 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMA-Dreamer: Coordination and communication through shared imagination
Apr 10, 2022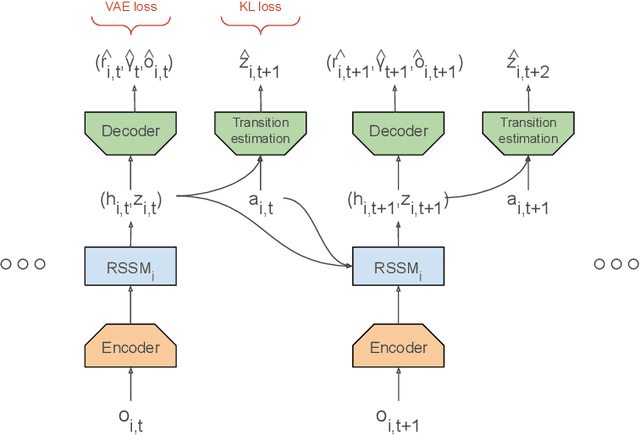

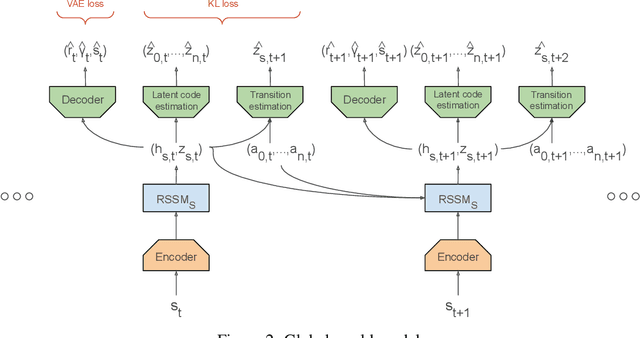

Multi-agent RL is rendered difficult due to the non-stationary nature of environment perceived by individual agents. Theoretically sound methods using the REINFORCE estimator are impeded by its high-variance, whereas value-function based methods are affected by issues stemming from their ad-hoc handling of situations like inter-agent communication. Methods like MADDPG are further constrained due to their requirement of centralized critics etc. In order to address these issues, we present MA-Dreamer, a model-based method that uses both agent-centric and global differentiable models of the environment in order to train decentralized agents' policies and critics using model-rollouts a.k.a `imagination'. Since only the model-training is done off-policy, inter-agent communication/coordination and `language emergence' can be handled in a straight-forward manner. We compare the performance of MA-Dreamer with other methods on two soccer-based games. Our experiments show that in long-term speaker-listener tasks and in cooperative games with strong partial-observability, MA-Dreamer finds a solution that makes effective use of coordination, whereas competing methods obtain marginal scores and fail outright, respectively. By effectively achieving coordination and communication under more relaxed and general conditions, out method opens the door to the study of more complex problems and population-based training.
Point Cloud Based Reinforcement Learning for Sim-to-Real and Partial Observability in Visual Navigation
Jul 27, 2020
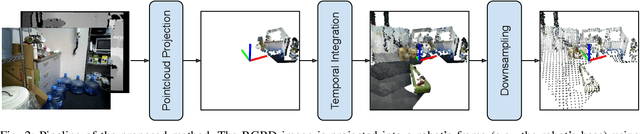
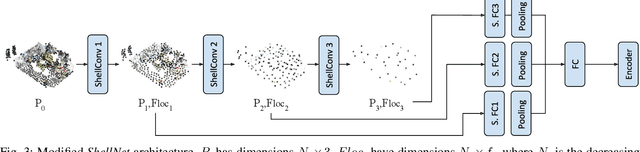
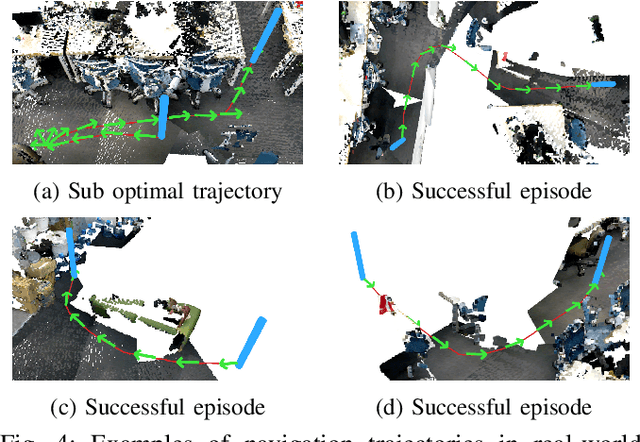
Reinforcement Learning (RL), among other learning-based methods, represents powerful tools to solve complex robotic tasks (e.g., actuation, manipulation, navigation, etc.), with the need for real-world data to train these systems as one of its most important limitations. The use of simulators is one way to address this issue, yet knowledge acquired in simulations does not work directly in the real-world, which is known as the sim-to-real transfer problem. While previous works focus on the nature of the images used as observations (e.g., textures and lighting), which has proven useful for a sim-to-sim transfer, they neglect other concerns regarding said observations, such as precise geometrical meanings, failing at robot-to-robot, and thus in sim-to-real transfers. We propose a method that learns on an observation space constructed by point clouds and environment randomization, generalizing among robots and simulators to achieve sim-to-real, while also addressing partial observability. We demonstrate the benefits of our methodology on the point goal navigation task, in which our method proves to be highly unaffected to unseen scenarios produced by robot-to-robot transfer, outperforms image-based baselines in robot-randomized experiments, and presents high performances in sim-to-sim conditions. Finally, we perform several experiments to validate the sim-to-real transfer to a physical domestic robot platform, confirming the out-of-the-box performance of our system.
Using Convolutional Neural Networks in Robots with Limited Computational Resources: Detecting NAO Robots while Playing Soccer
Jun 20, 2017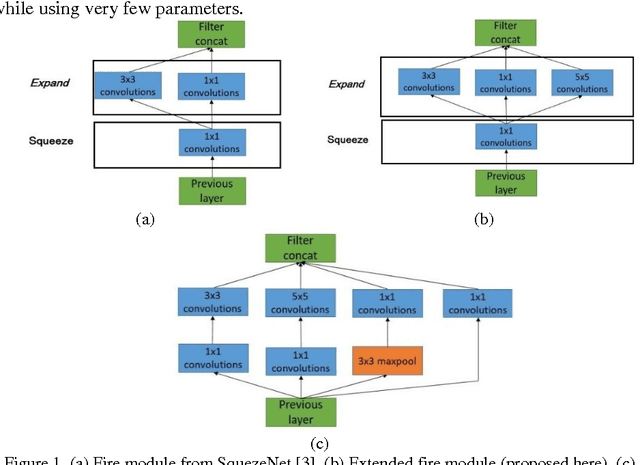
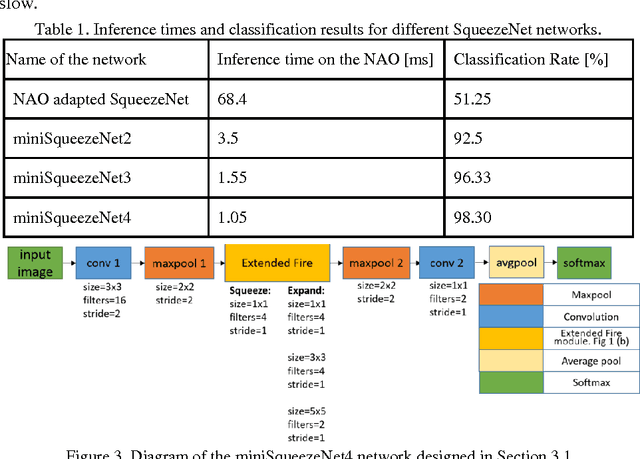
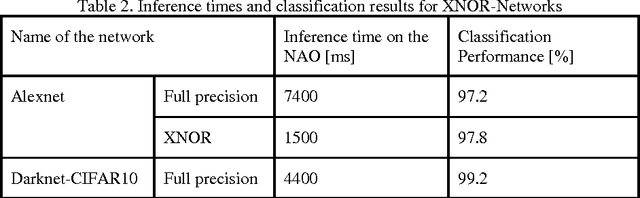
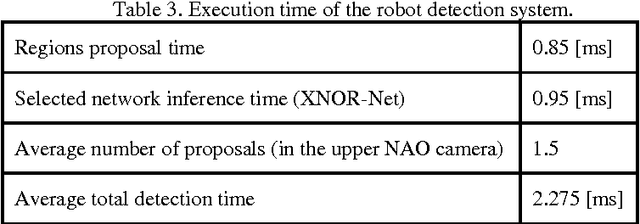
The main goal of this paper is to analyze the general problem of using Convolutional Neural Networks (CNNs) in robots with limited computational capabilities, and to propose general design guidelines for their use. In addition, two different CNN based NAO robot detectors that are able to run in real-time while playing soccer are proposed. One of the detectors is based on the XNOR-Net and the other on the SqueezeNet. Each detector is able to process a robot object-proposal in ~1ms, with an average number of 1.5 proposals per frame obtained by the upper camera of the NAO. The obtained detection rate is ~97%.
Toward Real-Time Decentralized Reinforcement Learning using Finite Support Basis Functions
Jun 20, 2017
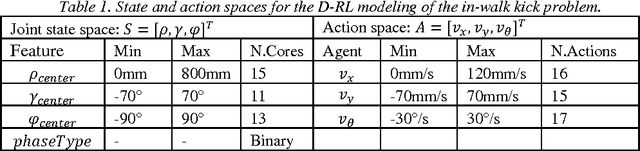

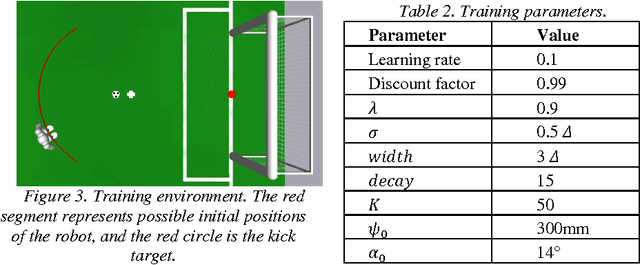
This paper addresses the design and implementation of complex Reinforcement Learning (RL) behaviors where multi-dimensional action spaces are involved, as well as the need to execute the behaviors in real-time using robotic platforms with limited computational resources and training times. For this purpose, we propose the use of decentralized RL, in combination with finite support basis functions as alternatives to Gaussian RBF, in order to alleviate the effects of the curse of dimensionality on the action and state spaces respectively, and to reduce the computation time. As testbed, a RL based controller for the in-walk kick in NAO robots, a challenging and critical problem for soccer robotics, is used. The reported experiments show empirically that our solution saves up to 99.94% of execution time and 98.82% of memory consumption during execution, without diminishing performance compared to classical approaches.