 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePUAD: Frustratingly Simple Method for Robust Anomaly Detection
Feb 23, 2024Developing an accurate and fast anomaly detection model is an important task in real-time computer vision applications. There has been much research to develop a single model that detects either structural or logical anomalies, which are inherently distinct. The majority of the existing approaches implicitly assume that the anomaly can be represented by identifying the anomalous location. However, we argue that logical anomalies, such as the wrong number of objects, can not be well-represented by the spatial feature maps and require an alternative approach. In addition, we focused on the possibility of detecting logical anomalies by using an out-of-distribution detection approach on the feature space, which aggregates the spatial information of the feature map. As a demonstration, we propose a method that incorporates a simple out-of-distribution detection method on the feature space against state-of-the-art reconstruction-based approaches. Despite the simplicity of our proposal, our method PUAD (Picturable and Unpicturable Anomaly Detection) achieves state-of-the-art performance on the MVTec LOCO AD dataset.
Expert Human-Level Driving in Gran Turismo Sport Using Deep Reinforcement Learning with Image-based Representation
Nov 11, 2021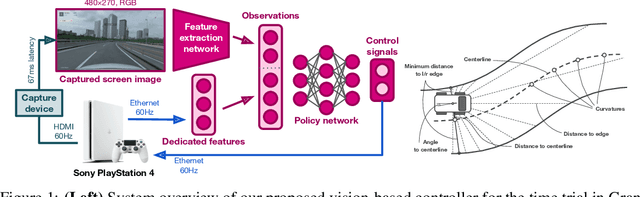

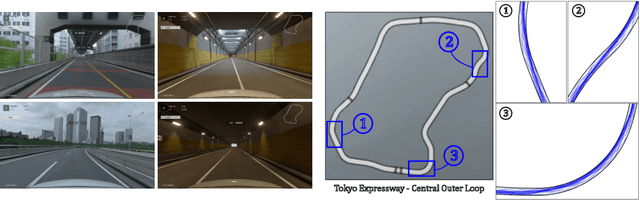
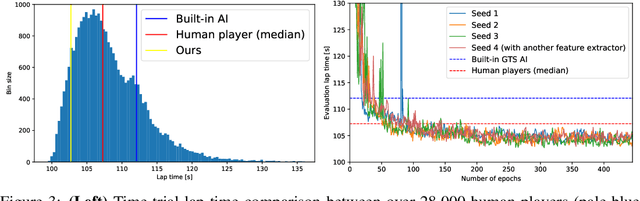
When humans play virtual racing games, they use visual environmental information on the game screen to understand the rules within the environments. In contrast, a state-of-the-art realistic racing game AI agent that outperforms human players does not use image-based environmental information but the compact and precise measurements provided by the environment. In this paper, a vision-based control algorithm is proposed and compared with human player performances under the same conditions in realistic racing scenarios using Gran Turismo Sport (GTS), which is known as a high-fidelity realistic racing simulator. In the proposed method, the environmental information that constitutes part of the observations in conventional state-of-the-art methods is replaced with feature representations extracted from game screen images. We demonstrate that the proposed method performs expert human-level vehicle control under high-speed driving scenarios even with game screen images as high-dimensional inputs. Additionally, it outperforms the built-in AI in GTS in a time trial task, and its score places it among the top 10% approximately 28,000 human players.
MLF-SC: Incorporating multi-layer features to sparse coding for anomaly detection
Apr 09, 2021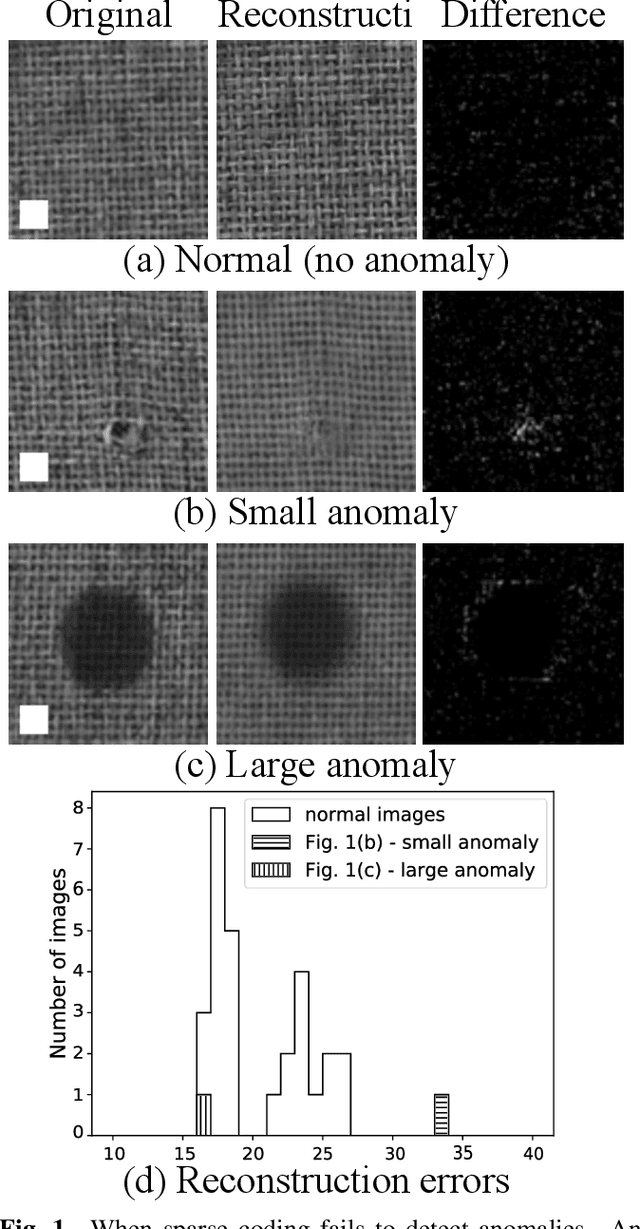
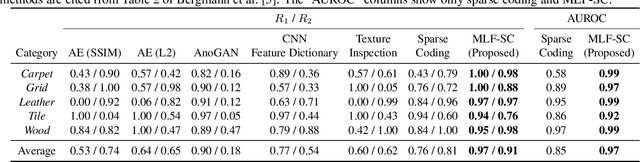
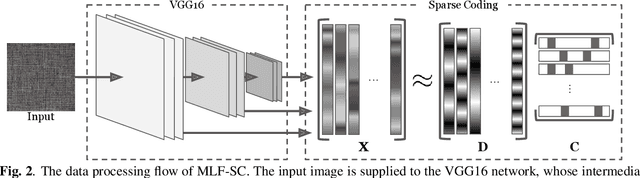

Anomalies in images occur in various scales from a small hole on a carpet to a large stain. However, anomaly detection based on sparse coding, one of the widely used anomaly detection methods, has an issue in dealing with anomalies that are out of the patch size employed to sparsely represent images. A large anomaly can be considered normal if seen in a small scale, but it is not easy to determine a single scale (patch size) that works well for all images. Then, we propose to incorporate multi-scale features to sparse coding and improve the performance of anomaly detection. The proposed method, multi-layer feature sparse coding (MLF-SC), employs a neural network for feature extraction, and feature maps from intermediate layers of the network are given to sparse coding, whereas the standard sparse-coding-based anomaly detection method directly works on given images. We show that MLF-SC outperforms state-of-the-art anomaly detection methods including those employing deep learning. Our target data are the texture categories of the MVTec Anomaly Detection (MVTec AD) dataset, which is a modern benchmark dataset consisting of images from the real world. Our idea can be a simple and practical option to deal with practical data.
Self-supervised Hyperspectral Image Restoration using Separable Image Prior
Jul 01, 2019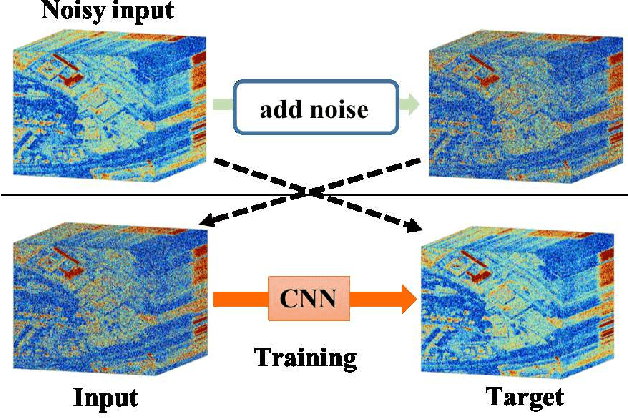
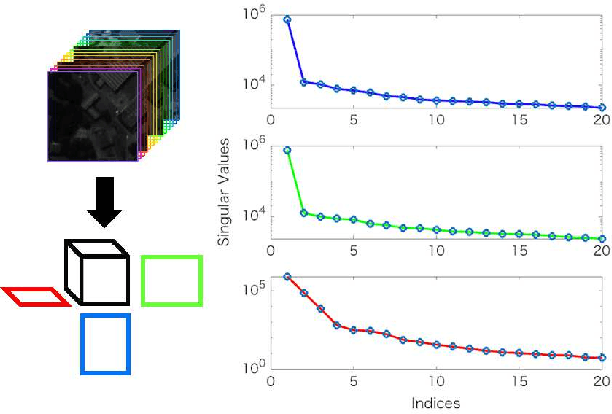
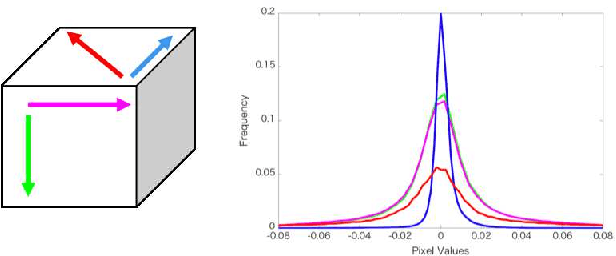
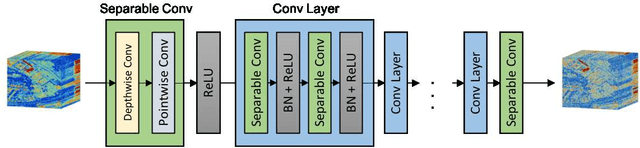
Supervised learning with a convolutional neural network is recognized as a powerful means of image restoration. However, most such methods have been designed for application to grayscale and/or color images; therefore, they have limited success when applied to hyperspectral image restoration. This is partially owing to large datasets being difficult to collect, and also the heavy computational load associated with the restoration of an image with many spectral bands. To address this difficulty, we propose a novel self-supervised learning strategy for application to hyperspectral image restoration. Our method automatically creates a training dataset from a single degraded image and trains a denoising network without any clear images. Another notable feature of our method is the use of a separable convolutional layer. We undertake experiments to prove that the use of a separable network allows us to acquire the prior of a hyperspectral image and to realize efficient restoration. We demonstrate the validity of our method through extensive experiments and show that our method has better characteristics than those that are currently regarded as state-of-the-art.