 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel Embedding: Fully Quantized Convolutional Neural Network with Differentiable Lookup Table
Jul 23, 2024By quantizing network weights and activations to low bitwidth, we can obtain hardware-friendly and energy-efficient networks. However, existing quantization techniques utilizing the straight-through estimator and piecewise constant functions face the issue of how to represent originally high-bit input data with low-bit values. To fully quantize deep neural networks, we propose pixel embedding, which replaces each float-valued input pixel with a vector of quantized values by using a lookup table. The lookup table or low-bit representation of pixels is differentiable and trainable by backpropagation. Such replacement of inputs with vectors is similar to word embedding in the natural language processing field. Experiments on ImageNet and CIFAR-100 show that pixel embedding reduces the top-5 error gap caused by quantizing the floating points at the first layer to only 1% for the ImageNet dataset, and the top-1 error gap caused by quantizing first and last layers to slightly over 1% for the CIFAR-100 dataset. The usefulness of pixel embedding is further demonstrated by inference time measurements, which demonstrate over 1.7 times speedup compared to floating point precision first layer.
MLF-SC: Incorporating multi-layer features to sparse coding for anomaly detection
Apr 09, 2021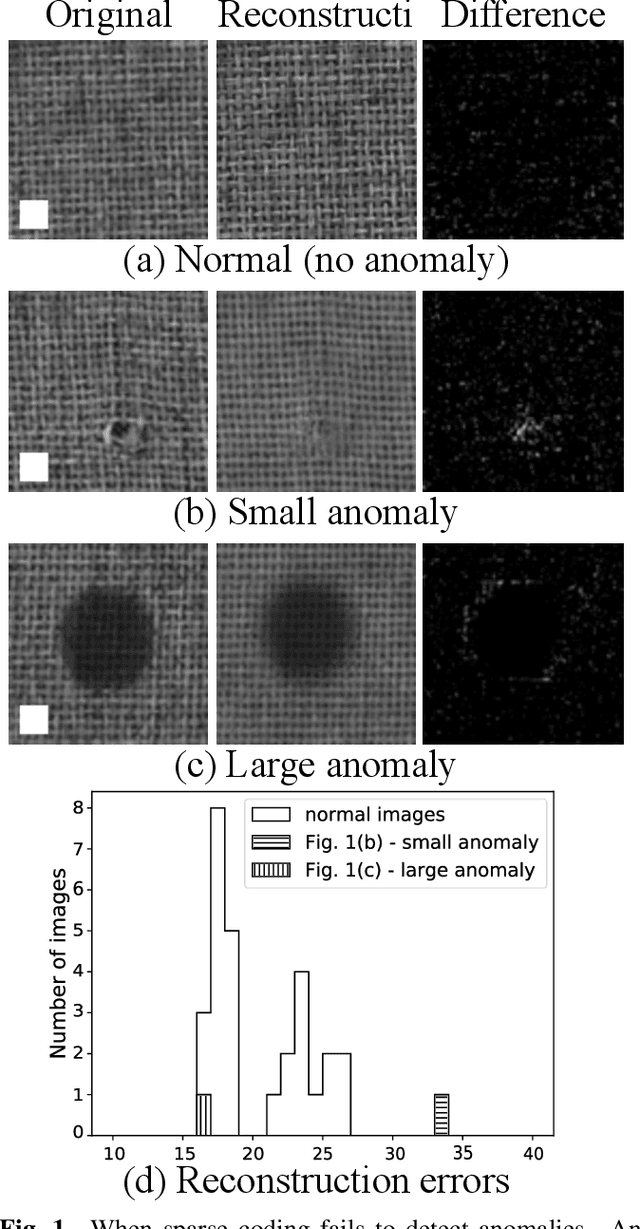
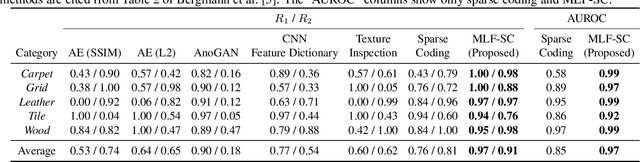
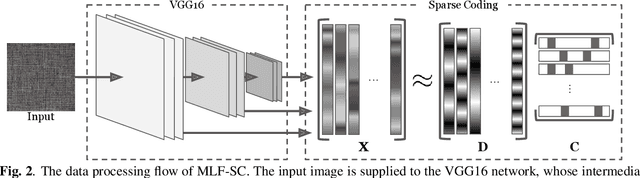

Anomalies in images occur in various scales from a small hole on a carpet to a large stain. However, anomaly detection based on sparse coding, one of the widely used anomaly detection methods, has an issue in dealing with anomalies that are out of the patch size employed to sparsely represent images. A large anomaly can be considered normal if seen in a small scale, but it is not easy to determine a single scale (patch size) that works well for all images. Then, we propose to incorporate multi-scale features to sparse coding and improve the performance of anomaly detection. The proposed method, multi-layer feature sparse coding (MLF-SC), employs a neural network for feature extraction, and feature maps from intermediate layers of the network are given to sparse coding, whereas the standard sparse-coding-based anomaly detection method directly works on given images. We show that MLF-SC outperforms state-of-the-art anomaly detection methods including those employing deep learning. Our target data are the texture categories of the MVTec Anomaly Detection (MVTec AD) dataset, which is a modern benchmark dataset consisting of images from the real world. Our idea can be a simple and practical option to deal with practical data.
Node Centralities and Classification Performance for Characterizing Node Embedding Algorithms
Feb 18, 2018
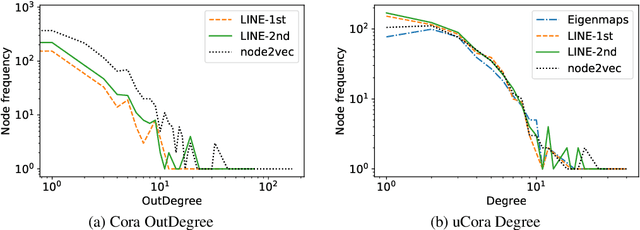

Embedding graph nodes into a vector space can allow the use of machine learning to e.g. predict node classes, but the study of node embedding algorithms is immature compared to the natural language processing field because of a diverse nature of graphs. We examine the performance of node embedding algorithms with respect to graph centrality measures that characterize diverse graphs, through systematic experiments with four node embedding algorithms, four or five graph centralities, and six datasets. Experimental results give insights into the properties of node embedding algorithms, which can be a basis for further research on this topic.
Neural Sequence Model Training via $α$-divergence Minimization
Jun 30, 2017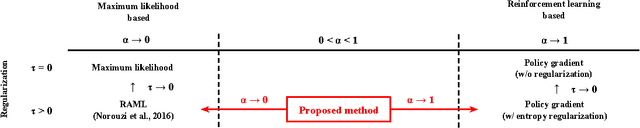

We propose a new neural sequence model training method in which the objective function is defined by $\alpha$-divergence. We demonstrate that the objective function generalizes the maximum-likelihood (ML)-based and reinforcement learning (RL)-based objective functions as special cases (i.e., ML corresponds to $\alpha \to 0$ and RL to $\alpha \to1$). We also show that the gradient of the objective function can be considered a mixture of ML- and RL-based objective gradients. The experimental results of a machine translation task show that minimizing the objective function with $\alpha > 0$ outperforms $\alpha \to 0$, which corresponds to ML-based methods.