 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Likes and Dislikes in Personalized Generative Explainable Recommendation
Oct 17, 2024



Recent research on explainable recommendation generally frames the task as a standard text generation problem, and evaluates models simply based on the textual similarity between the predicted and ground-truth explanations. However, this approach fails to consider one crucial aspect of the systems: whether their outputs accurately reflect the users' (post-purchase) sentiments, i.e., whether and why they would like and/or dislike the recommended items. To shed light on this issue, we introduce new datasets and evaluation methods that focus on the users' sentiments. Specifically, we construct the datasets by explicitly extracting users' positive and negative opinions from their post-purchase reviews using an LLM, and propose to evaluate systems based on whether the generated explanations 1) align well with the users' sentiments, and 2) accurately identify both positive and negative opinions of users on the target items. We benchmark several recent models on our datasets and demonstrate that achieving strong performance on existing metrics does not ensure that the generated explanations align well with the users' sentiments. Lastly, we find that existing models can provide more sentiment-aware explanations when the users' (predicted) ratings for the target items are directly fed into the models as input. We will release our code and datasets upon acceptance.
Explaining Black-box Model Predictions via Two-level Nested Feature Attributions with Consistency Property
May 23, 2024



Techniques that explain the predictions of black-box machine learning models are crucial to make the models transparent, thereby increasing trust in AI systems. The input features to the models often have a nested structure that consists of high- and low-level features, and each high-level feature is decomposed into multiple low-level features. For such inputs, both high-level feature attributions (HiFAs) and low-level feature attributions (LoFAs) are important for better understanding the model's decision. In this paper, we propose a model-agnostic local explanation method that effectively exploits the nested structure of the input to estimate the two-level feature attributions simultaneously. A key idea of the proposed method is to introduce the consistency property that should exist between the HiFAs and LoFAs, thereby bridging the separate optimization problems for estimating them. Thanks to this consistency property, the proposed method can produce HiFAs and LoFAs that are both faithful to the black-box models and consistent with each other, using a smaller number of queries to the models. In experiments on image classification in multiple instance learning and text classification using language models, we demonstrate that the HiFAs and LoFAs estimated by the proposed method are accurate, faithful to the behaviors of the black-box models, and provide consistent explanations.
Explanation-Based Training with Differentiable Insertion/Deletion Metric-Aware Regularizers
Oct 20, 2023



The quality of explanations for the predictions of complex machine learning predictors is often measured using insertion and deletion metrics, which assess the faithfulness of the explanations, i.e., how correctly the explanations reflect the predictor's behavior. To improve the faithfulness, we propose insertion/deletion metric-aware explanation-based optimization (ID-ExpO), which optimizes differentiable predictors to improve both insertion and deletion scores of the explanations while keeping their predictive accuracy. Since the original insertion and deletion metrics are indifferentiable with respect to the explanations and directly unavailable for gradient-based optimization, we extend the metrics to be differentiable and use them to formalize insertion and deletion metric-based regularizers. The experimental results on image and tabular datasets show that the deep neural networks-based predictors fine-tuned using ID-ExpO enable popular post-hoc explainers to produce more faithful and easy-to-interpret explanations while keeping high predictive accuracy.
Action Class Relation Detection and Classification Across Multiple Video Datasets
Aug 15, 2023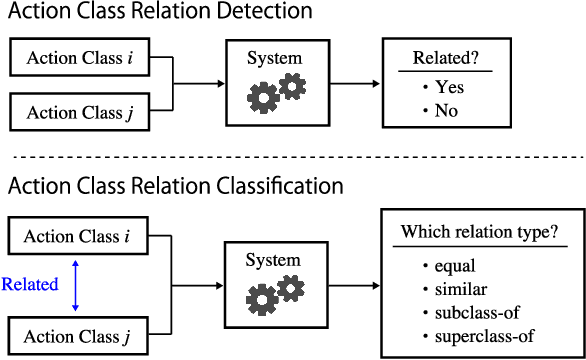

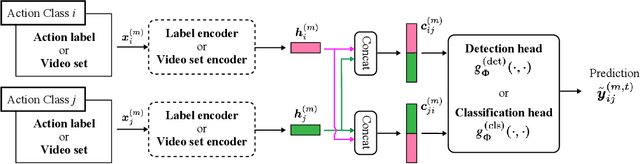

The Meta Video Dataset (MetaVD) provides annotated relations between action classes in major datasets for human action recognition in videos. Although these annotated relations enable dataset augmentation, it is only applicable to those covered by MetaVD. For an external dataset to enjoy the same benefit, the relations between its action classes and those in MetaVD need to be determined. To address this issue, we consider two new machine learning tasks: action class relation detection and classification. We propose a unified model to predict relations between action classes, using language and visual information associated with classes. Experimental results show that (i) pre-trained recent neural network models for texts and videos contribute to high predictive performance, (ii) the relation prediction based on action label texts is more accurate than based on videos, and (iii) a blending approach that combines predictions by both modalities can further improve the predictive performance in some cases.
Learning Decorrelated Representations Efficiently Using Fast Fourier Transform
Jan 04, 2023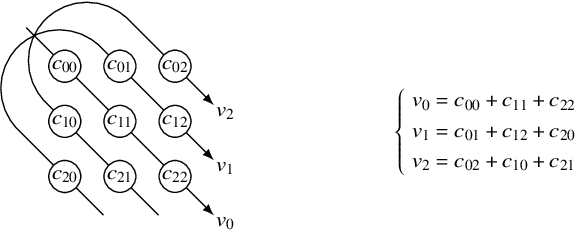
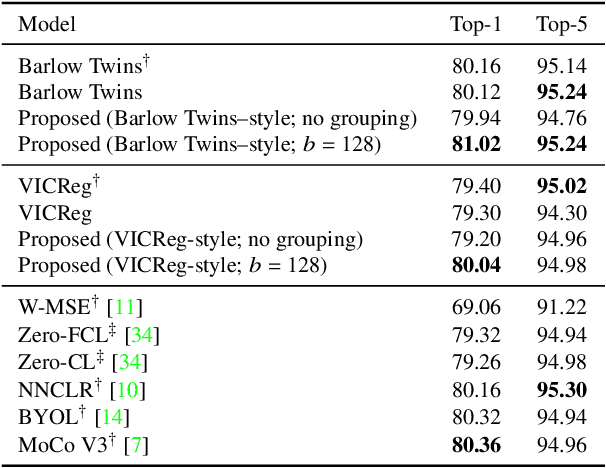
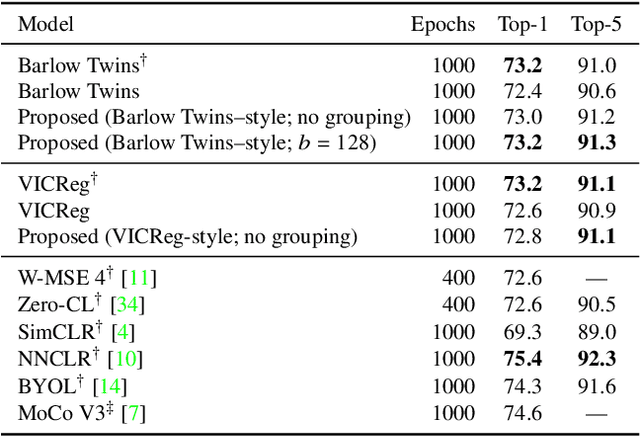
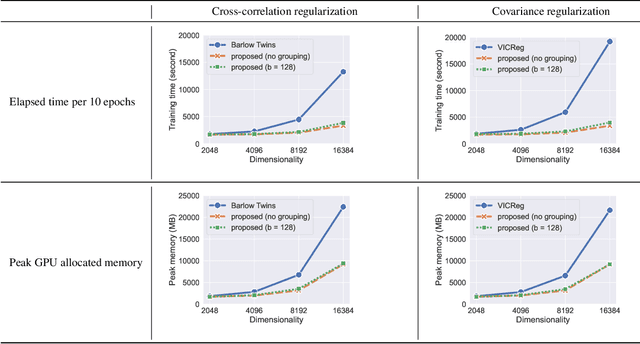
Barlow Twins and VICReg are self-supervised representation learning models that use regularizers to decorrelate features. Although they work as well as conventional representation learning models, their training can be computationally demanding if the dimension of projected representations is high; as these regularizers are defined in terms of individual elements of a cross-correlation or covariance matrix, computing the loss for $d$-dimensional projected representations of $n$ samples takes $O(n d^2)$ time. In this paper, we propose a relaxed version of decorrelating regularizers that can be computed in $O(n d\log d)$ time by the fast Fourier transform. We also propose an inexpensive trick to mitigate the undesirable local minima that develop with the relaxation. Models learning representations using the proposed regularizers show comparable accuracy to existing models in downstream tasks, whereas the training requires less memory and is faster when $d$ is large.
Training Deep Models to be Explained with Fewer Examples
Dec 07, 2021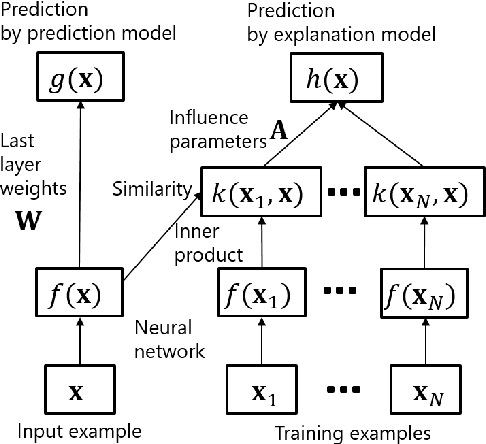
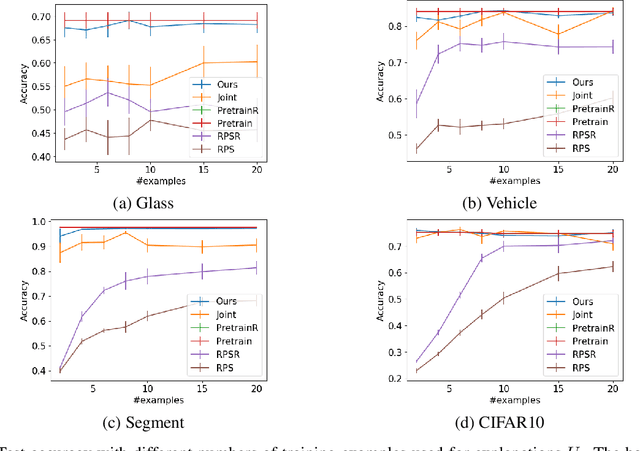
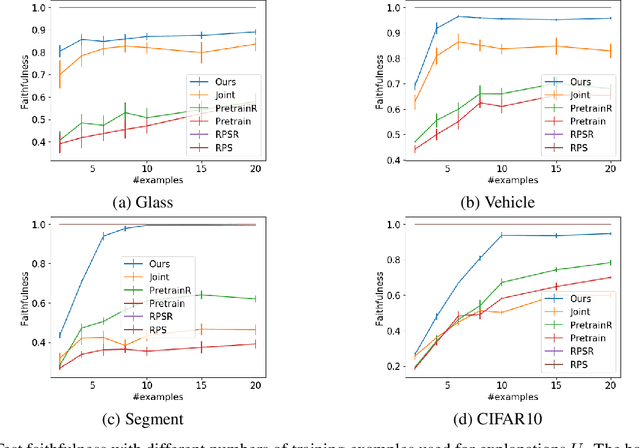
Although deep models achieve high predictive performance, it is difficult for humans to understand the predictions they made. Explainability is important for real-world applications to justify their reliability. Many example-based explanation methods have been proposed, such as representer point selection, where an explanation model defined by a set of training examples is used for explaining a prediction model. For improving the interpretability, reducing the number of examples in the explanation model is important. However, the explanations with fewer examples can be unfaithful since it is difficult to approximate prediction models well by such example-based explanation models. The unfaithful explanations mean that the predictions by the explainable model are different from those by the prediction model. We propose a method for training deep models such that their predictions are faithfully explained by explanation models with a small number of examples. We train the prediction and explanation models simultaneously with a sparse regularizer for reducing the number of examples. The proposed method can be incorporated into any neural network-based prediction models. Experiments using several datasets demonstrate that the proposed method improves faithfulness while keeping the predictive performance.
Gaussian Process Regression with Local Explanation
Jul 03, 2020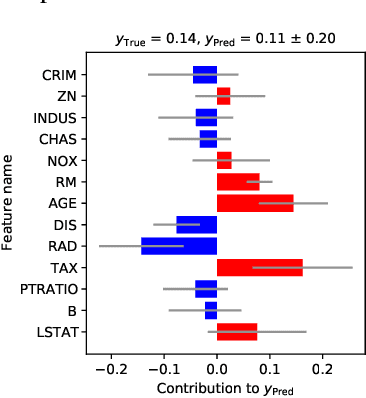
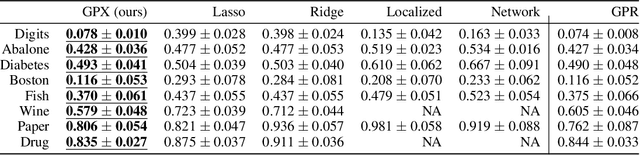
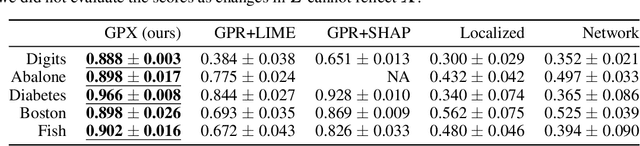
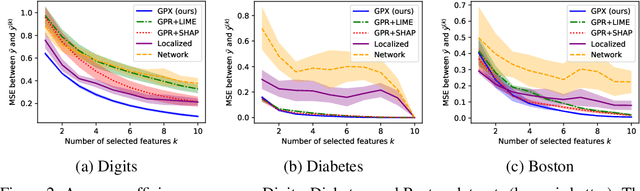
Gaussian process regression (GPR) is a fundamental model used in machine learning. Owing to its accurate prediction with uncertainty and versatility in handling various data structures via kernels, GPR has been successfully used in various applications. However, in GPR, how the features of an input contribute to its prediction cannot be interpreted. Herein, we propose GPR with local explanation, which reveals the feature contributions to the prediction of each sample, while maintaining the predictive performance of GPR. In the proposed model, both the prediction and explanation for each sample are performed using an easy-to-interpret locally linear model. The weight vector of the locally linear model is assumed to be generated from multivariate Gaussian process priors. The hyperparameters of the proposed models are estimated by maximizing the marginal likelihood. For a new test sample, the proposed model can predict the values of its target variable and weight vector, as well as their uncertainties, in a closed form. Experimental results on various benchmark datasets verify that the proposed model can achieve predictive performance comparable to those of GPR and superior to that of existing interpretable models, and can achieve higher interpretability than them, both quantitatively and qualitatively.
Neural Generators of Sparse Local Linear Models for Achieving both Accuracy and Interpretability
Mar 13, 2020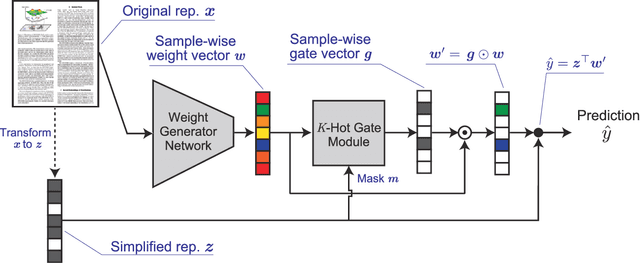
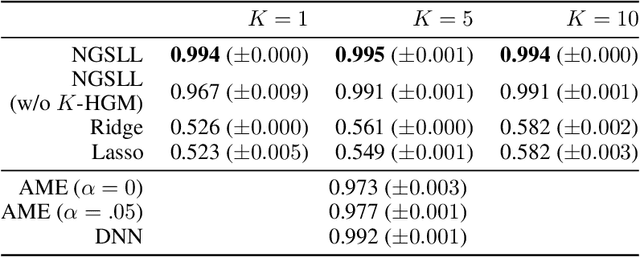
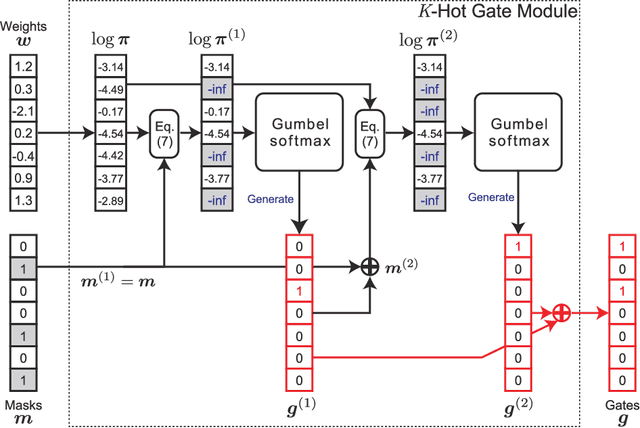

For reliability, it is important that the predictions made by machine learning methods are interpretable by human. In general, deep neural networks (DNNs) can provide accurate predictions, although it is difficult to interpret why such predictions are obtained by DNNs. On the other hand, interpretation of linear models is easy, although their predictive performance would be low since real-world data is often intrinsically non-linear. To combine both the benefits of the high predictive performance of DNNs and high interpretability of linear models into a single model, we propose neural generators of sparse local linear models (NGSLLs). The sparse local linear models have high flexibility as they can approximate non-linear functions. The NGSLL generates sparse linear weights for each sample using DNNs that take original representations of each sample (e.g., word sequence) and their simplified representations (e.g., bag-of-words) as input. By extracting features from the original representations, the weights can contain rich information to achieve high predictive performance. Additionally, the prediction is interpretable because it is obtained by the inner product between the simplified representations and the sparse weights, where only a small number of weights are selected by our gate module in the NGSLL. In experiments with real-world datasets, we demonstrate the effectiveness of the NGSLL quantitatively and qualitatively by evaluating prediction performance and visualizing generated weights on image and text classification tasks.
Video Caption Dataset for Describing Human Actions in Japanese
Mar 10, 2020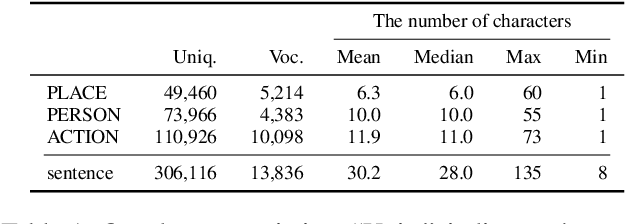

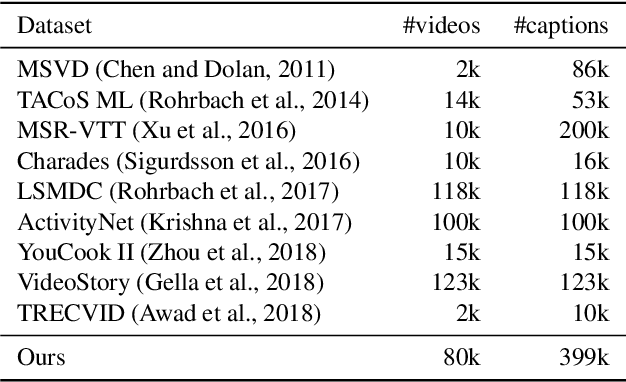
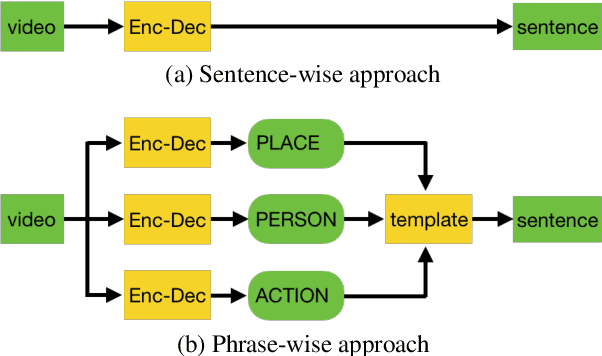
In recent years, automatic video caption generation has attracted considerable attention. This paper focuses on the generation of Japanese captions for describing human actions. While most currently available video caption datasets have been constructed for English, there is no equivalent Japanese dataset. To address this, we constructed a large-scale Japanese video caption dataset consisting of 79,822 videos and 399,233 captions. Each caption in our dataset describes a video in the form of "who does what and where." To describe human actions, it is important to identify the details of a person, place, and action. Indeed, when we describe human actions, we usually mention the scene, person, and action. In our experiments, we evaluated two caption generation methods to obtain benchmark results. Further, we investigated whether those generation methods could specify "who does what and where."
STAIR Actions: A Video Dataset of Everyday Home Actions
Apr 16, 2018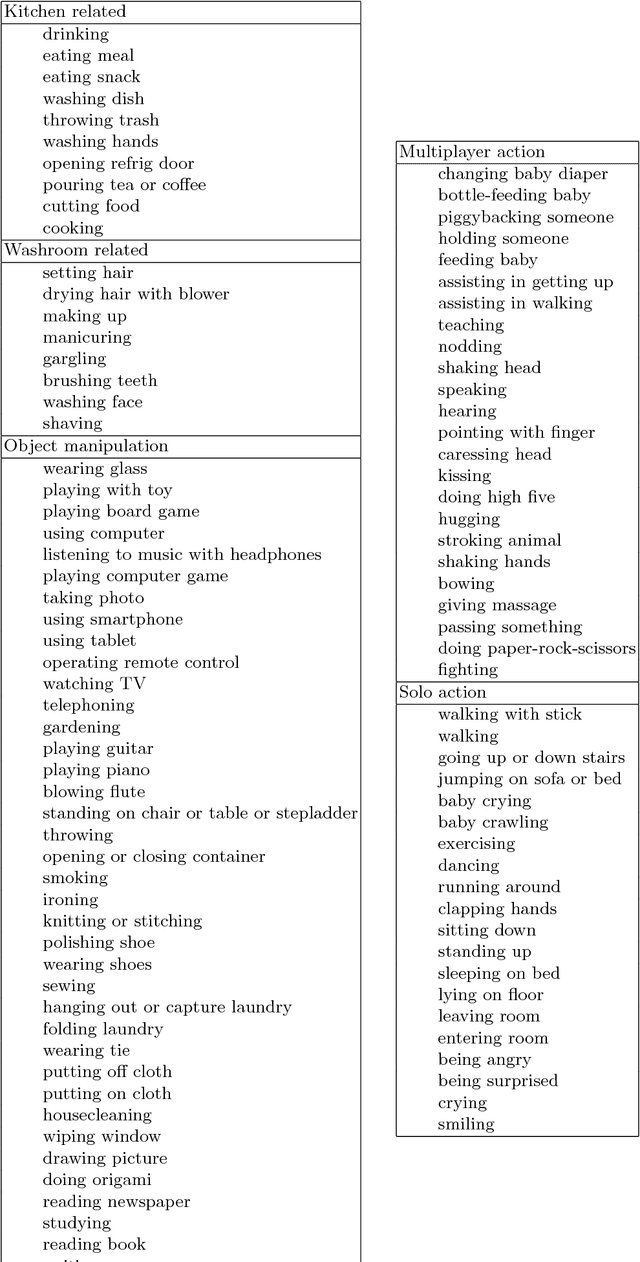
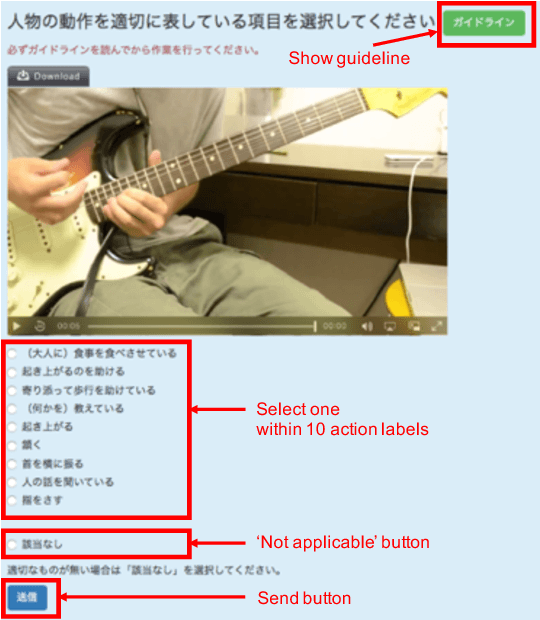

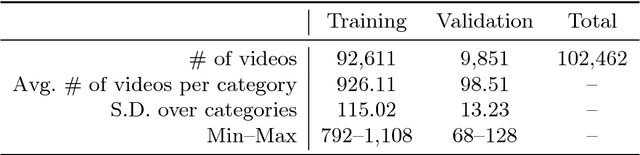
A new large-scale video dataset for human action recognition, called STAIR Actions is introduced. STAIR Actions contains 100 categories of action labels representing fine-grained everyday home actions so that it can be applied to research in various home tasks such as nursing, caring, and security. In STAIR Actions, each video has a single action label. Moreover, for each action category, there are around 1,000 videos that were obtained from YouTube or produced by crowdsource workers. The duration of each video is mostly five to six seconds. The total number of videos is 102,462. We explain how we constructed STAIR Actions and show the characteristics of STAIR Actions compared to existing datasets for human action recognition. Experiments with three major models for action recognition show that STAIR Actions can train large models and achieve good performance. STAIR Actions can be downloaded from http://actions.stair.center