 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLaMo 2 Technical Report
Sep 05, 2025In this report, we introduce PLaMo 2, a series of Japanese-focused large language models featuring a hybrid Samba-based architecture that transitions to full attention via continual pre-training to support 32K token contexts. Training leverages extensive synthetic corpora to overcome data scarcity, while computational efficiency is achieved through weight reuse and structured pruning. This efficient pruning methodology produces an 8B model that achieves performance comparable to our previous 100B model. Post-training further refines the models using a pipeline of supervised fine-tuning (SFT) and direct preference optimization (DPO), enhanced by synthetic Japanese instruction data and model merging techniques. Optimized for inference using vLLM and quantization with minimal accuracy loss, the PLaMo 2 models achieve state-of-the-art results on Japanese benchmarks, outperforming similarly-sized open models in instruction-following, language fluency, and Japanese-specific knowledge.
Enhancing Large Language Model-based Speech Recognition by Contextualization for Rare and Ambiguous Words
Aug 15, 2024We develop a large language model (LLM) based automatic speech recognition (ASR) system that can be contextualized by providing keywords as prior information in text prompts. We adopt decoder-only architecture and use our in-house LLM, PLaMo-100B, pre-trained from scratch using datasets dominated by Japanese and English texts as the decoder. We adopt a pre-trained Whisper encoder as an audio encoder, and the audio embeddings from the audio encoder are projected to the text embedding space by an adapter layer and concatenated with text embeddings converted from text prompts to form inputs to the decoder. By providing keywords as prior information in the text prompts, we can contextualize our LLM-based ASR system without modifying the model architecture to transcribe ambiguous words in the input audio accurately. Experimental results demonstrate that providing keywords to the decoder can significantly improve the recognition performance of rare and ambiguous words.
Empirical Evaluation and Theoretical Analysis for Representation Learning: A Survey
Apr 18, 2022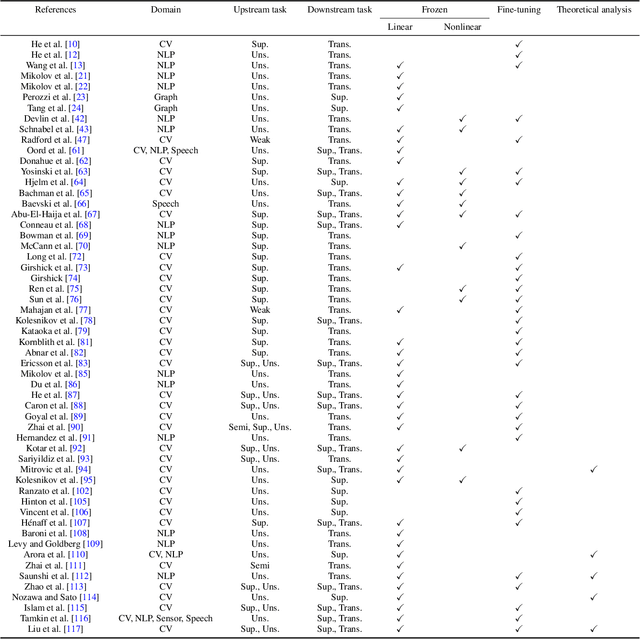
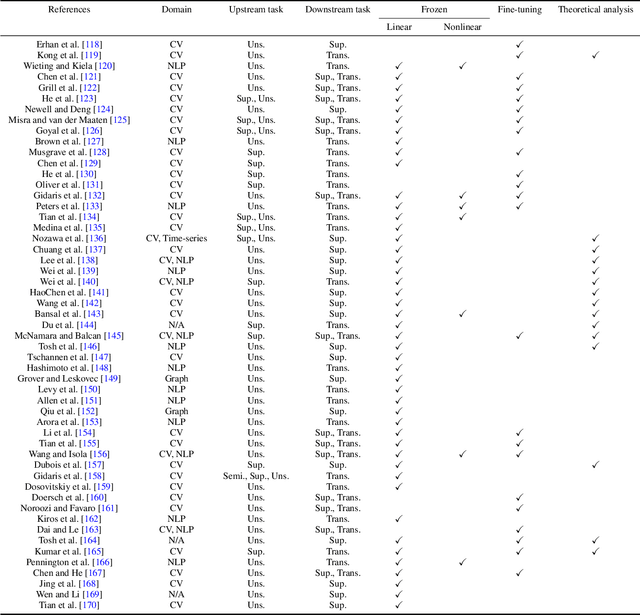
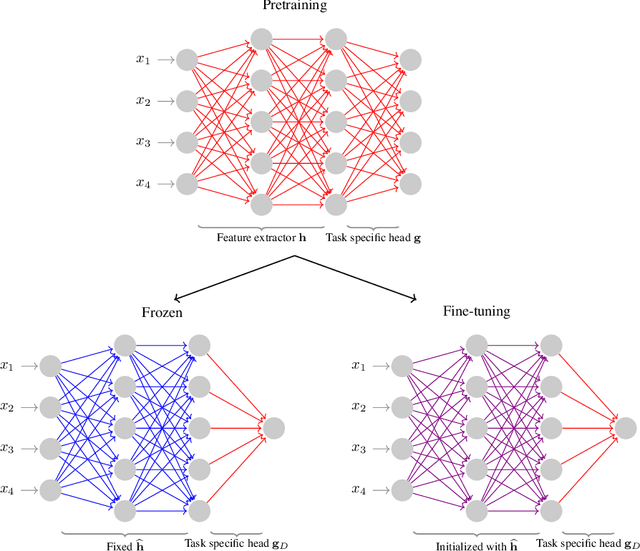

Representation learning enables us to automatically extract generic feature representations from a dataset to solve another machine learning task. Recently, extracted feature representations by a representation learning algorithm and a simple predictor have exhibited state-of-the-art performance on several machine learning tasks. Despite its remarkable progress, there exist various ways to evaluate representation learning algorithms depending on the application because of the flexibility of representation learning. To understand the current representation learning, we review evaluation methods of representation learning algorithms and theoretical analyses. On the basis of our evaluation survey, we also discuss the future direction of representation learning. Note that this survey is the extended version of Nozawa and Sato (2022).
Sharp Learning Bounds for Contrastive Unsupervised Representation Learning
Oct 06, 2021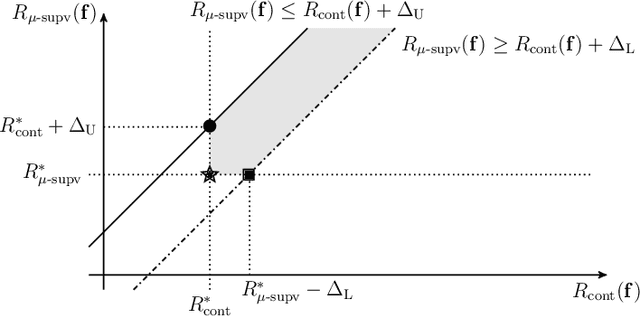
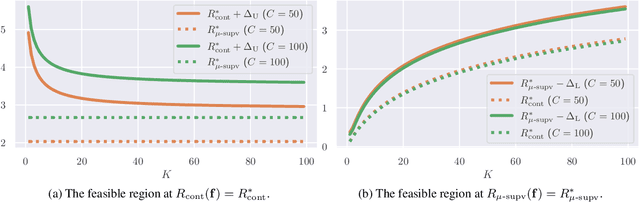
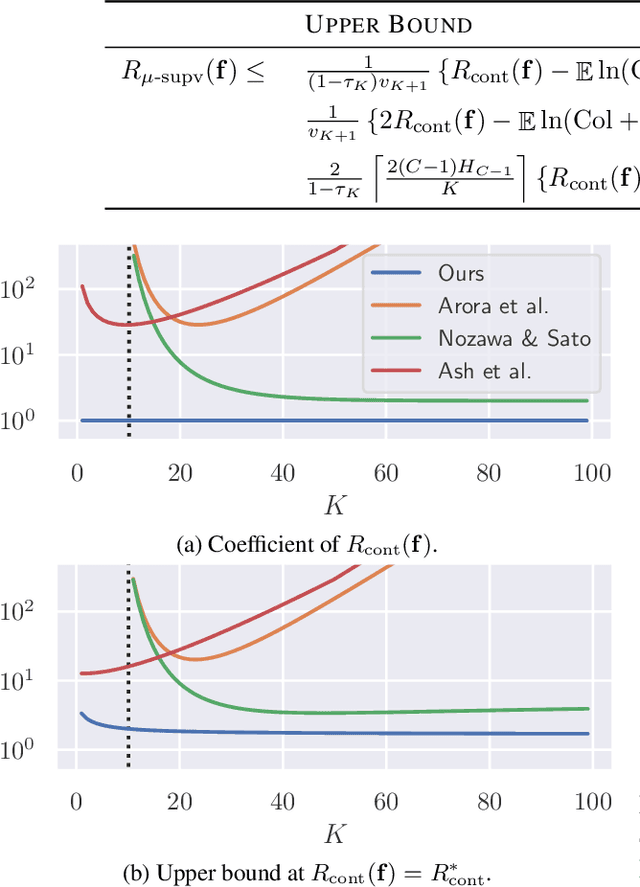
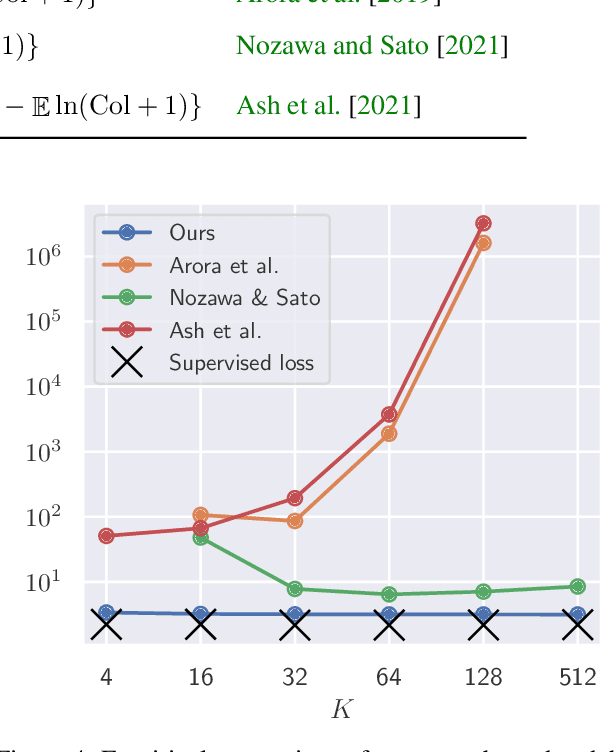
Contrastive unsupervised representation learning (CURL) encourages data representation to make semantically similar pairs closer than randomly drawn negative samples, which has been successful in various domains such as vision, language, and graphs. Although recent theoretical studies have attempted to explain its success by upper bounds of a downstream classification loss by the contrastive loss, they are still not sharp enough to explain an experimental fact: larger negative samples improve the classification performance. This study establishes a downstream classification loss bound with a tight intercept in the negative sample size. By regarding the contrastive loss as a downstream loss estimator, our theory not only improves the existing learning bounds substantially but also explains why downstream classification empirically improves with larger negative samples -- because the estimation variance of the downstream loss decays with larger negative samples. We verify that our theory is consistent with experiments on synthetic, vision, and language datasets.
Understanding Negative Samples in Instance Discriminative Self-supervised Representation Learning
Feb 13, 2021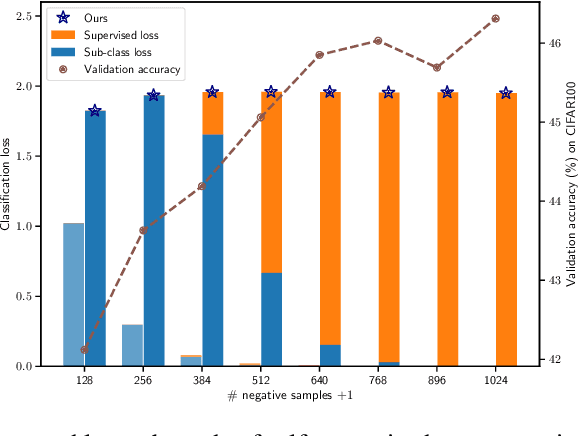
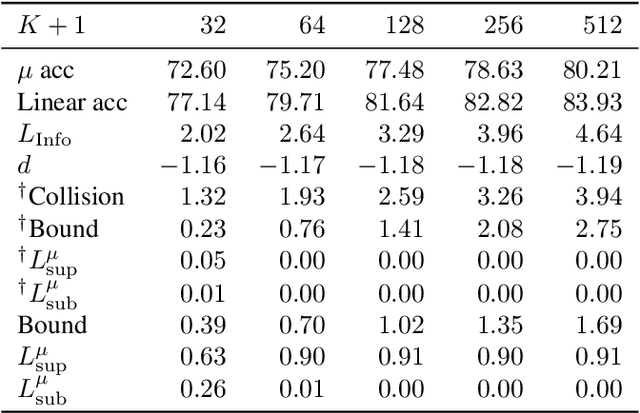
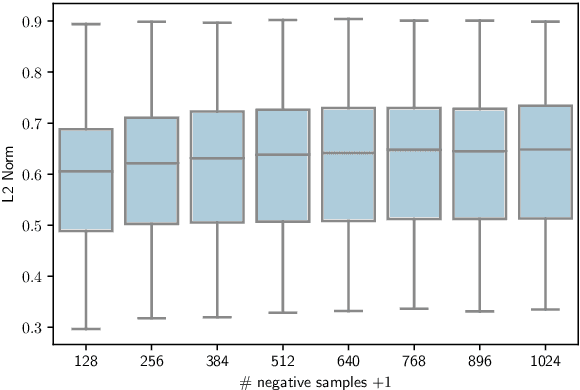
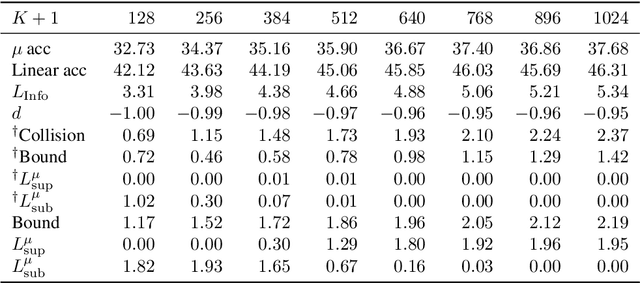
Instance discriminative self-supervised representation learning has been attracted attention thanks to its unsupervised nature and informative feature representation for downstream tasks. Self-supervised representation learning commonly uses more negative samples than the number of supervised classes in practice. However, there is an inconsistency in the existing analysis; theoretically, a large number of negative samples degrade supervised performance, while empirically, they improve the performance. We theoretically explain this empirical result regarding negative samples. We empirically confirm our analysis by conducting numerical experiments on CIFAR-10/100 datasets.
PAC-Bayesian Contrastive Unsupervised Representation Learning
Oct 10, 2019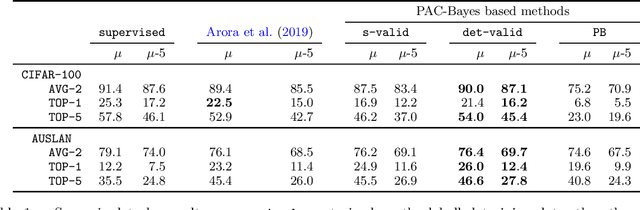
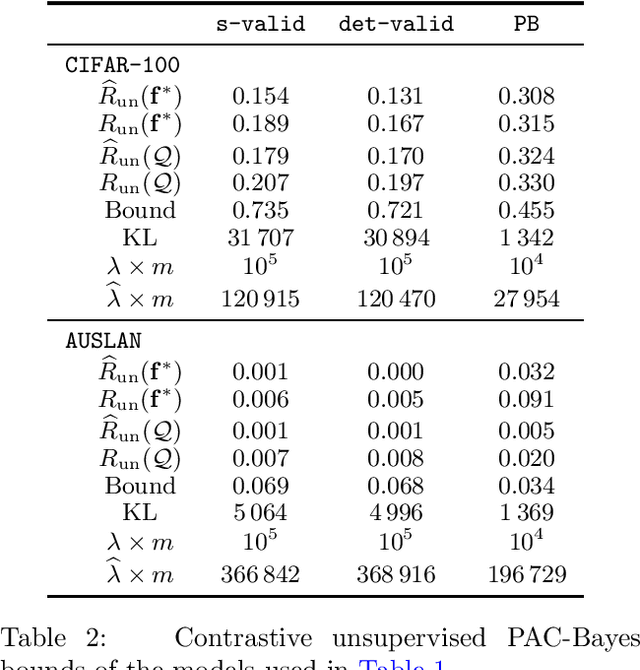
Contrastive unsupervised representation learning (CURL) is the state-of-the-art technique to learn representations (as a set of features) from unlabelled data. While CURL has collected several empirical successes recently, theoretical understanding of its performance was still missing. In a recent work, Arora et al. (2019) provide the first generalisation bounds for CURL, relying on a Rademacher complexity. We extend their framework to the flexible PAC-Bayes setting, allowing to deal with the non-iid setting. We present PAC-Bayesian generalisation bounds for CURL, which are then used to derive a new representation learning algorithm. Numerical experiments on real-life datasets illustrate that our algorithm achieves competitive accuracy, and yields generalisation bounds with non-vacuous values.
PAC-Bayes Analysis of Sentence Representation
Feb 13, 2019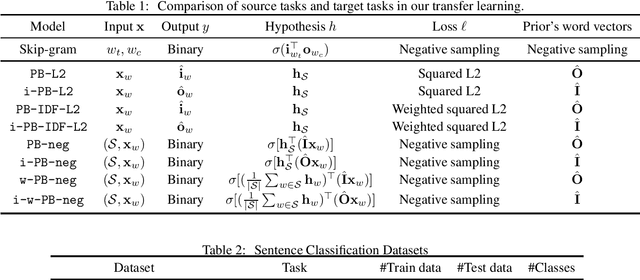
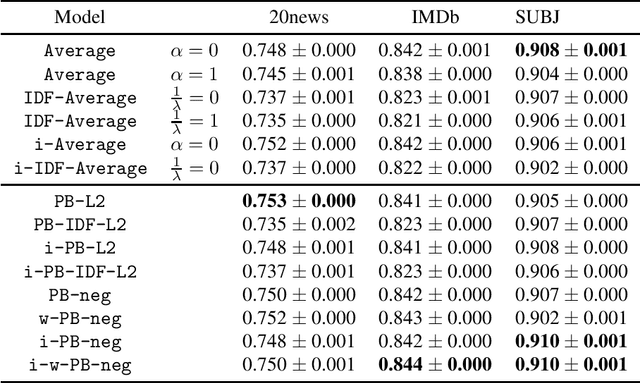
Learning sentence vectors from an unlabeled corpus has attracted attention because such vectors can represent sentences in a lower dimensional and continuous space. Simple heuristics using pre-trained word vectors are widely applied to machine learning tasks. However, they are not well understood from a theoretical perspective. We analyze learning sentence vectors from a transfer learning perspective by using a PAC-Bayes bound that enables us to understand existing heuristics. We show that simple heuristics such as averaging and inverse document frequency weighted averaging are derived by our formulation. Moreover, we propose novel sentence vector learning algorithms on the basis of our PAC-Bayes analysis.
Node Centralities and Classification Performance for Characterizing Node Embedding Algorithms
Feb 18, 2018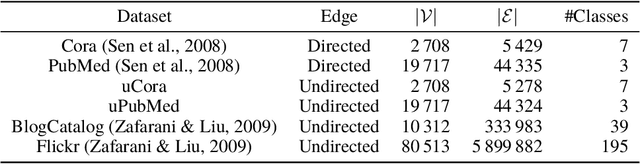
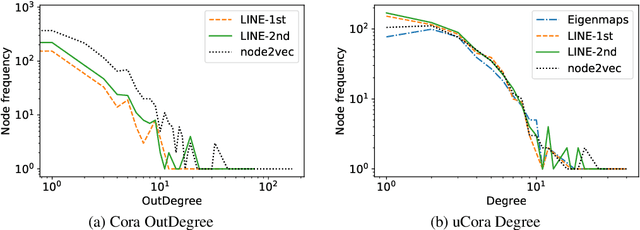

Embedding graph nodes into a vector space can allow the use of machine learning to e.g. predict node classes, but the study of node embedding algorithms is immature compared to the natural language processing field because of a diverse nature of graphs. We examine the performance of node embedding algorithms with respect to graph centrality measures that characterize diverse graphs, through systematic experiments with four node embedding algorithms, four or five graph centralities, and six datasets. Experimental results give insights into the properties of node embedding algorithms, which can be a basis for further research on this topic.