 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStretching Each Dollar: Diffusion Training from Scratch on a Micro-Budget
Jul 22, 2024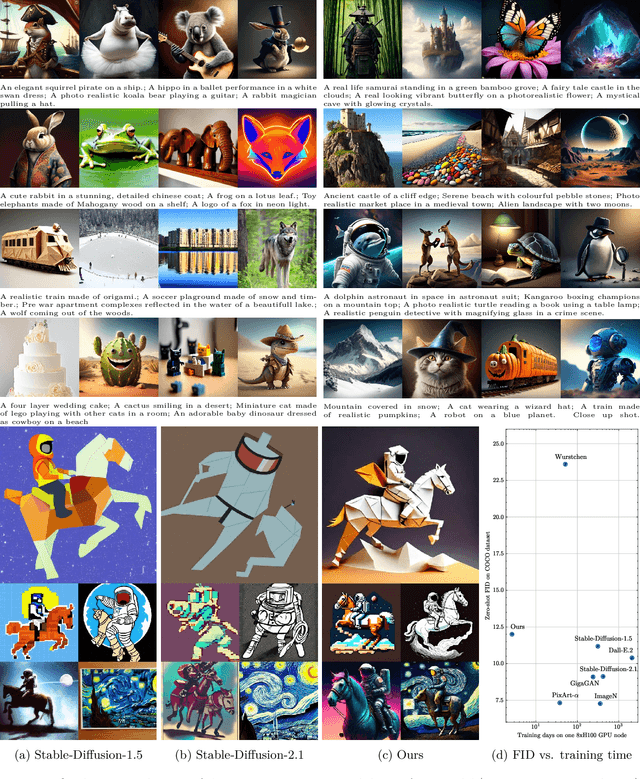
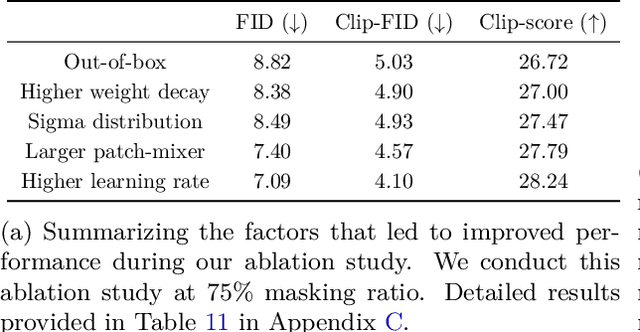
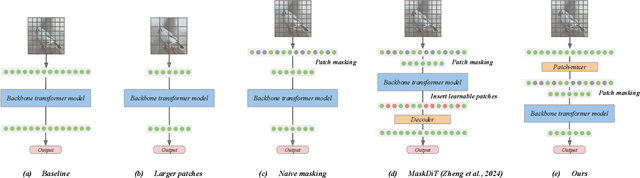

As scaling laws in generative AI push performance, they also simultaneously concentrate the development of these models among actors with large computational resources. With a focus on text-to-image (T2I) generative models, we aim to address this bottleneck by demonstrating very low-cost training of large-scale T2I diffusion transformer models. As the computational cost of transformers increases with the number of patches in each image, we propose to randomly mask up to 75% of the image patches during training. We propose a deferred masking strategy that preprocesses all patches using a patch-mixer before masking, thus significantly reducing the performance degradation with masking, making it superior to model downscaling in reducing computational cost. We also incorporate the latest improvements in transformer architecture, such as the use of mixture-of-experts layers, to improve performance and further identify the critical benefit of using synthetic images in micro-budget training. Finally, using only 37M publicly available real and synthetic images, we train a 1.16 billion parameter sparse transformer with only \$1,890 economical cost and achieve a 12.7 FID in zero-shot generation on the COCO dataset. Notably, our model achieves competitive FID and high-quality generations while incurring 118$\times$ lower cost than stable diffusion models and 14$\times$ lower cost than the current state-of-the-art approach that costs \$28,400. We aim to release our end-to-end training pipeline to further democratize the training of large-scale diffusion models on micro-budgets.
Is Synthetic Image Useful for Transfer Learning? An Investigation into Data Generation, Volume, and Utilization
Apr 02, 2024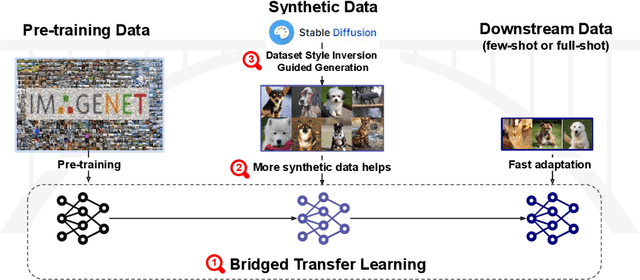
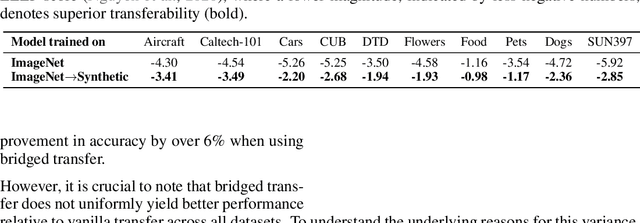
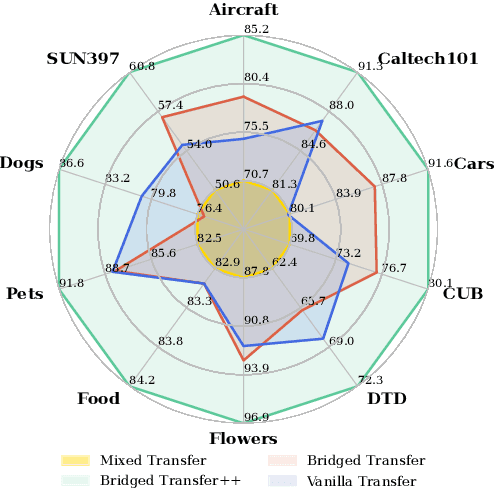

Synthetic image data generation represents a promising avenue for training deep learning models, particularly in the realm of transfer learning, where obtaining real images within a specific domain can be prohibitively expensive due to privacy and intellectual property considerations. This work delves into the generation and utilization of synthetic images derived from text-to-image generative models in facilitating transfer learning paradigms. Despite the high visual fidelity of the generated images, we observe that their naive incorporation into existing real-image datasets does not consistently enhance model performance due to the inherent distribution gap between synthetic and real images. To address this issue, we introduce a novel two-stage framework called bridged transfer, which initially employs synthetic images for fine-tuning a pre-trained model to improve its transferability and subsequently uses real data for rapid adaptation. Alongside, We propose dataset style inversion strategy to improve the stylistic alignment between synthetic and real images. Our proposed methods are evaluated across 10 different datasets and 5 distinct models, demonstrating consistent improvements, with up to 30% accuracy increase on classification tasks. Intriguingly, we note that the enhancements were not yet saturated, indicating that the benefits may further increase with an expanded volume of synthetic data.
Assessing SATNet's Ability to Solve the Symbol Grounding Problem
Dec 13, 2023SATNet is an award-winning MAXSAT solver that can be used to infer logical rules and integrated as a differentiable layer in a deep neural network. It had been shown to solve Sudoku puzzles visually from examples of puzzle digit images, and was heralded as an impressive achievement towards the longstanding AI goal of combining pattern recognition with logical reasoning. In this paper, we clarify SATNet's capabilities by showing that in the absence of intermediate labels that identify individual Sudoku digit images with their logical representations, SATNet completely fails at visual Sudoku (0% test accuracy). More generally, the failure can be pinpointed to its inability to learn to assign symbols to perceptual phenomena, also known as the symbol grounding problem, which has long been thought to be a prerequisite for intelligent agents to perform real-world logical reasoning. We propose an MNIST based test as an easy instance of the symbol grounding problem that can serve as a sanity check for differentiable symbolic solvers in general. Naive applications of SATNet on this test lead to performance worse than that of models without logical reasoning capabilities. We report on the causes of SATNet's failure and how to prevent them.
logLTN: Differentiable Fuzzy Logic in the Logarithm Space
Jun 26, 2023The AI community is increasingly focused on merging logic with deep learning to create Neuro-Symbolic (NeSy) paradigms and assist neural approaches with symbolic knowledge. A significant trend in the literature involves integrating axioms and facts in loss functions by grounding logical symbols with neural networks and operators with fuzzy semantics. Logic Tensor Networks (LTN) is one of the main representatives in this category, known for its simplicity, efficiency, and versatility. However, it has been previously shown that not all fuzzy operators perform equally when applied in a differentiable setting. Researchers have proposed several configurations of operators, trading off between effectiveness, numerical stability, and generalization to different formulas. This paper presents a configuration of fuzzy operators for grounding formulas end-to-end in the logarithm space. Our goal is to develop a configuration that is more effective than previous proposals, able to handle any formula, and numerically stable. To achieve this, we propose semantics that are best suited for the logarithm space and introduce novel simplifications and improvements that are crucial for optimization via gradient-descent. We use LTN as the framework for our experiments, but the conclusions of our work apply to any similar NeSy framework. Our findings, both formal and empirical, show that the proposed configuration outperforms the state-of-the-art and that each of our modifications is essential in achieving these results.
Outsourcing Training without Uploading Data via Efficient Collaborative Open-Source Sampling
Oct 23, 2022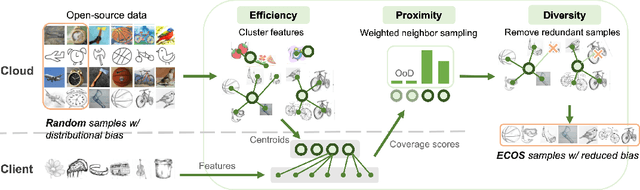
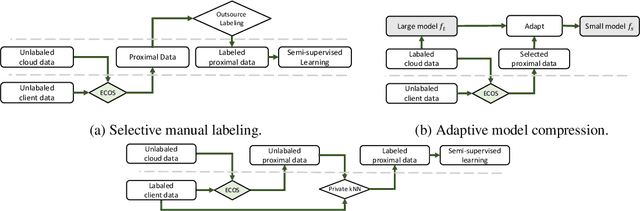
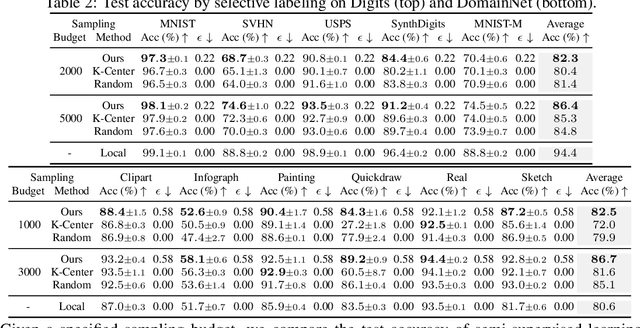
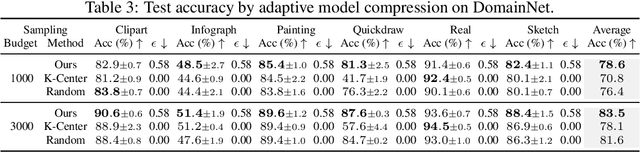
As deep learning blooms with growing demand for computation and data resources, outsourcing model training to a powerful cloud server becomes an attractive alternative to training at a low-power and cost-effective end device. Traditional outsourcing requires uploading device data to the cloud server, which can be infeasible in many real-world applications due to the often sensitive nature of the collected data and the limited communication bandwidth. To tackle these challenges, we propose to leverage widely available open-source data, which is a massive dataset collected from public and heterogeneous sources (e.g., Internet images). We develop a novel strategy called Efficient Collaborative Open-source Sampling (ECOS) to construct a proximal proxy dataset from open-source data for cloud training, in lieu of client data. ECOS probes open-source data on the cloud server to sense the distribution of client data via a communication- and computation-efficient sampling process, which only communicates a few compressed public features and client scalar responses. Extensive empirical studies show that the proposed ECOS improves the quality of automated client labeling, model compression, and label outsourcing when applied in various learning scenarios.
Feasible and Desirable Counterfactual Generation by Preserving Human Defined Constraints
Oct 12, 2022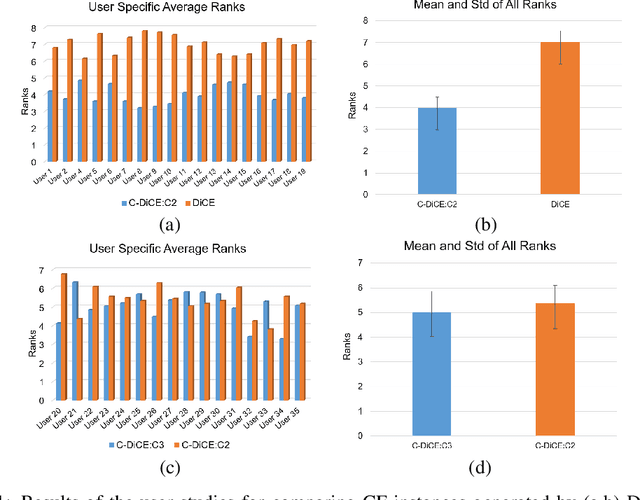
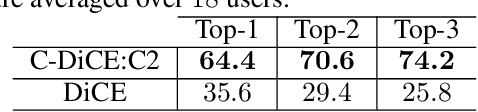
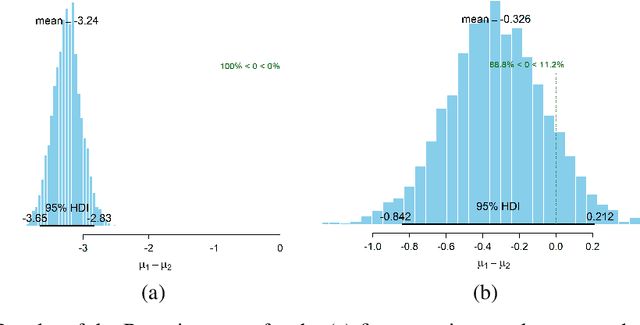
We present a human-in-the-loop approach to generate counterfactual (CF) explanations that preserve global and local feasibility constraints. Global feasibility constraints refer to the causal constraints that are necessary for generating actionable CF explanation. Assuming a domain expert with knowledge on unary and binary causal constraints, our approach efficiently employs this knowledge to generate CF explanation by rejecting gradient steps that violate these constraints. Local feasibility constraints encode end-user's constraints for generating desirable CF explanation. We extract these constraints from the end-user of the model and exploit them during CF generation via user-defined distance metric. Through user studies, we demonstrate that incorporating causal constraints during CF generation results in significantly better explanations in terms of feasibility and desirability for participants. Adopting local and global feasibility constraints simultaneously, although improves user satisfaction, does not significantly improve desirability of the participants compared to only incorporating global constraints.
MA-Dreamer: Coordination and communication through shared imagination
Apr 10, 2022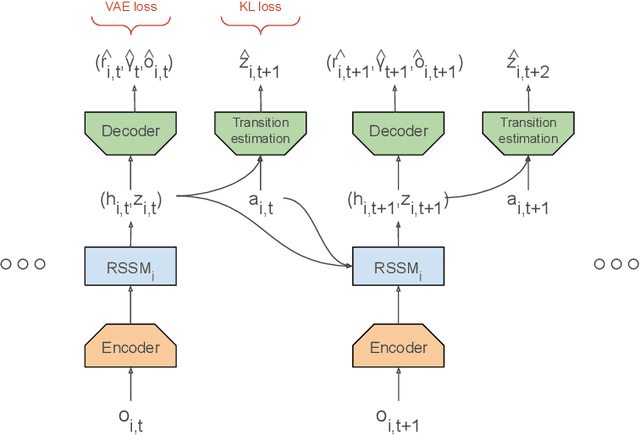

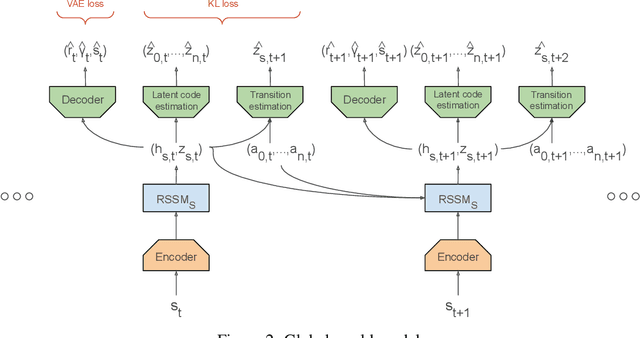

Multi-agent RL is rendered difficult due to the non-stationary nature of environment perceived by individual agents. Theoretically sound methods using the REINFORCE estimator are impeded by its high-variance, whereas value-function based methods are affected by issues stemming from their ad-hoc handling of situations like inter-agent communication. Methods like MADDPG are further constrained due to their requirement of centralized critics etc. In order to address these issues, we present MA-Dreamer, a model-based method that uses both agent-centric and global differentiable models of the environment in order to train decentralized agents' policies and critics using model-rollouts a.k.a `imagination'. Since only the model-training is done off-policy, inter-agent communication/coordination and `language emergence' can be handled in a straight-forward manner. We compare the performance of MA-Dreamer with other methods on two soccer-based games. Our experiments show that in long-term speaker-listener tasks and in cooperative games with strong partial-observability, MA-Dreamer finds a solution that makes effective use of coordination, whereas competing methods obtain marginal scores and fail outright, respectively. By effectively achieving coordination and communication under more relaxed and general conditions, out method opens the door to the study of more complex problems and population-based training.
Expert Human-Level Driving in Gran Turismo Sport Using Deep Reinforcement Learning with Image-based Representation
Nov 11, 2021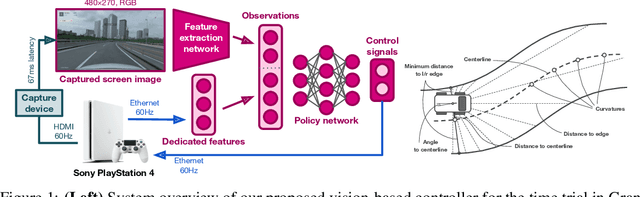

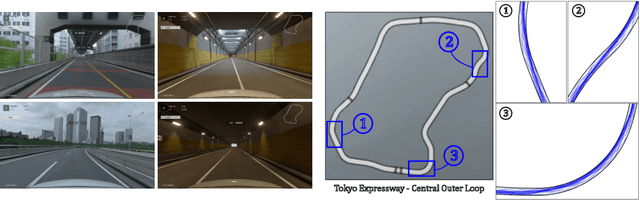
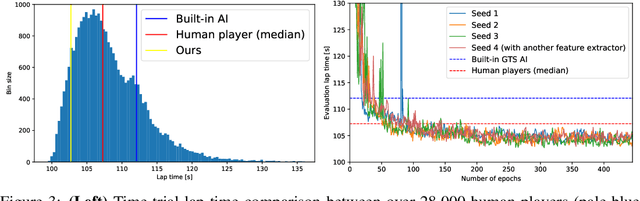
When humans play virtual racing games, they use visual environmental information on the game screen to understand the rules within the environments. In contrast, a state-of-the-art realistic racing game AI agent that outperforms human players does not use image-based environmental information but the compact and precise measurements provided by the environment. In this paper, a vision-based control algorithm is proposed and compared with human player performances under the same conditions in realistic racing scenarios using Gran Turismo Sport (GTS), which is known as a high-fidelity realistic racing simulator. In the proposed method, the environmental information that constitutes part of the observations in conventional state-of-the-art methods is replaced with feature representations extracted from game screen images. We demonstrate that the proposed method performs expert human-level vehicle control under high-speed driving scenarios even with game screen images as high-dimensional inputs. Additionally, it outperforms the built-in AI in GTS in a time trial task, and its score places it among the top 10% approximately 28,000 human players.
The Emergence of Abstract and Episodic Neurons in Episodic Meta-RL
Apr 07, 2021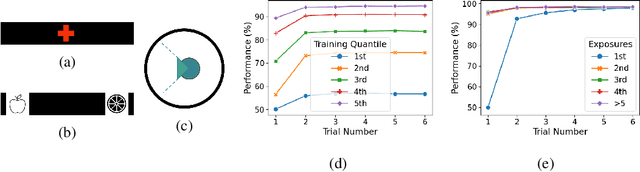
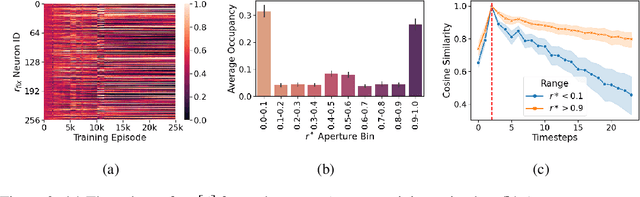
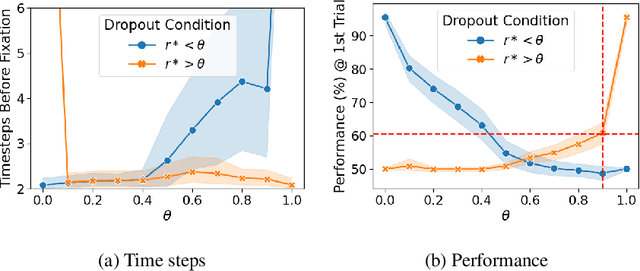
In this work, we analyze the reinstatement mechanism introduced by Ritter et al. (2018) to reveal two classes of neurons that emerge in the agent's working memory (an epLSTM cell) when trained using episodic meta-RL on an episodic variant of the Harlow visual fixation task. Specifically, Abstract neurons encode knowledge shared across tasks, while Episodic neurons carry information relevant for a specific episode's task.
Logic Tensor Networks
Jan 17, 2021



Artificial Intelligence agents are required to learn from their surroundings and to reason about the knowledge that has been learned in order to make decisions. While state-of-the-art learning from data typically uses sub-symbolic distributed representations, reasoning is normally useful at a higher level of abstraction with the use of a first-order logic language for knowledge representation. As a result, attempts at combining symbolic AI and neural computation into neural-symbolic systems have been on the increase. In this paper, we present Logic Tensor Networks (LTN), a neurosymbolic formalism and computational model that supports learning and reasoning through the introduction of a many-valued, end-to-end differentiable first-order logic called Real Logic as a representation language for deep learning. We show that LTN provides a uniform language for the specification and the computation of several AI tasks such as data clustering, multi-label classification, relational learning, query answering, semi-supervised learning, regression and embedding learning. We implement and illustrate each of the above tasks with a number of simple explanatory examples using TensorFlow 2. Keywords: Neurosymbolic AI, Deep Learning and Reasoning, Many-valued Logic.