 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias in the Ear of the Listener: Assessing Sensitivity in Audio Language Models Across Linguistic, Demographic, and Positional Variations
Feb 01, 2026This work presents the first systematic investigation of speech bias in multilingual MLLMs. We construct and release the BiasInEar dataset, a speech-augmented benchmark based on Global MMLU Lite, spanning English, Chinese, and Korean, balanced by gender and accent, and totaling 70.8 hours ($\approx$4,249 minutes) of speech with 11,200 questions. Using four complementary metrics (accuracy, entropy, APES, and Fleiss' $κ$), we evaluate nine representative models under linguistic (language and accent), demographic (gender), and structural (option order) perturbations. Our findings reveal that MLLMs are relatively robust to demographic factors but highly sensitive to language and option order, suggesting that speech can amplify existing structural biases. Moreover, architectural design and reasoning strategy substantially affect robustness across languages. Overall, this study establishes a unified framework for assessing fairness and robustness in speech-integrated LLMs, bridging the gap between text- and speech-based evaluation. The resources can be found at https://github.com/ntunlplab/BiasInEar.
Beyond Known Facts: Generating Unseen Temporal Knowledge to Address Data Contamination in LLM Evaluation
Jan 20, 2026The automatic extraction of information is important for populating large web knowledge bases such as Wikidata. The temporal version of that task, temporal knowledge graph extraction (TKGE), involves extracting temporally grounded facts from text, represented as semantic quadruples (subject, relation, object, timestamp). Many recent systems take advantage of large language models (LLMs), which are becoming a new cornerstone of the web due to their performance on many tasks across the natural language processing (NLP) field. Despite the importance of TKGE, existing datasets for training and evaluation remain scarce, and contamination of evaluation data is an unaddressed issue, potentially inflating LLMs' perceived performance due to overlaps between training and evaluation sets. To mitigate these challenges, we propose a novel synthetic evaluation dataset constructed from predicted future, previously unseen temporal facts, thereby eliminating contamination and enabling robust and unbiased benchmarking. Our dataset creation involves a two-step approach: (1) Temporal Knowledge Graph Forecasting (TKGF) generates plausible future quadruples, which are subsequently filtered to adhere to the original knowledge base schema; (2) LLMs perform quadruple-to-text generation, creating semantically aligned textual descriptions. We benchmark Extract, Define and Canonicalize (EDC), a state-of-the-art LLM-based extraction framework, demonstrating that LLM performance decreases when evaluated on our dataset compared to a dataset of known facts. We publicly release our dataset consisting of 4.2K future quadruples and corresponding textual descriptions, along with the generation methodology, enabling continuous creation of unlimited future temporal datasets to serve as long-term, contamination-free benchmarks for TKGE.
Using Contextually Aligned Online Reviews to Measure LLMs' Performance Disparities Across Language Varieties
Feb 10, 2025A language can have different varieties. These varieties can affect the performance of natural language processing (NLP) models, including large language models (LLMs), which are often trained on data from widely spoken varieties. This paper introduces a novel and cost-effective approach to benchmark model performance across language varieties. We argue that international online review platforms, such as Booking.com, can serve as effective data sources for constructing datasets that capture comments in different language varieties from similar real-world scenarios, like reviews for the same hotel with the same rating using the same language (e.g., Mandarin Chinese) but different language varieties (e.g., Taiwan Mandarin, Mainland Mandarin). To prove this concept, we constructed a contextually aligned dataset comprising reviews in Taiwan Mandarin and Mainland Mandarin and tested six LLMs in a sentiment analysis task. Our results show that LLMs consistently underperform in Taiwan Mandarin.
SmartSpatial: Enhancing the 3D Spatial Arrangement Capabilities of Stable Diffusion Models and Introducing a Novel 3D Spatial Evaluation Framework
Jan 01, 2025Stable Diffusion models have made remarkable strides in generating photorealistic images from text prompts but often falter when tasked with accurately representing complex spatial arrangements, particularly involving intricate 3D relationships. To address this limitation, we introduce SmartSpatial, an innovative approach that enhances the spatial arrangement capabilities of Stable Diffusion models through 3D-aware conditioning and attention-guided mechanisms. SmartSpatial incorporates depth information and employs cross-attention control to ensure precise object placement, delivering notable improvements in spatial accuracy metrics. In conjunction with SmartSpatial, we present SmartSpatialEval, a comprehensive evaluation framework designed to assess spatial relationships. This framework utilizes vision-language models and graph-based dependency parsing for performance analysis. Experimental results on the COCO and SpatialPrompts datasets show that SmartSpatial significantly outperforms existing methods, setting new benchmarks for spatial arrangement accuracy in image generation.
Don't Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks
Dec 20, 2024



Retrieval-augmented generation (RAG) has gained traction as a powerful approach for enhancing language models by integrating external knowledge sources. However, RAG introduces challenges such as retrieval latency, potential errors in document selection, and increased system complexity. With the advent of large language models (LLMs) featuring significantly extended context windows, this paper proposes an alternative paradigm, cache-augmented generation (CAG) that bypasses real-time retrieval. Our method involves preloading all relevant resources, especially when the documents or knowledge for retrieval are of a limited and manageable size, into the LLM's extended context and caching its runtime parameters. During inference, the model utilizes these preloaded parameters to answer queries without additional retrieval steps. Comparative analyses reveal that CAG eliminates retrieval latency and minimizes retrieval errors while maintaining context relevance. Performance evaluations across multiple benchmarks highlight scenarios where long-context LLMs either outperform or complement traditional RAG pipelines. These findings suggest that, for certain applications, particularly those with a constrained knowledge base, CAG provide a streamlined and efficient alternative to RAG, achieving comparable or superior results with reduced complexity.
Co-Trained Retriever-Generator Framework for Question Generation in Earnings Calls
Sep 27, 2024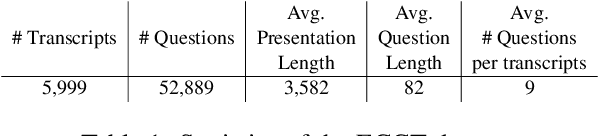


In diverse professional environments, ranging from academic conferences to corporate earnings calls, the ability to anticipate audience questions stands paramount. Traditional methods, which rely on manual assessment of an audience's background, interests, and subject knowledge, often fall short - particularly when facing large or heterogeneous groups, leading to imprecision and inefficiency. While NLP has made strides in text-based question generation, its primary focus remains on academic settings, leaving the intricate challenges of professional domains, especially earnings call conferences, underserved. Addressing this gap, our paper pioneers the multi-question generation (MQG) task specifically designed for earnings call contexts. Our methodology involves an exhaustive collection of earnings call transcripts and a novel annotation technique to classify potential questions. Furthermore, we introduce a retriever-enhanced strategy to extract relevant information. With a core aim of generating a spectrum of potential questions that analysts might pose, we derive these directly from earnings call content. Empirical evaluations underscore our approach's edge, revealing notable excellence in the accuracy, consistency, and perplexity of the questions generated.
"Why" Has the Least Side Effect on Model Editing
Sep 27, 2024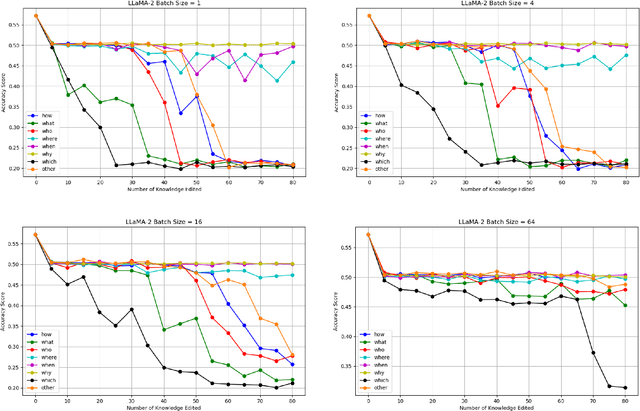

Training large language models (LLMs) from scratch is an expensive endeavor, particularly as world knowledge continually evolves. To maintain relevance and accuracy of LLMs, model editing has emerged as a pivotal research area. While these methods hold promise, they can also produce unintended side effects. Their underlying factors and causes remain largely unexplored. This paper delves into a critical factor-question type-by categorizing model editing questions. Our findings reveal that the extent of performance degradation varies significantly across different question types, providing new insights for experimental design in knowledge editing. Furthermore, we investigate whether insights from smaller models can be extrapolated to larger models. Our results indicate discrepancies in findings between models of different sizes, suggesting that insights from smaller models may not necessarily apply to larger models. Additionally, we examine the impact of batch size on side effects, discovering that increasing the batch size can mitigate performance drops.
Pre-Finetuning with Impact Duration Awareness for Stock Movement Prediction
Sep 25, 2024



Understanding the duration of news events' impact on the stock market is crucial for effective time-series forecasting, yet this facet is largely overlooked in current research. This paper addresses this research gap by introducing a novel dataset, the Impact Duration Estimation Dataset (IDED), specifically designed to estimate impact duration based on investor opinions. Our research establishes that pre-finetuning language models with IDED can enhance performance in text-based stock movement predictions. In addition, we juxtapose our proposed pre-finetuning task with sentiment analysis pre-finetuning, further affirming the significance of learning impact duration. Our findings highlight the promise of this novel research direction in stock movement prediction, offering a new avenue for financial forecasting. We also provide the IDED and pre-finetuned language models under the CC BY-NC-SA 4.0 license for academic use, fostering further exploration in this field.
Enhancing Investment Opinion Ranking through Argument-Based Sentiment Analysis
Sep 25, 2024
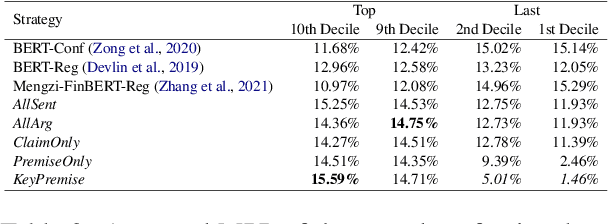


In the era of rapid Internet and social media platform development, individuals readily share their viewpoints online. The overwhelming quantity of these posts renders comprehensive analysis impractical. This necessitates an efficient recommendation system to filter and present significant, relevant opinions. Our research introduces a dual-pronged argument mining technique to improve recommendation system effectiveness, considering both professional and amateur investor perspectives. Our first strategy involves using the discrepancy between target and closing prices as an opinion indicator. The second strategy applies argument mining principles to score investors' opinions, subsequently ranking them by these scores. Experimental results confirm the effectiveness of our approach, demonstrating its ability to identify opinions with higher profit potential. Beyond profitability, our research extends to risk analysis, examining the relationship between recommended opinions and investor behaviors. This offers a holistic view of potential outcomes following the adoption of these recommended opinions.
Unveiling Selection Biases: Exploring Order and Token Sensitivity in Large Language Models
Jun 05, 2024In this paper, we investigate the phenomena of "selection biases" in Large Language Models (LLMs), focusing on problems where models are tasked with choosing the optimal option from an ordered sequence. We delve into biases related to option order and token usage, which significantly impact LLMs' decision-making processes. We also quantify the impact of these biases through an extensive empirical analysis across multiple models and tasks. Furthermore, we propose mitigation strategies to enhance model performance. Our key contributions are threefold: 1) Precisely quantifying the influence of option order and token on LLMs, 2) Developing strategies to mitigate the impact of token and order sensitivity to enhance robustness, and 3) Offering a detailed analysis of sensitivity across models and tasks, which informs the creation of more stable and reliable LLM applications for selection problems.