 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying and Inducing Shape Bias in CNNs via Max-Pool Dilation
Jan 09, 2026Convolutional Neural Networks (CNNs) are known to exhibit a strong texture bias, favoring local patterns over global shape information--a tendency inherent to their convolutional architecture. While this bias is beneficial for texture-rich natural images, it often degrades performance on shape-dominant data such as illustrations and sketches. Although prior work has proposed shape-biased models to mitigate this issue, these approaches lack a quantitative metric for identifying which datasets would actually benefit from such modifications. To address this gap, we propose a data-driven metric that quantifies the shape-texture balance of a dataset by computing the Structural Similarity Index (SSIM) between each image's luminance channel and its L0-smoothed counterpart. Building on this metric, we further introduce a computationally efficient adaptation method that promotes shape bias by modifying the dilation of max-pooling operations while keeping convolutional weights frozen. Experimental results show that this approach consistently improves classification accuracy on shape-dominant datasets, particularly in low-data regimes where full fine-tuning is impractical, requiring training only the final classification layer.
Improving Semi-Supervised Contrastive Learning via Entropy-Weighted Confidence Integration of Anchor-Positive Pairs
Jan 08, 2026Conventional semi-supervised contrastive learning methods assign pseudo-labels only to samples whose highest predicted class probability exceeds a predefined threshold, and then perform supervised contrastive learning using those selected samples. In this study, we propose a novel loss function that estimates the confidence of each sample based on the entropy of its predicted probability distribution and applies confidence-based adaptive weighting. This approach enables pseudo-label assignment even to samples that were previously excluded from training and facilitates contrastive learning that accounts for the confidence of both anchor and positive samples in a more principled manner. Experimental results demonstrate that the proposed method improves classification accuracy and achieves more stable learning performance even under low-label conditions.
Skeletonization-Based Adversarial Perturbations on Large Vision Language Model's Mathematical Text Recognition
Jan 08, 2026This work explores the visual capabilities and limitations of foundation models by introducing a novel adversarial attack method utilizing skeletonization to reduce the search space effectively. Our approach specifically targets images containing text, particularly mathematical formula images, which are more challenging due to their LaTeX conversion and intricate structure. We conduct a detailed evaluation of both character and semantic changes between original and adversarially perturbed outputs to provide insights into the models' visual interpretation and reasoning abilities. The effectiveness of our method is further demonstrated through its application to ChatGPT, which shows its practical implications in real-world scenarios.
* accepted to ITC-CSCC 2025
Integrating Distribution Matching into Semi-Supervised Contrastive Learning for Labeled and Unlabeled Data
Jan 08, 2026The advancement of deep learning has greatly improved supervised image classification. However, labeling data is costly, prompting research into unsupervised learning methods such as contrastive learning. In real-world scenarios, fully unlabeled datasets are rare, making semi-supervised learning (SSL) highly relevant in scenarios where a small amount of labeled data coexists with a large volume of unlabeled data. A well-known semi-supervised contrastive learning approach involves assigning pseudo-labels to unlabeled data. This study aims to enhance pseudo-label-based SSL by incorporating distribution matching between labeled and unlabeled feature embeddings to improve image classification accuracy across multiple datasets.
* ITC-CSCC accepted
Clustering of illustrations by atmosphere using a combination of supervised and unsupervised learning
Jul 27, 2023



The distribution of illustrations on social media, such as Twitter and Pixiv has increased with the growing popularity of animation, games, and animated movies. The "atmosphere" of illustrations plays an important role in user preferences. Classifying illustrations by atmosphere can be helpful for recommendations and searches. However, assigning clear labels to the elusive "atmosphere" and conventional supervised classification is not always practical. Furthermore, even images with similar colors, edges, and low-level features may not have similar atmospheres, making classification based on low-level features challenging. In this paper, this problem is solved using both supervised and unsupervised learning with pseudo-labels. The feature vectors are obtained using the supervised method with pseudo-labels that contribute to an ambiguous atmosphere. Further, clustering is performed based on these feature vectors. Experimental analyses show that our method outperforms conventional methods in human-like clustering on datasets manually classified by humans.
Guided Facial Skin Color Correction
May 19, 2021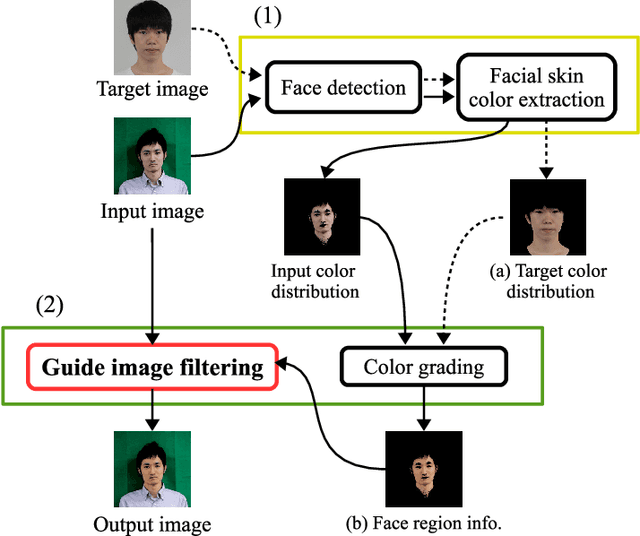



This paper proposes an automatic image correction method for portrait photographs, which promotes consistency of facial skin color by suppressing skin color changes due to background colors. In portrait photographs, skin color is often distorted due to the lighting environment (e.g., light reflected from a colored background wall and over-exposure by a camera strobe), and if the photo is artificially combined with another background color, this color change is emphasized, resulting in an unnatural synthesized result. In our framework, after roughly extracting the face region and rectifying the skin color distribution in a color space, we perform color and brightness correction around the face in the original image to achieve a proper color balance of the facial image, which is not affected by luminance and background colors. Unlike conventional algorithms for color correction, our final result is attained by a color correction process with a guide image. In particular, our guided image filtering for the color correction does not require a perfectly-aligned guide image required in the original guide image filtering method proposed by He et al. Experimental results show that our method generates more natural results than conventional methods on not only headshot photographs but also natural scene photographs. We also show automatic yearbook style photo generation as an another application.
Self-supervised Hyperspectral Image Restoration using Separable Image Prior
Jul 01, 2019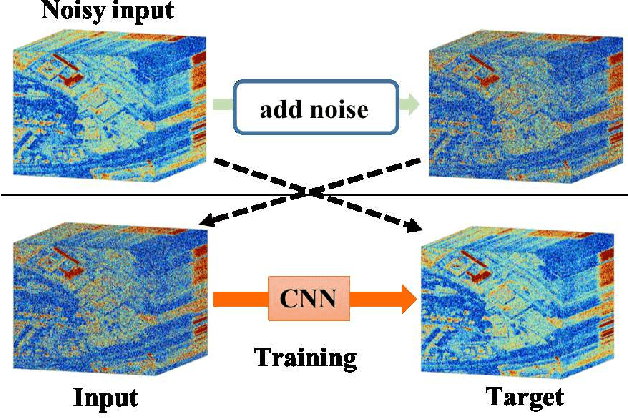
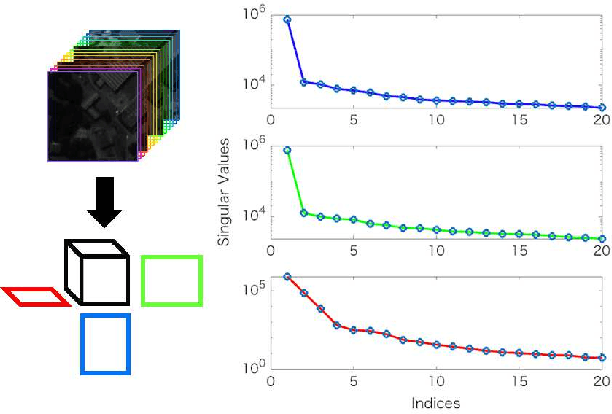
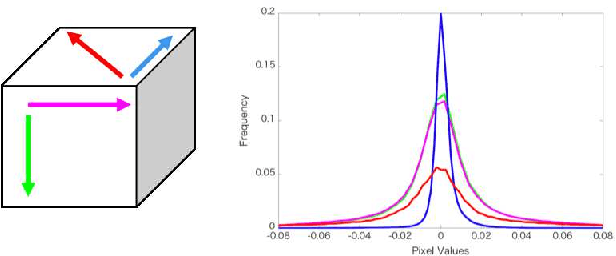
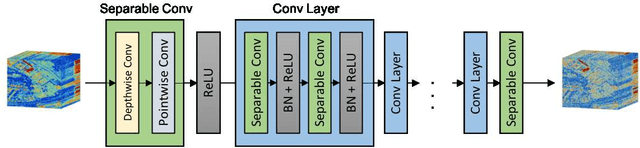
Supervised learning with a convolutional neural network is recognized as a powerful means of image restoration. However, most such methods have been designed for application to grayscale and/or color images; therefore, they have limited success when applied to hyperspectral image restoration. This is partially owing to large datasets being difficult to collect, and also the heavy computational load associated with the restoration of an image with many spectral bands. To address this difficulty, we propose a novel self-supervised learning strategy for application to hyperspectral image restoration. Our method automatically creates a training dataset from a single degraded image and trains a denoising network without any clear images. Another notable feature of our method is the use of a separable convolutional layer. We undertake experiments to prove that the use of a separable network allows us to acquire the prior of a hyperspectral image and to realize efficient restoration. We demonstrate the validity of our method through extensive experiments and show that our method has better characteristics than those that are currently regarded as state-of-the-art.