 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring and Controlling Diversity in LLM-Agent Conversation
Dec 30, 2024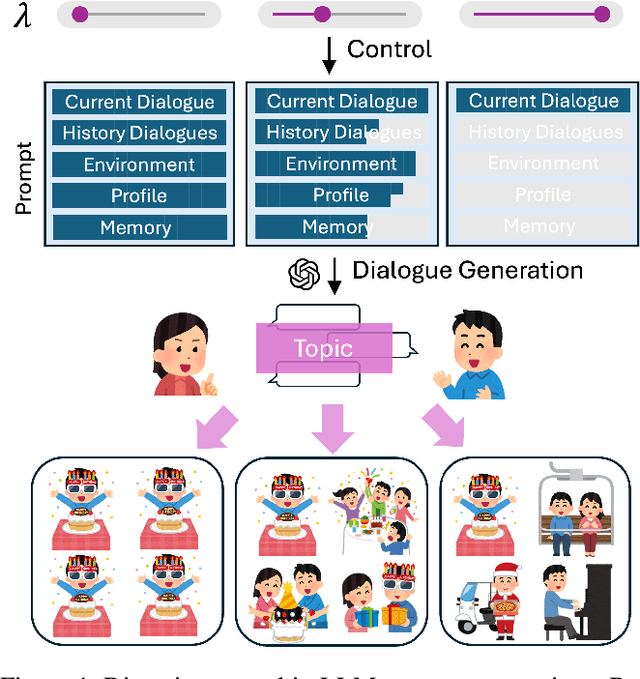
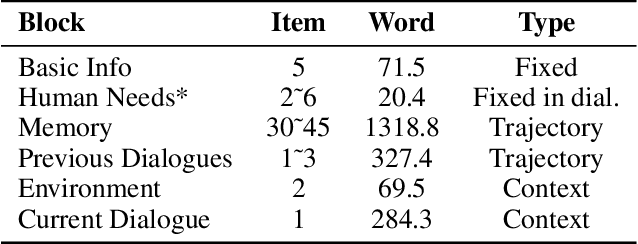
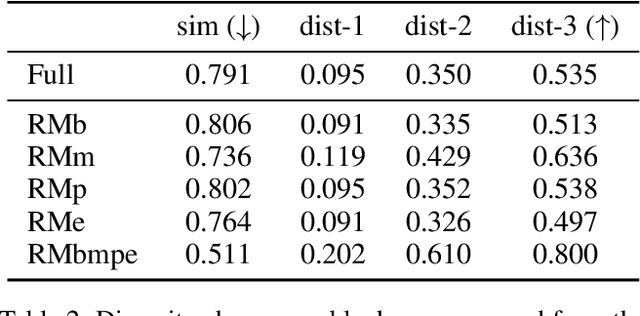
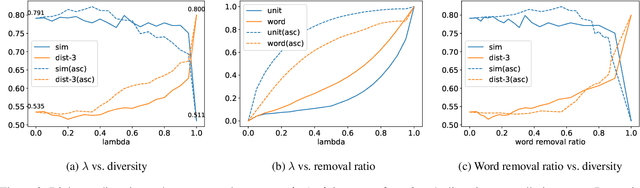
Diversity is a critical aspect of multi-agent communication. In this paper, we focus on controlling and exploring diversity in the context of open-domain multi-agent conversations, particularly for world simulation applications. We propose Adaptive Prompt Pruning (APP), a novel method that dynamically adjusts the content of the utterance generation prompt to control diversity using a single parameter, lambda. Through extensive experiments, we show that APP effectively controls the output diversity across models and datasets, with pruning more information leading to more diverse output. We comprehensively analyze the relationship between prompt content and conversational diversity. Our findings reveal that information from all components of the prompt generally constrains the diversity of the output, with the Memory block exerting the most significant influence. APP is compatible with established techniques like temperature sampling and top-p sampling, providing a versatile tool for diversity management. To address the trade-offs of increased diversity, such as inconsistencies with omitted information, we incorporate a post-generation correction step, which effectively balances diversity enhancement with output consistency. Additionally, we examine how prompt structure, including component order and length, impacts diversity. This study addresses key questions surrounding diversity in multi-agent world simulation, offering insights into its control, influencing factors, and associated trade-offs. Our contributions lay the foundation for systematically engineering diversity in LLM-based multi-agent collaborations, advancing their effectiveness in real-world applications.
Cohesive Conversations: Enhancing Authenticity in Multi-Agent Simulated Dialogues
Jul 13, 2024

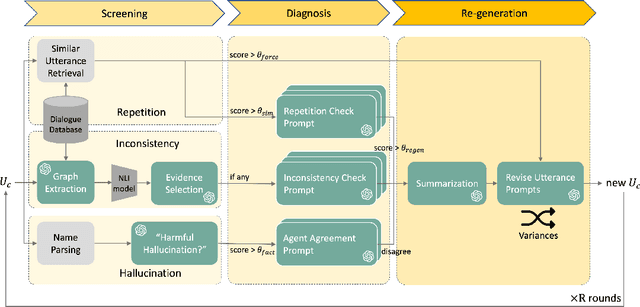
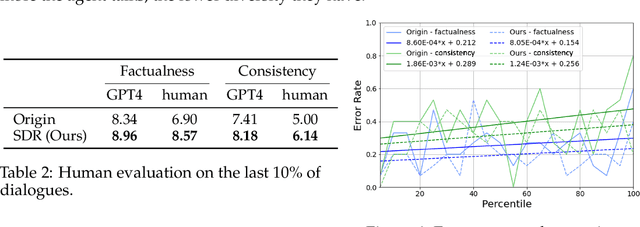
This paper investigates the quality of multi-agent dialogues in simulations powered by Large Language Models (LLMs), focusing on a case study from Park et al. (2023), where 25 agents engage in day-long simulations of life, showcasing complex behaviors and interactions. Analyzing dialogues and memory over multiple sessions revealed significant issues such as repetition, inconsistency, and hallucination, exacerbated by the propagation of erroneous information. To combat these challenges, we propose a novel Screening, Diagnosis, and Regeneration (SDR) framework that detects and corrects utterance errors through a comprehensive process involving immediate issue identification, evidence gathering from past dialogues, and LLM analysis for utterance revision. The effectiveness of the SDR framework is validated through GPT-4 assessments and human evaluations, demonstrating marked improvements in dialogue consistency, diversity, and the reduction of false information. This work presents a pioneering approach to enhancing dialogue quality in multi-agent simulations, establishing a new standard for future research in the field.
Enhanced Data Transfer Cooperating with Artificial Triplets for Scene Graph Generation
Jun 27, 2024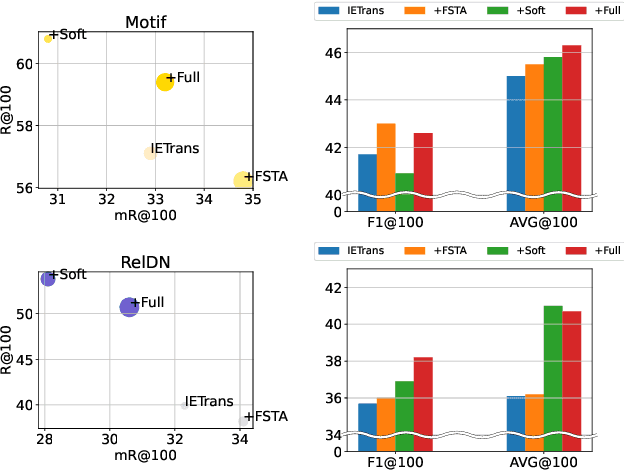

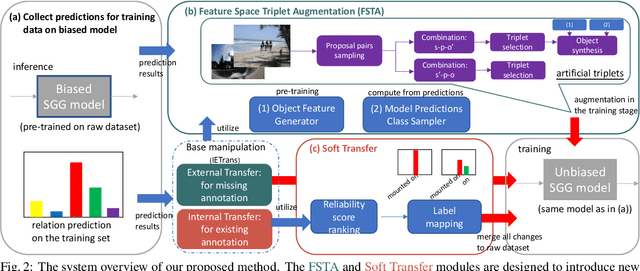

This work focuses on training dataset enhancement of informative relational triplets for Scene Graph Generation (SGG). Due to the lack of effective supervision, the current SGG model predictions perform poorly for informative relational triplets with inadequate training samples. Therefore, we propose two novel training dataset enhancement modules: Feature Space Triplet Augmentation (FSTA) and Soft Transfer. FSTA leverages a feature generator trained to generate representations of an object in relational triplets. The biased prediction based sampling in FSTA efficiently augments artificial triplets focusing on the challenging ones. In addition, we introduce Soft Transfer, which assigns soft predicate labels to general relational triplets to make more supervisions for informative predicate classes effectively. Experimental results show that integrating FSTA and Soft Transfer achieve high levels of both Recall and mean Recall in Visual Genome dataset. The mean of Recall and mean Recall is the highest among all the existing model-agnostic methods.
A Better LLM Evaluator for Text Generation: The Impact of Prompt Output Sequencing and Optimization
Jun 14, 2024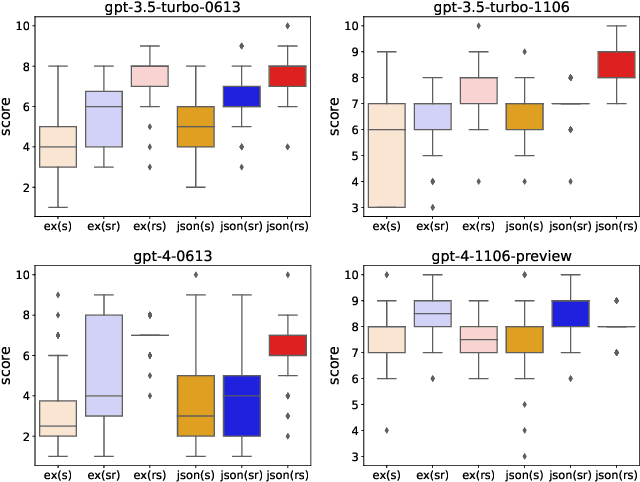


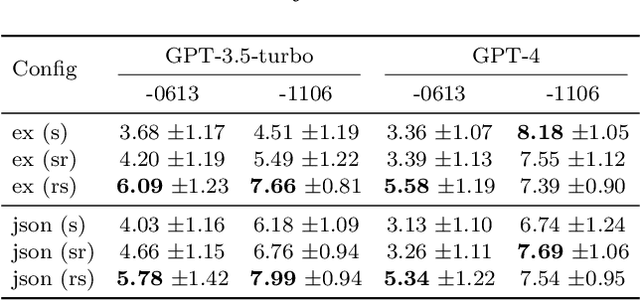
This research investigates prompt designs of evaluating generated texts using large language models (LLMs). While LLMs are increasingly used for scoring various inputs, creating effective prompts for open-ended text evaluation remains challenging due to model sensitivity and subjectivity in evaluation of text generation. Our study experimented with different prompt structures, altering the sequence of output instructions and including explanatory reasons. We found that the order of presenting reasons and scores significantly influences LLMs' scoring, with a different level of rule understanding in the prompt. An additional optimization may enhance scoring alignment if sufficient data is available. This insight is crucial for improving the accuracy and consistency of LLM-based evaluations.
LLM as a Scorer: The Impact of Output Order on Dialogue Evaluation
Jun 05, 2024



This research investigates the effect of prompt design on dialogue evaluation using large language models (LLMs). While LLMs are increasingly used for scoring various inputs, creating effective prompts for dialogue evaluation remains challenging due to model sensitivity and subjectivity in dialogue assessments. Our study experimented with different prompt structures, altering the sequence of output instructions and including explanatory reasons. We found that the order of presenting reasons and scores significantly influences LLMs' scoring, with a "reason-first" approach yielding more comprehensive evaluations. This insight is crucial for enhancing the accuracy and consistency of LLM-based evaluations.