 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCohesive Conversations: Enhancing Authenticity in Multi-Agent Simulated Dialogues
Paper and Code


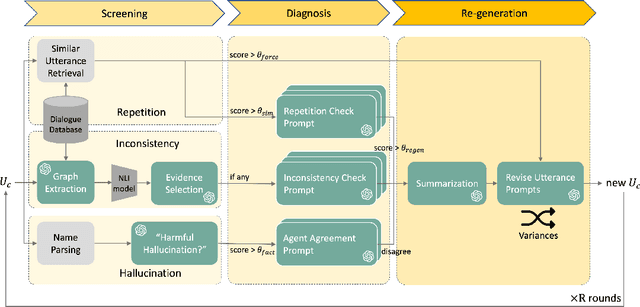
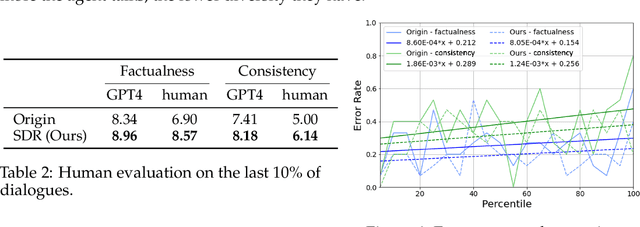
This paper investigates the quality of multi-agent dialogues in simulations powered by Large Language Models (LLMs), focusing on a case study from Park et al. (2023), where 25 agents engage in day-long simulations of life, showcasing complex behaviors and interactions. Analyzing dialogues and memory over multiple sessions revealed significant issues such as repetition, inconsistency, and hallucination, exacerbated by the propagation of erroneous information. To combat these challenges, we propose a novel Screening, Diagnosis, and Regeneration (SDR) framework that detects and corrects utterance errors through a comprehensive process involving immediate issue identification, evidence gathering from past dialogues, and LLM analysis for utterance revision. The effectiveness of the SDR framework is validated through GPT-4 assessments and human evaluations, demonstrating marked improvements in dialogue consistency, diversity, and the reduction of false information. This work presents a pioneering approach to enhancing dialogue quality in multi-agent simulations, establishing a new standard for future research in the field.