 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost Persona Alignment for Multi-Session Dialogue Generation
Jun 13, 2025



Multi-session persona-based dialogue generation presents challenges in maintaining long-term consistency and generating diverse, personalized responses. While large language models (LLMs) excel in single-session dialogues, they struggle to preserve persona fidelity and conversational coherence across extended interactions. Existing methods typically retrieve persona information before response generation, which can constrain diversity and result in generic outputs. We propose Post Persona Alignment (PPA), a novel two-stage framework that reverses this process. PPA first generates a general response based solely on dialogue context, then retrieves relevant persona memories using the response as a query, and finally refines the response to align with the speaker's persona. This post-hoc alignment strategy promotes naturalness and diversity while preserving consistency and personalization. Experiments on multi-session LLM-generated dialogue data demonstrate that PPA significantly outperforms prior approaches in consistency, diversity, and persona relevance, offering a more flexible and effective paradigm for long-term personalized dialogue generation.
Exploring and Controlling Diversity in LLM-Agent Conversation
Dec 30, 2024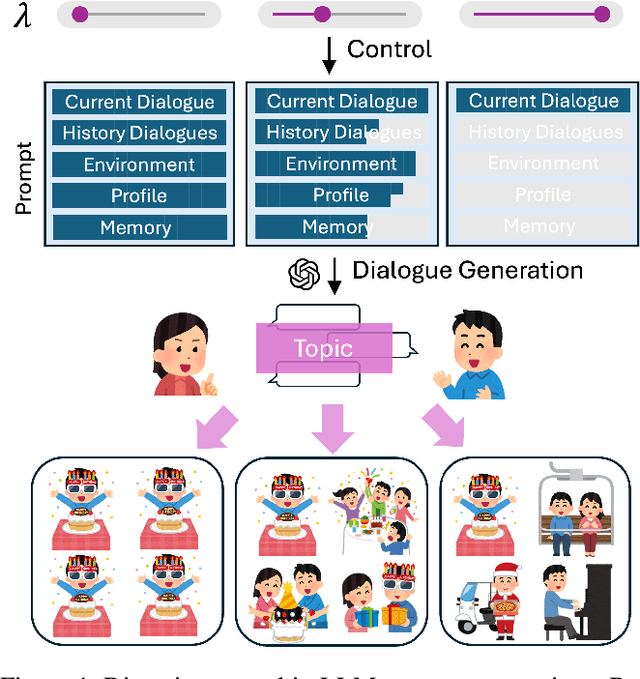
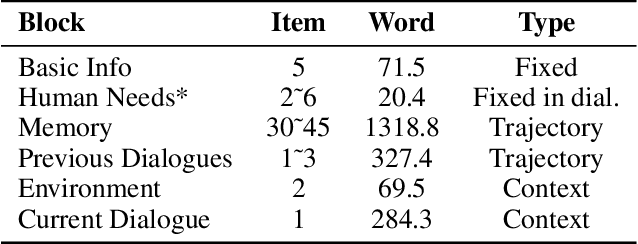
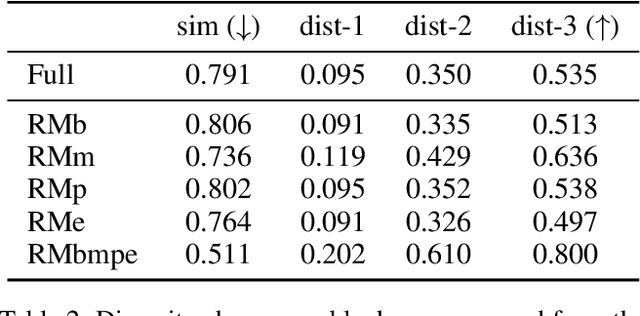
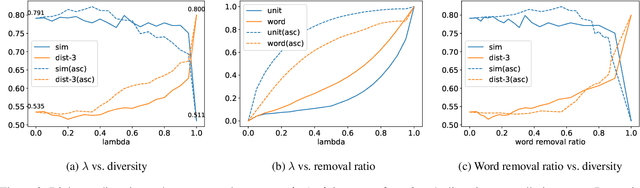
Diversity is a critical aspect of multi-agent communication. In this paper, we focus on controlling and exploring diversity in the context of open-domain multi-agent conversations, particularly for world simulation applications. We propose Adaptive Prompt Pruning (APP), a novel method that dynamically adjusts the content of the utterance generation prompt to control diversity using a single parameter, lambda. Through extensive experiments, we show that APP effectively controls the output diversity across models and datasets, with pruning more information leading to more diverse output. We comprehensively analyze the relationship between prompt content and conversational diversity. Our findings reveal that information from all components of the prompt generally constrains the diversity of the output, with the Memory block exerting the most significant influence. APP is compatible with established techniques like temperature sampling and top-p sampling, providing a versatile tool for diversity management. To address the trade-offs of increased diversity, such as inconsistencies with omitted information, we incorporate a post-generation correction step, which effectively balances diversity enhancement with output consistency. Additionally, we examine how prompt structure, including component order and length, impacts diversity. This study addresses key questions surrounding diversity in multi-agent world simulation, offering insights into its control, influencing factors, and associated trade-offs. Our contributions lay the foundation for systematically engineering diversity in LLM-based multi-agent collaborations, advancing their effectiveness in real-world applications.
Cohesive Conversations: Enhancing Authenticity in Multi-Agent Simulated Dialogues
Jul 13, 2024

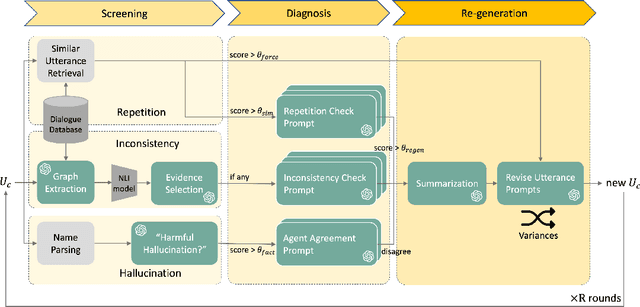
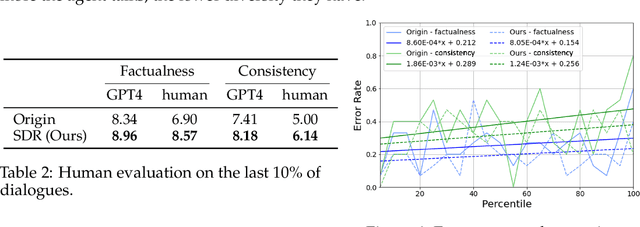
This paper investigates the quality of multi-agent dialogues in simulations powered by Large Language Models (LLMs), focusing on a case study from Park et al. (2023), where 25 agents engage in day-long simulations of life, showcasing complex behaviors and interactions. Analyzing dialogues and memory over multiple sessions revealed significant issues such as repetition, inconsistency, and hallucination, exacerbated by the propagation of erroneous information. To combat these challenges, we propose a novel Screening, Diagnosis, and Regeneration (SDR) framework that detects and corrects utterance errors through a comprehensive process involving immediate issue identification, evidence gathering from past dialogues, and LLM analysis for utterance revision. The effectiveness of the SDR framework is validated through GPT-4 assessments and human evaluations, demonstrating marked improvements in dialogue consistency, diversity, and the reduction of false information. This work presents a pioneering approach to enhancing dialogue quality in multi-agent simulations, establishing a new standard for future research in the field.
A Better LLM Evaluator for Text Generation: The Impact of Prompt Output Sequencing and Optimization
Jun 14, 2024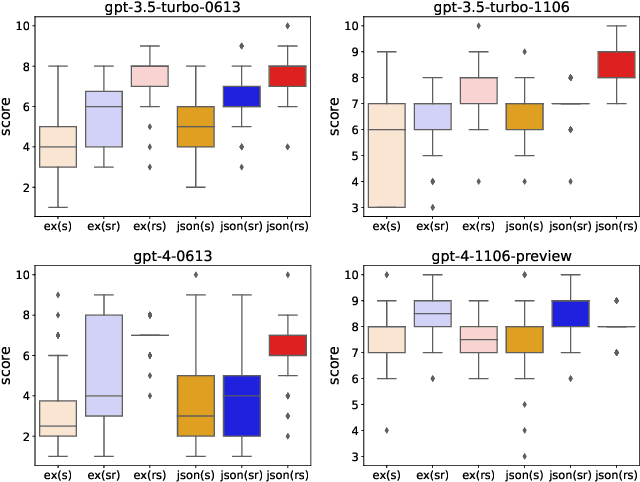


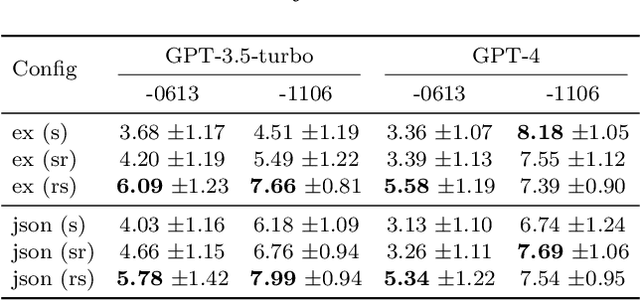
This research investigates prompt designs of evaluating generated texts using large language models (LLMs). While LLMs are increasingly used for scoring various inputs, creating effective prompts for open-ended text evaluation remains challenging due to model sensitivity and subjectivity in evaluation of text generation. Our study experimented with different prompt structures, altering the sequence of output instructions and including explanatory reasons. We found that the order of presenting reasons and scores significantly influences LLMs' scoring, with a different level of rule understanding in the prompt. An additional optimization may enhance scoring alignment if sufficient data is available. This insight is crucial for improving the accuracy and consistency of LLM-based evaluations.
LLM as a Scorer: The Impact of Output Order on Dialogue Evaluation
Jun 05, 2024



This research investigates the effect of prompt design on dialogue evaluation using large language models (LLMs). While LLMs are increasingly used for scoring various inputs, creating effective prompts for dialogue evaluation remains challenging due to model sensitivity and subjectivity in dialogue assessments. Our study experimented with different prompt structures, altering the sequence of output instructions and including explanatory reasons. We found that the order of presenting reasons and scores significantly influences LLMs' scoring, with a "reason-first" approach yielding more comprehensive evaluations. This insight is crucial for enhancing the accuracy and consistency of LLM-based evaluations.
Recent Trends in Personalized Dialogue Generation: A Review of Datasets, Methodologies, and Evaluations
May 28, 2024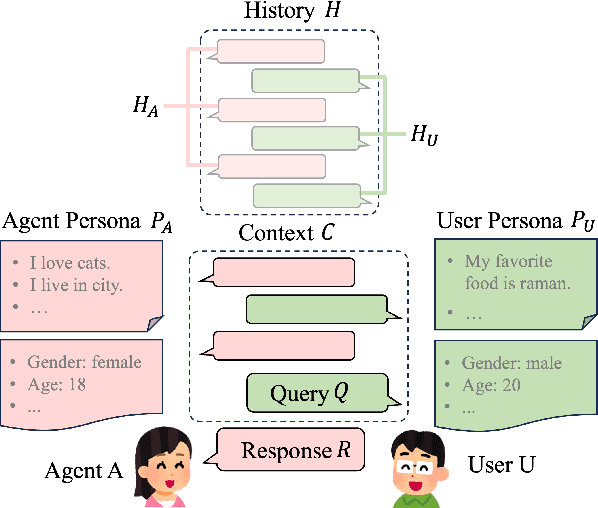



Enhancing user engagement through personalization in conversational agents has gained significance, especially with the advent of large language models that generate fluent responses. Personalized dialogue generation, however, is multifaceted and varies in its definition -- ranging from instilling a persona in the agent to capturing users' explicit and implicit cues. This paper seeks to systemically survey the recent landscape of personalized dialogue generation, including the datasets employed, methodologies developed, and evaluation metrics applied. Covering 22 datasets, we highlight benchmark datasets and newer ones enriched with additional features. We further analyze 17 seminal works from top conferences between 2021-2023 and identify five distinct types of problems. We also shed light on recent progress by LLMs in personalized dialogue generation. Our evaluation section offers a comprehensive summary of assessment facets and metrics utilized in these works. In conclusion, we discuss prevailing challenges and envision prospect directions for future research in personalized dialogue generation.
LED: A Dataset for Life Event Extraction from Dialogs
Apr 17, 2023
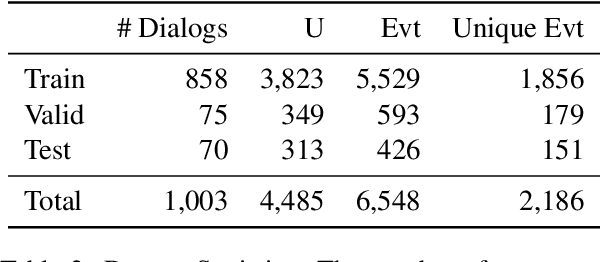
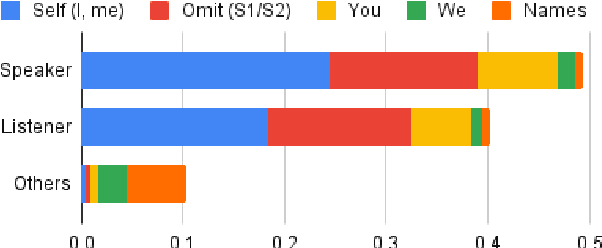
Lifelogging has gained more attention due to its wide applications, such as personalized recommendations or memory assistance. The issues of collecting and extracting personal life events have emerged. People often share their life experiences with others through conversations. However, extracting life events from conversations is rarely explored. In this paper, we present Life Event Dialog, a dataset containing fine-grained life event annotations on conversational data. In addition, we initiate a novel conversational life event extraction task and differentiate the task from the public event extraction or the life event extraction from other sources like microblogs. We explore three information extraction (IE) frameworks to address the conversational life event extraction task: OpenIE, relation extraction, and event extraction. A comprehensive empirical analysis of the three baselines is established. The results suggest that the current event extraction model still struggles with extracting life events from human daily conversations. Our proposed life event dialog dataset and in-depth analysis of IE frameworks will facilitate future research on life event extraction from conversations.
Breaking Down Multilingual Machine Translation
Oct 15, 2021
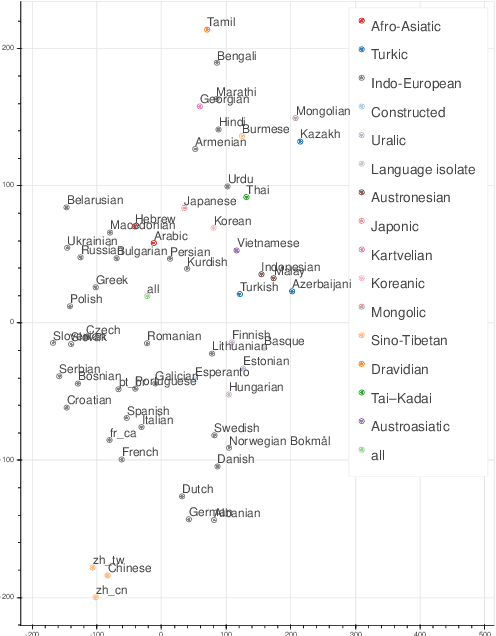
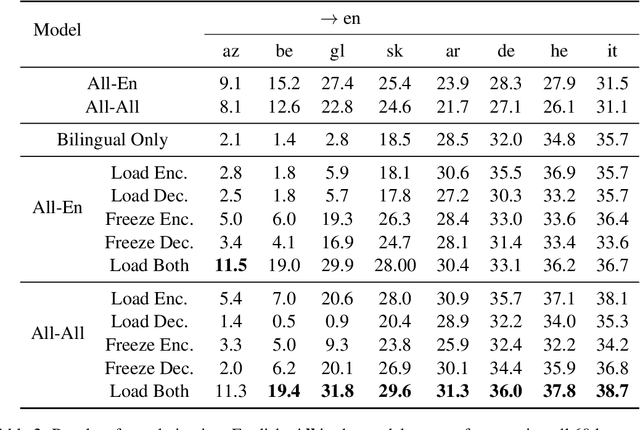
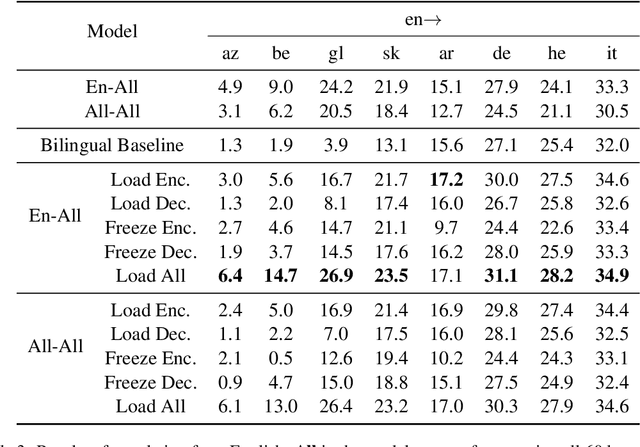
While multilingual training is now an essential ingredient in machine translation (MT) systems, recent work has demonstrated that it has different effects in different multilingual settings, such as many-to-one, one-to-many, and many-to-many learning. These training settings expose the encoder and the decoder in a machine translation model with different data distributions. In this paper, we examine how different varieties of multilingual training contribute to learning these two components of the MT model. Specifically, we compare bilingual models with encoders and/or decoders initialized by multilingual training. We show that multilingual training is beneficial to encoders in general, while it only benefits decoders for low-resource languages (LRLs). We further find the important attention heads for each language pair and compare their correlations during inference. Our analysis sheds light on how multilingual translation models work and also enables us to propose methods to improve performance by training with highly related languages. Our many-to-one models for high-resource languages and one-to-many models for LRL outperform the best results reported by Aharoni et al. (2019).
UHop: An Unrestricted-Hop Relation Extraction Framework for Knowledge-Based Question Answering
Apr 02, 2019

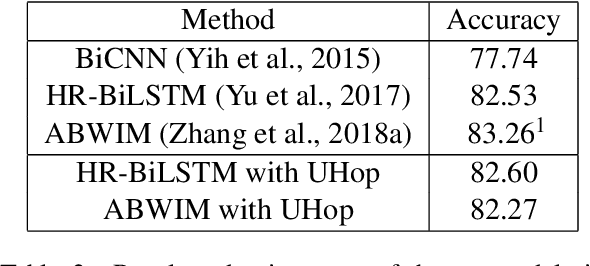
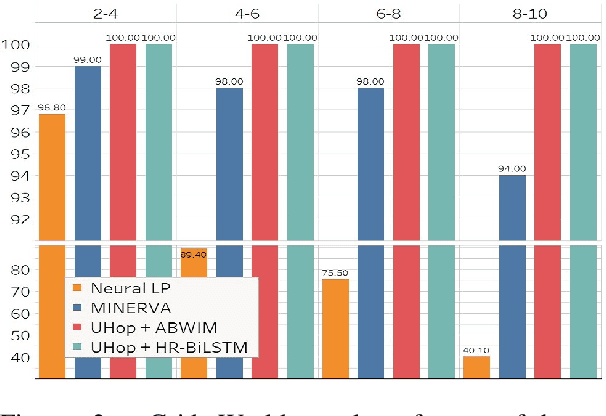
In relation extraction for knowledge-based question answering, searching from one entity to another entity via a single relation is called "one hop". In related work, an exhaustive search from all one-hop relations, two-hop relations, and so on to the max-hop relations in the knowledge graph is necessary but expensive. Therefore, the number of hops is generally restricted to two or three. In this paper, we propose UHop, an unrestricted-hop framework which relaxes this restriction by use of a transition-based search framework to replace the relation-chain-based search one. We conduct experiments on conventional 1- and 2-hop questions as well as lengthy questions, including datasets such as WebQSP, PathQuestion, and Grid World. Results show that the proposed framework enables the ability to halt, works well with state-of-the-art models, achieves competitive performance without exhaustive searches, and opens the performance gap for long relation paths.
MoodSwipe: A Soft Keyboard that Suggests Messages Based on User-Specified Emotions
Jul 22, 2017


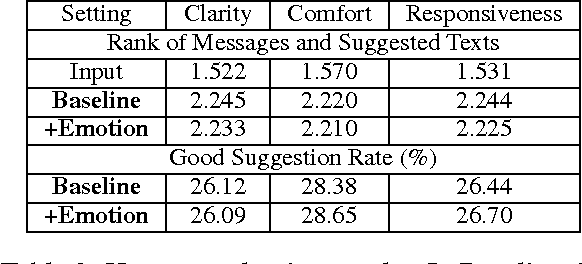
We present MoodSwipe, a soft keyboard that suggests text messages given the user-specified emotions utilizing the real dialog data. The aim of MoodSwipe is to create a convenient user interface to enjoy the technology of emotion classification and text suggestion, and at the same time to collect labeled data automatically for developing more advanced technologies. While users select the MoodSwipe keyboard, they can type as usual but sense the emotion conveyed by their text and receive suggestions for their message as a benefit. In MoodSwipe, the detected emotions serve as the medium for suggested texts, where viewing the latter is the incentive to correcting the former. We conduct several experiments to show the superiority of the emotion classification models trained on the dialog data, and further to verify good emotion cues are important context for text suggestion.