 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Class Relation Detection and Classification Across Multiple Video Datasets
Aug 15, 2023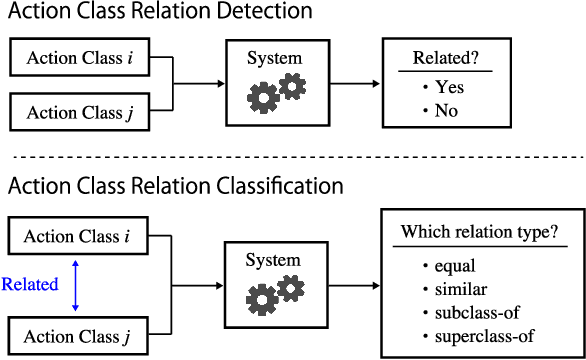

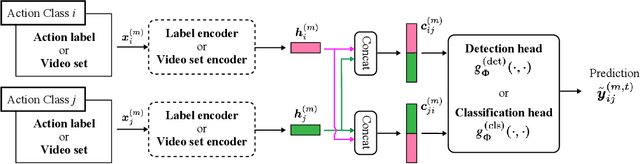

The Meta Video Dataset (MetaVD) provides annotated relations between action classes in major datasets for human action recognition in videos. Although these annotated relations enable dataset augmentation, it is only applicable to those covered by MetaVD. For an external dataset to enjoy the same benefit, the relations between its action classes and those in MetaVD need to be determined. To address this issue, we consider two new machine learning tasks: action class relation detection and classification. We propose a unified model to predict relations between action classes, using language and visual information associated with classes. Experimental results show that (i) pre-trained recent neural network models for texts and videos contribute to high predictive performance, (ii) the relation prediction based on action label texts is more accurate than based on videos, and (iii) a blending approach that combines predictions by both modalities can further improve the predictive performance in some cases.
Learning Decorrelated Representations Efficiently Using Fast Fourier Transform
Jan 04, 2023
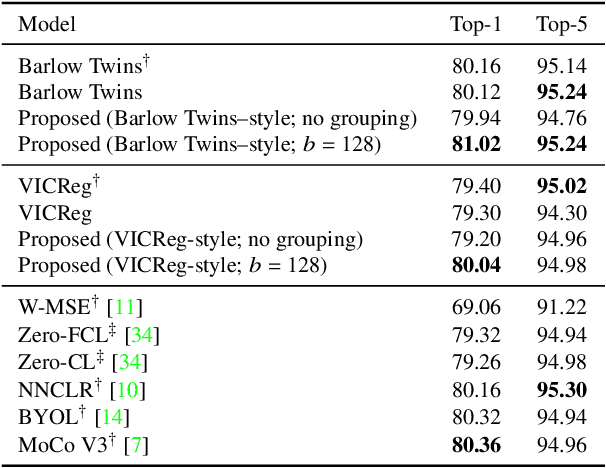
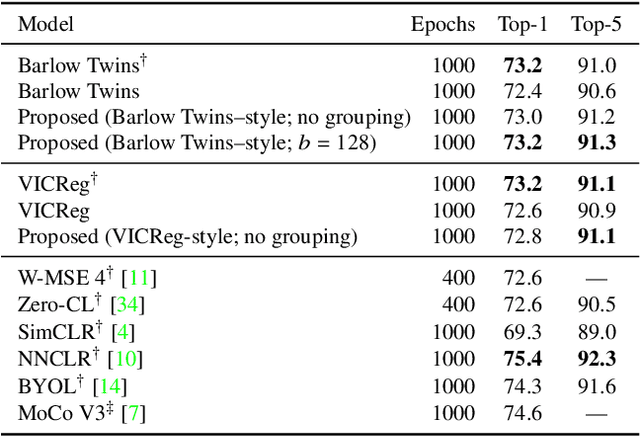
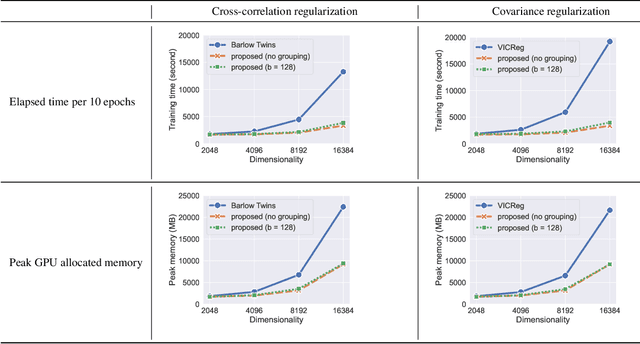
Barlow Twins and VICReg are self-supervised representation learning models that use regularizers to decorrelate features. Although they work as well as conventional representation learning models, their training can be computationally demanding if the dimension of projected representations is high; as these regularizers are defined in terms of individual elements of a cross-correlation or covariance matrix, computing the loss for $d$-dimensional projected representations of $n$ samples takes $O(n d^2)$ time. In this paper, we propose a relaxed version of decorrelating regularizers that can be computed in $O(n d\log d)$ time by the fast Fourier transform. We also propose an inexpensive trick to mitigate the undesirable local minima that develop with the relaxation. Models learning representations using the proposed regularizers show comparable accuracy to existing models in downstream tasks, whereas the training requires less memory and is faster when $d$ is large.
Video Caption Dataset for Describing Human Actions in Japanese
Mar 10, 2020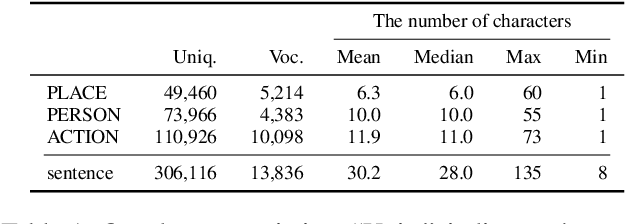

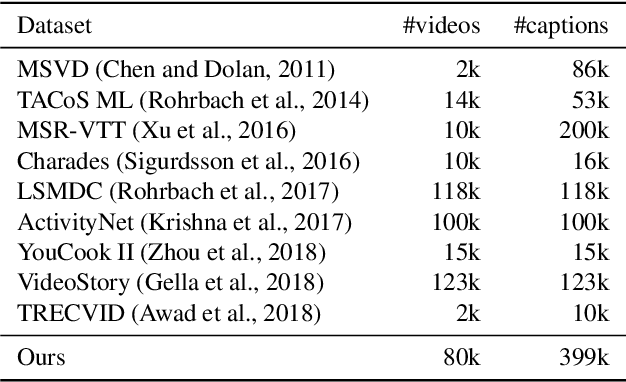
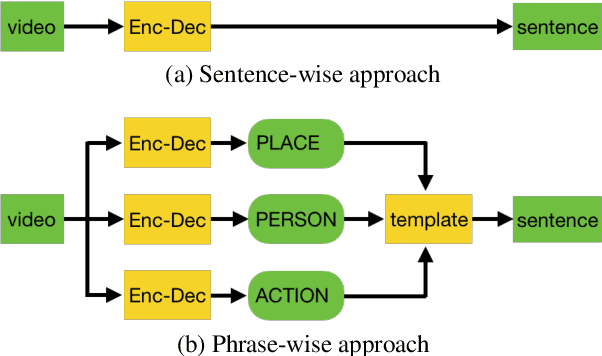
In recent years, automatic video caption generation has attracted considerable attention. This paper focuses on the generation of Japanese captions for describing human actions. While most currently available video caption datasets have been constructed for English, there is no equivalent Japanese dataset. To address this, we constructed a large-scale Japanese video caption dataset consisting of 79,822 videos and 399,233 captions. Each caption in our dataset describes a video in the form of "who does what and where." To describe human actions, it is important to identify the details of a person, place, and action. Indeed, when we describe human actions, we usually mention the scene, person, and action. In our experiments, we evaluated two caption generation methods to obtain benchmark results. Further, we investigated whether those generation methods could specify "who does what and where."
STAIR Actions: A Video Dataset of Everyday Home Actions
Apr 16, 2018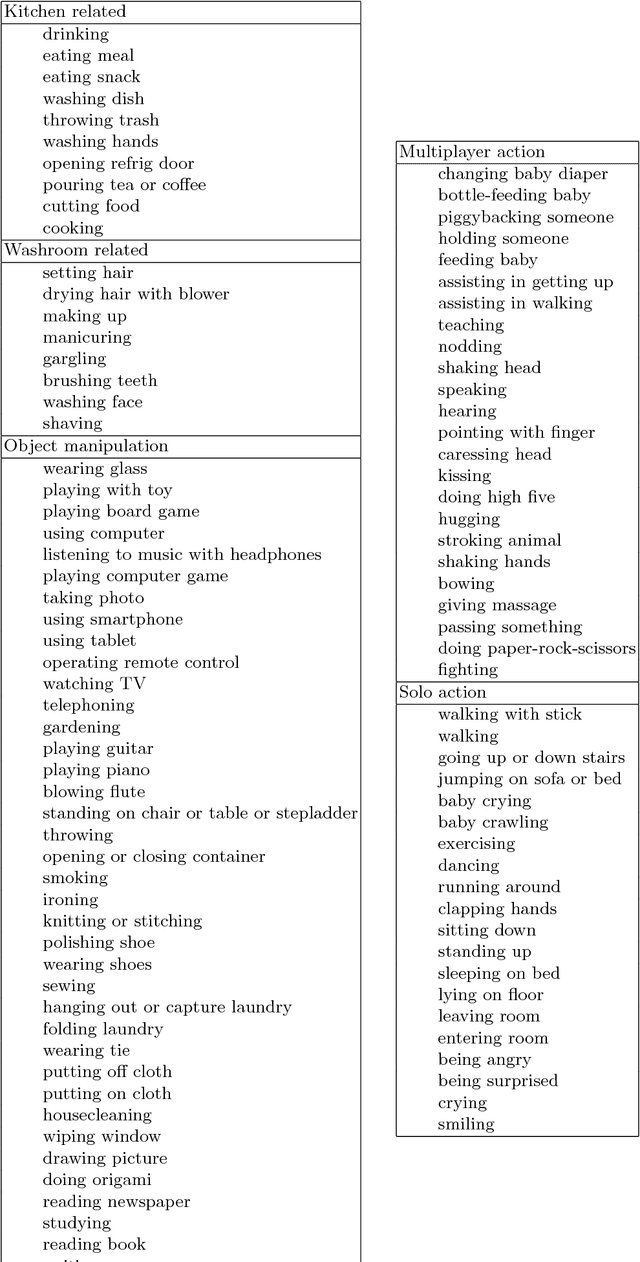
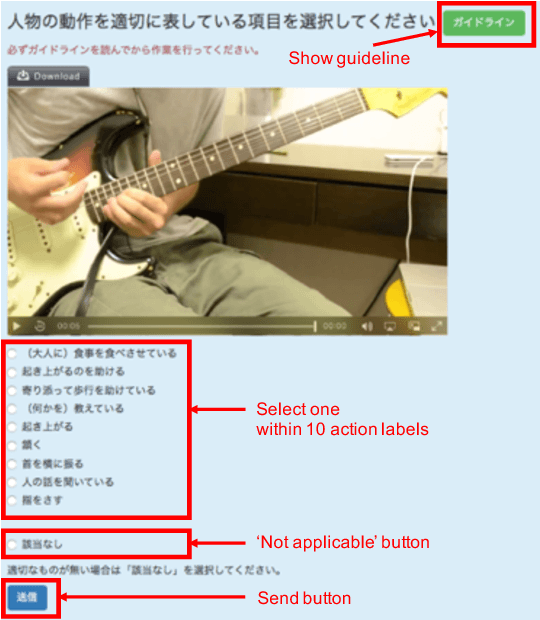

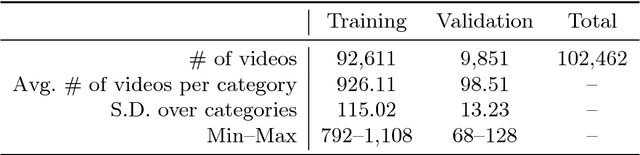
A new large-scale video dataset for human action recognition, called STAIR Actions is introduced. STAIR Actions contains 100 categories of action labels representing fine-grained everyday home actions so that it can be applied to research in various home tasks such as nursing, caring, and security. In STAIR Actions, each video has a single action label. Moreover, for each action category, there are around 1,000 videos that were obtained from YouTube or produced by crowdsource workers. The duration of each video is mostly five to six seconds. The total number of videos is 102,462. We explain how we constructed STAIR Actions and show the characteristics of STAIR Actions compared to existing datasets for human action recognition. Experiments with three major models for action recognition show that STAIR Actions can train large models and achieve good performance. STAIR Actions can be downloaded from http://actions.stair.center
STAIR Captions: Constructing a Large-Scale Japanese Image Caption Dataset
May 02, 2017



In recent years, automatic generation of image descriptions (captions), that is, image captioning, has attracted a great deal of attention. In this paper, we particularly consider generating Japanese captions for images. Since most available caption datasets have been constructed for English language, there are few datasets for Japanese. To tackle this problem, we construct a large-scale Japanese image caption dataset based on images from MS-COCO, which is called STAIR Captions. STAIR Captions consists of 820,310 Japanese captions for 164,062 images. In the experiment, we show that a neural network trained using STAIR Captions can generate more natural and better Japanese captions, compared to those generated using English-Japanese machine translation after generating English captions.
Speech Dialogue with Facial Displays: Multimodal Human-Computer Conversation
Jun 01, 1994
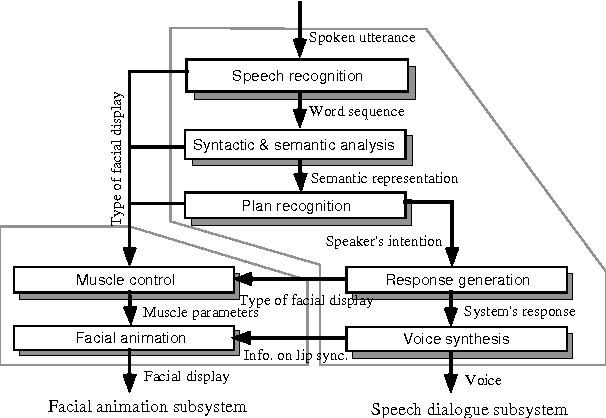


Human face-to-face conversation is an ideal model for human-computer dialogue. One of the major features of face-to-face communication is its multiplicity of communication channels that act on multiple modalities. To realize a natural multimodal dialogue, it is necessary to study how humans perceive information and determine the information to which humans are sensitive. A face is an independent communication channel that conveys emotional and conversational signals, encoded as facial expressions. We have developed an experimental system that integrates speech dialogue and facial animation, to investigate the effect of introducing communicative facial expressions as a new modality in human-computer conversation. Our experiments have shown that facial expressions are helpful, especially upon first contact with the system. We have also discovered that featuring facial expressions at an early stage improves subsequent interaction.