Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNode Centralities and Classification Performance for Characterizing Node Embedding Algorithms
Paper and Code
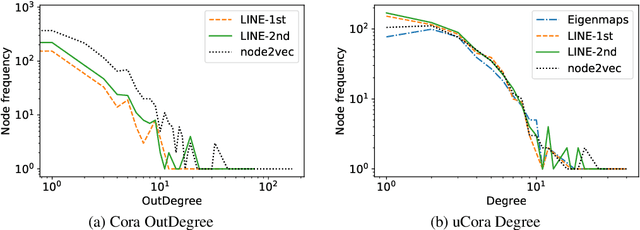

Embedding graph nodes into a vector space can allow the use of machine learning to e.g. predict node classes, but the study of node embedding algorithms is immature compared to the natural language processing field because of a diverse nature of graphs. We examine the performance of node embedding algorithms with respect to graph centrality measures that characterize diverse graphs, through systematic experiments with four node embedding algorithms, four or five graph centralities, and six datasets. Experimental results give insights into the properties of node embedding algorithms, which can be a basis for further research on this topic.
* Under review at ICLR 2018 workshop track
View paper on