 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Class Relation Detection and Classification Across Multiple Video Datasets
Paper and Code
Aug 15, 2023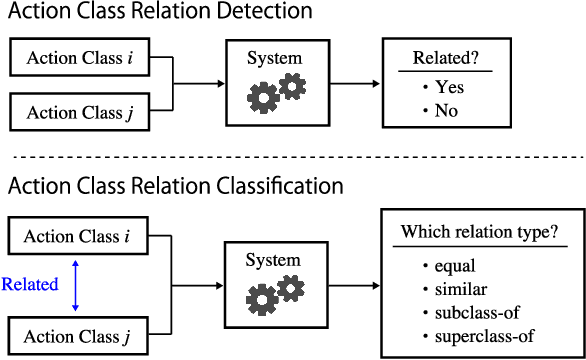

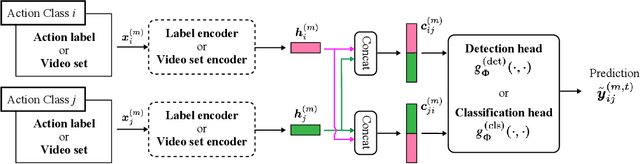

The Meta Video Dataset (MetaVD) provides annotated relations between action classes in major datasets for human action recognition in videos. Although these annotated relations enable dataset augmentation, it is only applicable to those covered by MetaVD. For an external dataset to enjoy the same benefit, the relations between its action classes and those in MetaVD need to be determined. To address this issue, we consider two new machine learning tasks: action class relation detection and classification. We propose a unified model to predict relations between action classes, using language and visual information associated with classes. Experimental results show that (i) pre-trained recent neural network models for texts and videos contribute to high predictive performance, (ii) the relation prediction based on action label texts is more accurate than based on videos, and (iii) a blending approach that combines predictions by both modalities can further improve the predictive performance in some cases.