. Assuming user interaction data, or other auxiliary data about the items or their relationships, the goal is to identify which aspects in the primary data support the user\'s input and, equally importantly, which aspects of the user\'s potentially noisy input have support in the primary data. For solving the problem, we introduce a multi-view embedding in which a latent factorization identifies which aspects in the two data views (primary data and user data) are related and which are specific to only one of them. The factorization is a generative model in which the display is parameterized as a part of the factorization and the other factors explain away the aspects not expressible in a two-dimensional display. Functioning of the model is demonstrated on several data sets.