 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplicability Condition Extraction for Therapeutic Drug-Disease Relations
Jun 12, 2026Identifying conditions that a certain drug takes therapeutic effect on a target disease is crucial for clinical decision-making support. However, most existing biomedical information extraction methods have focused on identifying only relations between drugs and diseases, while largely overlooking the context-specific conditions where such relations can apply. To address this problem, we introduce the task of applicability condition extraction for therapeutic drug--disease relations from biomedical research literature. We create the first dataset that has manually annotated triples of drugs, diseases, and applicability conditions on biomedical paper abstracts with 1,119 drug-disease pairs. Using this dataset, we systematically evaluate the performance of a range of existing methods. In addition, we propose a new method that enhances LoRA to consider relations between drugs and diseases. Our method consistently outperforms strong baselines across different evaluation settings. The source code and dataset of this paper can be obtained from: https://github.com/guantingluo98/Drug-ACE
PrionNER: A Named Entity Recognition Dataset for Prion Disease Biomedical Literature
May 27, 2026Prion diseases are rare, rapidly progressive, and fatal neurodegenerative disorders that remain difficult to diagnose, particularly in their early stages because of nonspecific clinical presentations. However, to our knowledge, there is no publicly available prion-disease-focused dataset designed to capture a broad range of clinically relevant entities from the biomedical literature. We introduce PrionNER, a manually annotated named entity recognition dataset for prion disease clinical information in PubMed abstracts. The current release comprises 317 abstracts, 2,943 sentences, and 6,955 text-bound entity annotations spanning 15 coarse-grained and 31 fine-grained clinically oriented entity types covering diseases, symptoms, diagnostics, findings, anatomy, treatments, and temporal and statistical evidence. Inter-annotator agreement reaches 81.78 exact-match F1, indicating strong annotation consistency. We benchmark supervised BERT baselines, W2NER, and zero-shot extractors on PrionNER. W2NER is the strongest supervised model, and Gemma-4-31B is the strongest zero-shot model, but the benchmark remains challenging, especially for structurally complex mentions and fine-grained clinically adjacent label distinctions. PrionNER provides a clinically grounded benchmark for prion-disease information extraction and supports research on rare-disease biomedical NLP under low-resource, fine-grained, and non-flat extraction conditions. The dataset, annotation guidelines, and evaluation scripts are available at https://github.com/daotuanan/PrionNER/.
Top-down string-to-dependency Neural Machine Translation
Mar 30, 2026Most of modern neural machine translation (NMT) models are based on an encoder-decoder framework with an attention mechanism. While they perform well on standard datasets, they can have trouble in translation of long inputs that are rare or unseen during training. Incorporating target syntax is one approach to dealing with such length-related problems. We propose a novel syntactic decoder that generates a target-language dependency tree in a top-down, left-to-right order. Experiments show that the proposed top-down string-to-tree decoding generalizes better than conventional sequence-to-sequence decoding in translating long inputs that are not observed in the training data.
The Wisdom of Many Queries: Complexity-Diversity Principle for Dense Retriever Training
Feb 10, 2026Prior work reports conflicting results on query diversity in synthetic data generation for dense retrieval. We identify this conflict and design Q-D metrics to quantify diversity's impact, making the problem measurable. Through experiments on 4 benchmark types (31 datasets), we find query diversity especially benefits multi-hop retrieval. Deep analysis on multi-hop data reveals that diversity benefit correlates strongly with query complexity ($r$$\geq$0.95, $p$$<$0.05 in 12/14 conditions), measured by content words (CW). We formalize this as the Complexity-Diversity Principle (CDP): query complexity determines optimal diversity. CDP provides actionable thresholds (CW$>$10: use diversity; CW$<$7: avoid it). Guided by CDP, we propose zero-shot multi-query synthesis for multi-hop tasks, achieving state-of-the-art performance.
Better Generalizing to Unseen Concepts: An Evaluation Framework and An LLM-Based Auto-Labeled Pipeline for Biomedical Concept Recognition
Jan 23, 2026Generalization to unseen concepts is a central challenge due to the scarcity of human annotations in Mention-agnostic Biomedical Concept Recognition (MA-BCR). This work makes two key contributions to systematically address this issue. First, we propose an evaluation framework built on hierarchical concept indices and novel metrics to measure generalization. Second, we explore LLM-based Auto-Labeled Data (ALD) as a scalable resource, creating a task-specific pipeline for its generation. Our research unequivocally shows that while LLM-generated ALD cannot fully substitute for manual annotations, it is a valuable resource for improving generalization, successfully providing models with the broader coverage and structural knowledge needed to approach recognizing unseen concepts. Code and datasets are available at https://github.com/bio-ie-tool/hi-ald.
Post Persona Alignment for Multi-Session Dialogue Generation
Jun 13, 2025



Multi-session persona-based dialogue generation presents challenges in maintaining long-term consistency and generating diverse, personalized responses. While large language models (LLMs) excel in single-session dialogues, they struggle to preserve persona fidelity and conversational coherence across extended interactions. Existing methods typically retrieve persona information before response generation, which can constrain diversity and result in generic outputs. We propose Post Persona Alignment (PPA), a novel two-stage framework that reverses this process. PPA first generates a general response based solely on dialogue context, then retrieves relevant persona memories using the response as a query, and finally refines the response to align with the speaker's persona. This post-hoc alignment strategy promotes naturalness and diversity while preserving consistency and personalization. Experiments on multi-session LLM-generated dialogue data demonstrate that PPA significantly outperforms prior approaches in consistency, diversity, and persona relevance, offering a more flexible and effective paradigm for long-term personalized dialogue generation.
MA-COIR: Leveraging Semantic Search Index and Generative Models for Ontology-Driven Biomedical Concept Recognition
May 19, 2025Recognizing biomedical concepts in the text is vital for ontology refinement, knowledge graph construction, and concept relationship discovery. However, traditional concept recognition methods, relying on explicit mention identification, often fail to capture complex concepts not explicitly stated in the text. To overcome this limitation, we introduce MA-COIR, a framework that reformulates concept recognition as an indexing-recognition task. By assigning semantic search indexes (ssIDs) to concepts, MA-COIR resolves ambiguities in ontology entries and enhances recognition efficiency. Using a pretrained BART-based model fine-tuned on small datasets, our approach reduces computational requirements to facilitate adoption by domain experts. Furthermore, we incorporate large language models (LLMs)-generated queries and synthetic data to improve recognition in low-resource settings. Experimental results on three scenarios (CDR, HPO, and HOIP) highlight the effectiveness of MA-COIR in recognizing both explicit and implicit concepts without the need for mention-level annotations during inference, advancing ontology-driven concept recognition in biomedical domain applications. Our code and constructed data are available at https://github.com/sl-633/macoir-master.
Recent Trends in Personalized Dialogue Generation: A Review of Datasets, Methodologies, and Evaluations
May 28, 2024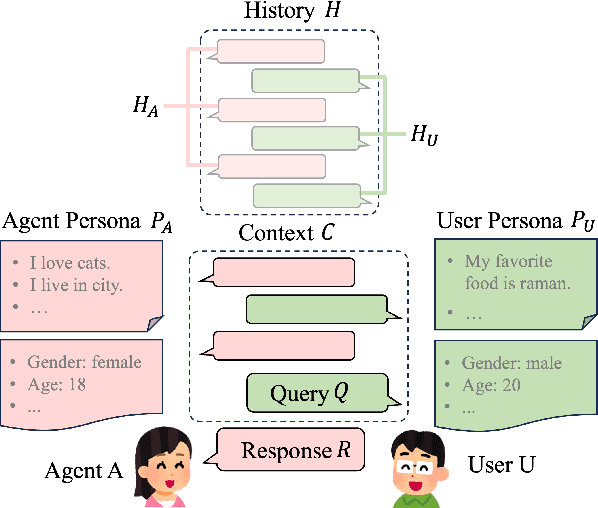



Enhancing user engagement through personalization in conversational agents has gained significance, especially with the advent of large language models that generate fluent responses. Personalized dialogue generation, however, is multifaceted and varies in its definition -- ranging from instilling a persona in the agent to capturing users' explicit and implicit cues. This paper seeks to systemically survey the recent landscape of personalized dialogue generation, including the datasets employed, methodologies developed, and evaluation metrics applied. Covering 22 datasets, we highlight benchmark datasets and newer ones enriched with additional features. We further analyze 17 seminal works from top conferences between 2021-2023 and identify five distinct types of problems. We also shed light on recent progress by LLMs in personalized dialogue generation. Our evaluation section offers a comprehensive summary of assessment facets and metrics utilized in these works. In conclusion, we discuss prevailing challenges and envision prospect directions for future research in personalized dialogue generation.
A Dataset for Pharmacovigilance in German, French, and Japanese: Annotating Adverse Drug Reactions across Languages
Mar 27, 2024



User-generated data sources have gained significance in uncovering Adverse Drug Reactions (ADRs), with an increasing number of discussions occurring in the digital world. However, the existing clinical corpora predominantly revolve around scientific articles in English. This work presents a multilingual corpus of texts concerning ADRs gathered from diverse sources, including patient fora, social media, and clinical reports in German, French, and Japanese. Our corpus contains annotations covering 12 entity types, four attribute types, and 13 relation types. It contributes to the development of real-world multilingual language models for healthcare. We provide statistics to highlight certain challenges associated with the corpus and conduct preliminary experiments resulting in strong baselines for extracting entities and relations between these entities, both within and across languages.
Unsupervised Paraphrasing of Multiword Expressions
Jun 02, 2023We propose an unsupervised approach to paraphrasing multiword expressions (MWEs) in context. Our model employs only monolingual corpus data and pre-trained language models (without fine-tuning), and does not make use of any external resources such as dictionaries. We evaluate our method on the SemEval 2022 idiomatic semantic text similarity task, and show that it outperforms all unsupervised systems and rivals supervised systems.