 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Loss Functions for Fact Verification
Mar 13, 2024We explore loss functions for fact verification in the FEVER shared task. While the cross-entropy loss is a standard objective for training verdict predictors, it fails to capture the heterogeneity among the FEVER verdict classes. In this paper, we develop two task-specific objectives tailored to FEVER. Experimental results confirm that the proposed objective functions outperform the standard cross-entropy. Performance is further improved when these objectives are combined with simple class weighting, which effectively overcomes the imbalance in the training data. The souce code is available at https://github.com/yuta-mukobara/RLF-KGAT
Action Class Relation Detection and Classification Across Multiple Video Datasets
Aug 15, 2023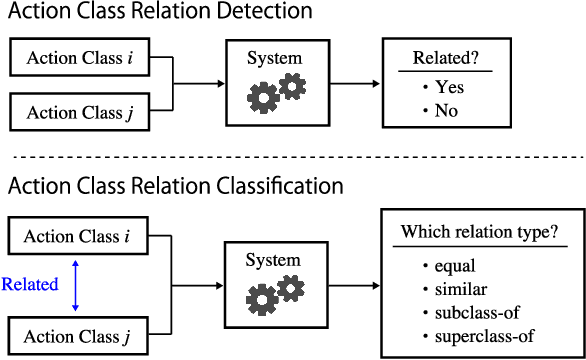

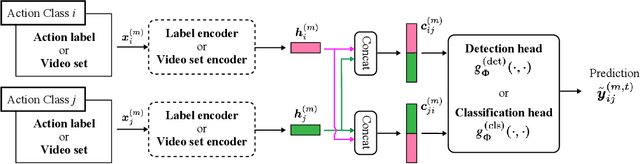

The Meta Video Dataset (MetaVD) provides annotated relations between action classes in major datasets for human action recognition in videos. Although these annotated relations enable dataset augmentation, it is only applicable to those covered by MetaVD. For an external dataset to enjoy the same benefit, the relations between its action classes and those in MetaVD need to be determined. To address this issue, we consider two new machine learning tasks: action class relation detection and classification. We propose a unified model to predict relations between action classes, using language and visual information associated with classes. Experimental results show that (i) pre-trained recent neural network models for texts and videos contribute to high predictive performance, (ii) the relation prediction based on action label texts is more accurate than based on videos, and (iii) a blending approach that combines predictions by both modalities can further improve the predictive performance in some cases.
Learning Decorrelated Representations Efficiently Using Fast Fourier Transform
Jan 04, 2023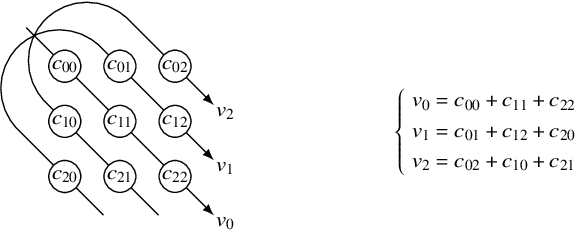
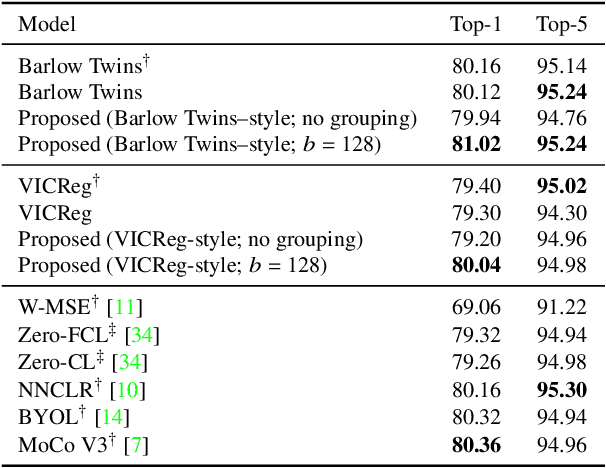
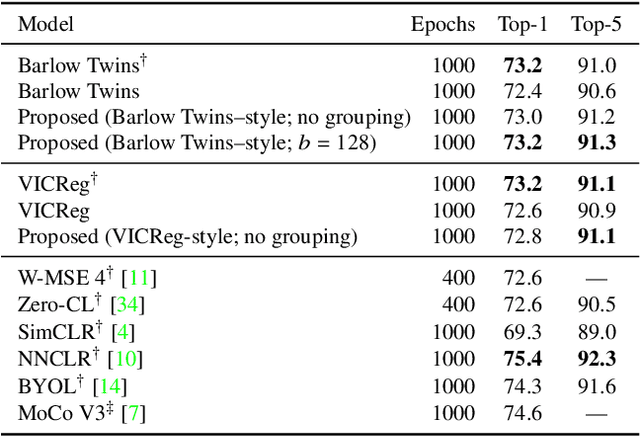
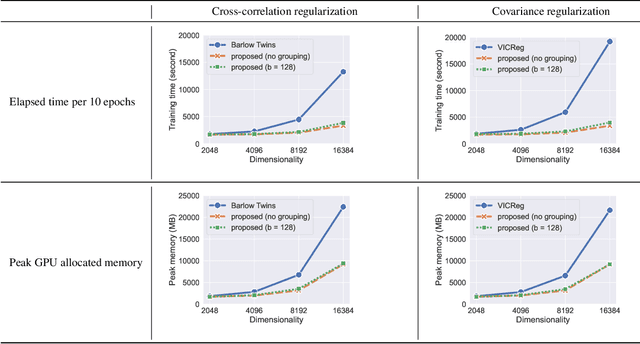
Barlow Twins and VICReg are self-supervised representation learning models that use regularizers to decorrelate features. Although they work as well as conventional representation learning models, their training can be computationally demanding if the dimension of projected representations is high; as these regularizers are defined in terms of individual elements of a cross-correlation or covariance matrix, computing the loss for $d$-dimensional projected representations of $n$ samples takes $O(n d^2)$ time. In this paper, we propose a relaxed version of decorrelating regularizers that can be computed in $O(n d\log d)$ time by the fast Fourier transform. We also propose an inexpensive trick to mitigate the undesirable local minima that develop with the relaxation. Models learning representations using the proposed regularizers show comparable accuracy to existing models in downstream tasks, whereas the training requires less memory and is faster when $d$ is large.
Video Caption Dataset for Describing Human Actions in Japanese
Mar 10, 2020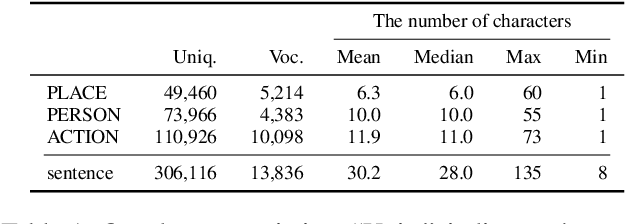

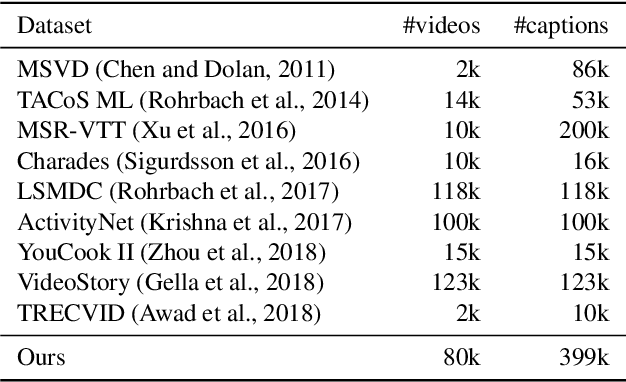
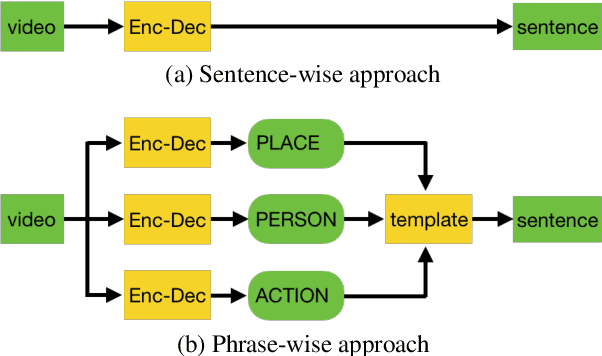
In recent years, automatic video caption generation has attracted considerable attention. This paper focuses on the generation of Japanese captions for describing human actions. While most currently available video caption datasets have been constructed for English, there is no equivalent Japanese dataset. To address this, we constructed a large-scale Japanese video caption dataset consisting of 79,822 videos and 399,233 captions. Each caption in our dataset describes a video in the form of "who does what and where." To describe human actions, it is important to identify the details of a person, place, and action. Indeed, when we describe human actions, we usually mention the scene, person, and action. In our experiments, we evaluated two caption generation methods to obtain benchmark results. Further, we investigated whether those generation methods could specify "who does what and where."
A Fast and Easy Regression Technique for k-NN Classification Without Using Negative Pairs
Jun 11, 2018

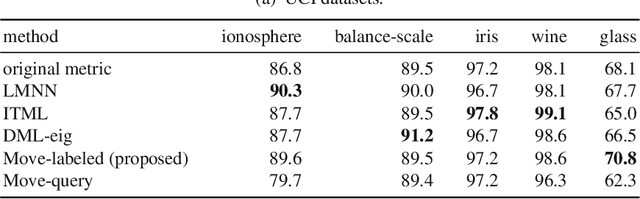

This paper proposes an inexpensive way to learn an effective dissimilarity function to be used for $k$-nearest neighbor ($k$-NN) classification. Unlike Mahalanobis metric learning methods that map both query (unlabeled) objects and labeled objects to new coordinates by a single transformation, our method learns a transformation of labeled objects to new points in the feature space whereas query objects are kept in their original coordinates. This method has several advantages over existing distance metric learning methods: (i) In experiments with large document and image datasets, it achieves $k$-NN classification accuracy better than or at least comparable to the state-of-the-art metric learning methods. (ii) The transformation can be learned efficiently by solving a standard ridge regression problem. For document and image datasets, training is often more than two orders of magnitude faster than the fastest metric learning methods tested. This speed-up is also due to the fact that the proposed method eliminates the optimization over "negative" object pairs, i.e., objects whose class labels are different. (iii) The formulation has a theoretical justification in terms of reducing hubness in data.
STAIR Captions: Constructing a Large-Scale Japanese Image Caption Dataset
May 02, 2017



In recent years, automatic generation of image descriptions (captions), that is, image captioning, has attracted a great deal of attention. In this paper, we particularly consider generating Japanese captions for images. Since most available caption datasets have been constructed for English language, there are few datasets for Japanese. To tackle this problem, we construct a large-scale Japanese image caption dataset based on images from MS-COCO, which is called STAIR Captions. STAIR Captions consists of 820,310 Japanese captions for 164,062 images. In the experiment, we show that a neural network trained using STAIR Captions can generate more natural and better Japanese captions, compared to those generated using English-Japanese machine translation after generating English captions.
Ridge Regression, Hubness, and Zero-Shot Learning
Jul 03, 2015

This paper discusses the effect of hubness in zero-shot learning, when ridge regression is used to find a mapping between the example space to the label space. Contrary to the existing approach, which attempts to find a mapping from the example space to the label space, we show that mapping labels into the example space is desirable to suppress the emergence of hubs in the subsequent nearest neighbor search step. Assuming a simple data model, we prove that the proposed approach indeed reduces hubness. This was verified empirically on the tasks of bilingual lexicon extraction and image labeling: hubness was reduced with both of these tasks and the accuracy was improved accordingly.