 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Geometry of Absorbing Markov-Chain and Discriminative Random Walks
Feb 09, 2026Discriminative Random Walks (DRWs) are a simple yet powerful tool for semi-supervised node classification, but their theoretical foundations remain fragmentary. We revisit DRWs through the lens of information geometry, treating the family of class-specific hitting-time laws on an absorbing Markov chain as a statistical manifold. Starting from a log-linear edge-weight model, we derive closed-form expressions for the hitting-time probability mass function, its full moment hierarchy, and the observed Fisher information. The Fisher matrix of each seed node turns out to be rank-one, taking the quotient by its null space yields a low-dimensional, globally flat manifold that captures all identifiable directions of the model. Leveraging the geometry, we introduce a sensitivity score for unlabeled nodes that bounds, and in one-dimensional cases attains, the maximal first-order change in DRW betweenness under unit Fisher perturbations. The score can lead to principled strategies for active label acquisition, edge re-weighting, and explanation.
Generalized Power Priors for Improved Bayesian Inference with Historical Data
May 22, 2025



The power prior is a class of informative priors designed to incorporate historical data alongside current data in a Bayesian framework. It includes a power parameter that controls the influence of historical data, providing flexibility and adaptability. A key property of the power prior is that the resulting posterior minimizes a linear combination of KL divergences between two pseudo-posterior distributions: one ignoring historical data and the other fully incorporating it. We extend this framework by identifying the posterior distribution as the minimizer of a linear combination of Amari's $\alpha$-divergence, a generalization of KL divergence. We show that this generalization can lead to improved performance by allowing for the data to adapt to appropriate choices of the $\alpha$ parameter. Theoretical properties of this generalized power posterior are established, including behavior as a generalized geodesic on the Riemannian manifold of probability distributions, offering novel insights into its geometric interpretation.
Higher-Order Asymptotics of Test-Time Adaptation for Batch Normalization Statistics
May 22, 2025This study develops a higher-order asymptotic framework for test-time adaptation (TTA) of Batch Normalization (BN) statistics under distribution shift by integrating classical Edgeworth expansion and saddlepoint approximation techniques with a novel one-step M-estimation perspective. By analyzing the statistical discrepancy between training and test distributions, we derive an Edgeworth expansion for the normalized difference in BN means and obtain an optimal weighting parameter that minimizes the mean-squared error of the adapted statistic. Reinterpreting BN TTA as a one-step M-estimator allows us to derive higher-order local asymptotic normality results, which incorporate skewness and other higher moments into the estimator's behavior. Moreover, we quantify the trade-offs among bias, variance, and skewness in the adaptation process and establish a corresponding generalization bound on the model risk. The refined saddlepoint approximations further deliver uniformly accurate density and tail probability estimates for the BN TTA statistic. These theoretical insights provide a comprehensive understanding of how higher-order corrections and robust one-step updating can enhance the reliability and performance of BN layers in adapting to changing data distributions.
Graph-Smoothed Bayesian Black-Box Shift Estimator and Its Information Geometry
May 22, 2025



Label shift adaptation aims to recover target class priors when the labelled source distribution $P$ and the unlabelled target distribution $Q$ share $P(X \mid Y) = Q(X \mid Y)$ but $P(Y) \neq Q(Y)$. Classical black-box shift estimators invert an empirical confusion matrix of a frozen classifier, producing a brittle point estimate that ignores sampling noise and similarity among classes. We present Graph-Smoothed Bayesian BBSE (GS-B$^3$SE), a fully probabilistic alternative that places Laplacian-Gaussian priors on both target log-priors and confusion-matrix columns, tying them together on a label-similarity graph. The resulting posterior is tractable with HMC or a fast block Newton-CG scheme. We prove identifiability, $N^{-1/2}$ contraction, variance bounds that shrink with the graph's algebraic connectivity, and robustness to Laplacian misspecification. We also reinterpret GS-B$^3$SE through information geometry, showing that it generalizes existing shift estimators.
Edgeworth Expansion for Semi-hard Triplet Loss
Mar 17, 2025We develop a higher-order asymptotic analysis for the semi-hard triplet loss using the Edgeworth expansion. It is known that this loss function enforces that embeddings of similar samples are close while those of dissimilar samples are separated by a specified margin. By refining the classical central limit theorem, our approach quantifies the impact of the margin parameter and the skewness of the underlying data distribution on the loss behavior. In particular, we derive explicit Edgeworth expansions that reveal first-order corrections in terms of the third cumulant, thereby characterizing non-Gaussian effects present in the distribution of distance differences between anchor-positive and anchor-negative pairs. Our findings provide detailed insight into the sensitivity of the semi-hard triplet loss to its parameters and offer guidance for choosing the margin to ensure training stability.
Heteroscedastic Double Bayesian Elastic Net
Feb 04, 2025In many practical applications, regression models are employed to uncover relationships between predictors and a response variable, yet the common assumption of constant error variance is frequently violated. This issue is further compounded in high-dimensional settings where the number of predictors exceeds the sample size, necessitating regularization for effective estimation and variable selection. To address this problem, we propose the Heteroscedastic Double Bayesian Elastic Net (HDBEN), a novel framework that jointly models the mean and log-variance using hierarchical Bayesian priors incorporating both $\ell_1$ and $\ell_2$ penalties. Our approach simultaneously induces sparsity and grouping in the regression coefficients and variance parameters, capturing complex variance structures in the data. Theoretical results demonstrate that proposed HDBEN achieves posterior concentration, variable selection consistency, and asymptotic normality under mild conditions which justifying its behavior. Simulation studies further illustrate that HDBEN outperforms existing methods, particularly in scenarios characterized by heteroscedasticity and high dimensionality.
Theoretical and Practical Analysis of Fréchet Regression via Comparison Geometry
Feb 04, 2025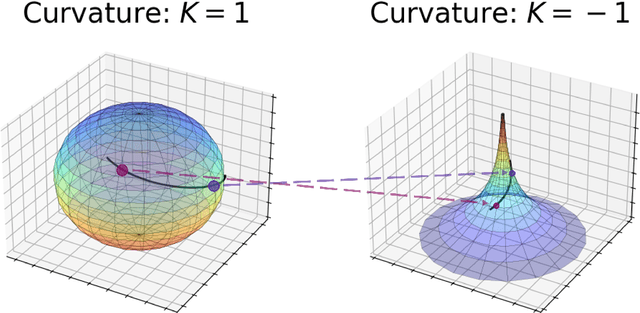
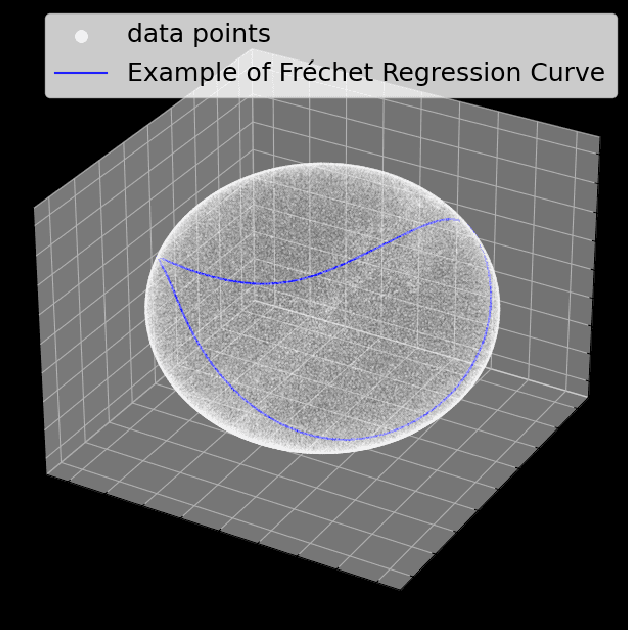
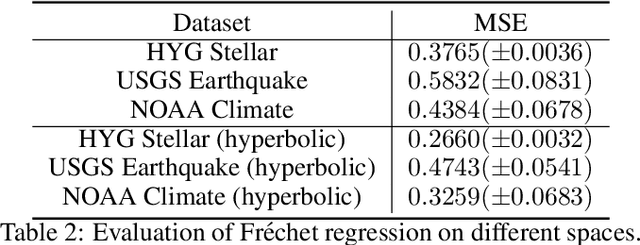
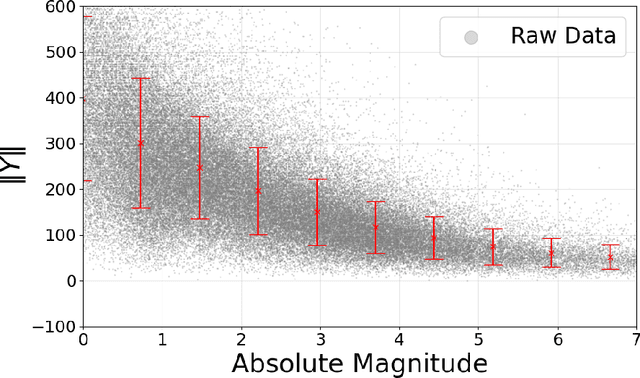
Fr\'echet regression extends classical regression methods to non-Euclidean metric spaces, enabling the analysis of data relationships on complex structures such as manifolds and graphs. This work establishes a rigorous theoretical analysis for Fr\'echet regression through the lens of comparison geometry which leads to important considerations for its use in practice. The analysis provides key results on the existence, uniqueness, and stability of the Fr\'echet mean, along with statistical guarantees for nonparametric regression, including exponential concentration bounds and convergence rates. Additionally, insights into angle stability reveal the interplay between curvature of the manifold and the behavior of the regression estimator in these non-Euclidean contexts. Empirical experiments validate the theoretical findings, demonstrating the effectiveness of proposed hyperbolic mappings, particularly for data with heteroscedasticity, and highlighting the practical usefulness of these results.
A Fashion Item Recommendation Model in Hyperbolic Space
Sep 04, 2024In this work, we propose a fashion item recommendation model that incorporates hyperbolic geometry into user and item representations. Using hyperbolic space, our model aims to capture implicit hierarchies among items based on their visual data and users' purchase history. During training, we apply a multi-task learning framework that considers both hyperbolic and Euclidean distances in the loss function. Our experiments on three data sets show that our model performs better than previous models trained in Euclidean space only, confirming the effectiveness of our model. Our ablation studies show that multi-task learning plays a key role, and removing the Euclidean loss substantially deteriorates the model performance.
Density Ratio Estimation via Sampling along Generalized Geodesics on Statistical Manifolds
Jun 27, 2024



The density ratio of two probability distributions is one of the fundamental tools in mathematical and computational statistics and machine learning, and it has a variety of known applications. Therefore, density ratio estimation from finite samples is a very important task, but it is known to be unstable when the distributions are distant from each other. One approach to address this problem is density ratio estimation using incremental mixtures of the two distributions. We geometrically reinterpret existing methods for density ratio estimation based on incremental mixtures. We show that these methods can be regarded as iterating on the Riemannian manifold along a particular curve between the two probability distributions. Making use of the geometry of the manifold, we propose to consider incremental density ratio estimation along generalized geodesics on this manifold. To achieve such a method requires Monte Carlo sampling along geodesics via transformations of the two distributions. We show how to implement an iterative algorithm to sample along these geodesics and show how changing the distances along the geodesic affect the variance and accuracy of the estimation of the density ratio. Our experiments demonstrate that the proposed approach outperforms the existing approaches using incremental mixtures that do not take the geometry of the
Explaining Black-box Model Predictions via Two-level Nested Feature Attributions with Consistency Property
May 23, 2024



Techniques that explain the predictions of black-box machine learning models are crucial to make the models transparent, thereby increasing trust in AI systems. The input features to the models often have a nested structure that consists of high- and low-level features, and each high-level feature is decomposed into multiple low-level features. For such inputs, both high-level feature attributions (HiFAs) and low-level feature attributions (LoFAs) are important for better understanding the model's decision. In this paper, we propose a model-agnostic local explanation method that effectively exploits the nested structure of the input to estimate the two-level feature attributions simultaneously. A key idea of the proposed method is to introduce the consistency property that should exist between the HiFAs and LoFAs, thereby bridging the separate optimization problems for estimating them. Thanks to this consistency property, the proposed method can produce HiFAs and LoFAs that are both faithful to the black-box models and consistent with each other, using a smaller number of queries to the models. In experiments on image classification in multiple instance learning and text classification using language models, we demonstrate that the HiFAs and LoFAs estimated by the proposed method are accurate, faithful to the behaviors of the black-box models, and provide consistent explanations.