 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategy-Induct: Task-Level Strategy Induction for Instruction Generation
May 20, 2026Designing effective task-level prompts is crucial for improving the performance of Large Language Models (LLMs). While prior work on instruction induction demonstrates that LLMs can infer better instructions with limited examples, existing approaches often rely on input-output pairs, where obtaining labeled answers can be difficult or costly. To address this limitation, we propose Strategy-Induct, a framework that derives task-level instructions solely from a small set of example questions without requiring labeled answers. Our approach first prompts the model to generate explicit reasoning strategies for each question, forming (strategy, question) pairs. These pairs are then used to induce a task instruction that guides reasoning. Experiments across multiple tasks and model scales demonstrate that Strategy-Induct outperforms state-of-the-art methods in question-only settings. Furthermore, we observe that jointly utilizing LLMs and Large Reasoning Models across task instruction generation and inference may lead to further performance improvements.
Personalized Graph-Empowered Large Language Model for Proactive Information Access
Feb 25, 2026Since individuals may struggle to recall all life details and often confuse events, establishing a system to assist users in recalling forgotten experiences is essential. While numerous studies have proposed memory recall systems, these primarily rely on deep learning techniques that require extensive training and often face data scarcity due to the limited availability of personal lifelogs. As lifelogs grow over time, systems must also adapt quickly to newly accumulated data. Recently, large language models (LLMs) have demonstrated remarkable capabilities across various tasks, making them promising for personalized applications. In this work, we present a framework that leverages LLMs for proactive information access, integrating personal knowledge graphs to enhance the detection of access needs through a refined decision-making process. Our framework offers high flexibility, enabling the replacement of base models and the modification of fact retrieval methods for continuous improvement. Experimental results demonstrate that our approach effectively identifies forgotten events, supporting users in recalling past experiences more efficiently.
Diverge to Induce Prompting: Multi-Rationale Induction for Zero-Shot Reasoning
Feb 08, 2026To address the instability of unguided reasoning paths in standard Chain-of-Thought prompting, recent methods guide large language models (LLMs) by first eliciting a single reasoning strategy. However, relying on just one strategy for each question can still limit performance across diverse tasks. We propose Diverge-to-Induce Prompting (DIP), a framework that first prompts an LLM to generate multiple diverse high-level rationales for each question. Each rationale is then elaborated into a detailed, step-by-step draft plan. Finally, these draft plans are induced into a final plan. DIP enhances zero-shot reasoning accuracy without reliance on resource-intensive sampling. Experiments show that DIP outperforms single-strategy prompting, demonstrating the effectiveness of multi-plan induction for prompt-based reasoning.
Bias in the Ear of the Listener: Assessing Sensitivity in Audio Language Models Across Linguistic, Demographic, and Positional Variations
Feb 01, 2026This work presents the first systematic investigation of speech bias in multilingual MLLMs. We construct and release the BiasInEar dataset, a speech-augmented benchmark based on Global MMLU Lite, spanning English, Chinese, and Korean, balanced by gender and accent, and totaling 70.8 hours ($\approx$4,249 minutes) of speech with 11,200 questions. Using four complementary metrics (accuracy, entropy, APES, and Fleiss' $κ$), we evaluate nine representative models under linguistic (language and accent), demographic (gender), and structural (option order) perturbations. Our findings reveal that MLLMs are relatively robust to demographic factors but highly sensitive to language and option order, suggesting that speech can amplify existing structural biases. Moreover, architectural design and reasoning strategy substantially affect robustness across languages. Overall, this study establishes a unified framework for assessing fairness and robustness in speech-integrated LLMs, bridging the gap between text- and speech-based evaluation. The resources can be found at https://github.com/ntunlplab/BiasInEar.
Hearing the Order: Investigating Selection Bias in Large Audio-Language Models
Oct 01, 2025Large audio-language models (LALMs) are often used in tasks that involve reasoning over ordered options. An open question is whether their predictions are influenced by the order of answer choices, which would indicate a form of selection bias and undermine their reliability. In this paper, we identify and analyze this problem in LALMs. We demonstrate that no model is immune to this bias through extensive experiments on six LALMs across three widely used benchmarks and their spoken counterparts. Shuffling the order of answer options can cause performance fluctuations of up to 24% and even change model rankings, raising concerns about the reliability of current evaluation practices. We also study permutation-based strategies and show that they can mitigate bias in most cases. Our work represents the first systematic investigation of this issue in LALMs, and we hope it raises awareness and motivates further research in this direction.
Evaluating Large Language Models as Expert Annotators
Aug 11, 2025Textual data annotation, the process of labeling or tagging text with relevant information, is typically costly, time-consuming, and labor-intensive. While large language models (LLMs) have demonstrated their potential as direct alternatives to human annotators for general domains natural language processing (NLP) tasks, their effectiveness on annotation tasks in domains requiring expert knowledge remains underexplored. In this paper, we investigate: whether top-performing LLMs, which might be perceived as having expert-level proficiency in academic and professional benchmarks, can serve as direct alternatives to human expert annotators? To this end, we evaluate both individual LLMs and multi-agent approaches across three highly specialized domains: finance, biomedicine, and law. Specifically, we propose a multi-agent discussion framework to simulate a group of human annotators, where LLMs are tasked to engage in discussions by considering others' annotations and justifications before finalizing their labels. Additionally, we incorporate reasoning models (e.g., o3-mini) to enable a more comprehensive comparison. Our empirical results reveal that: (1) Individual LLMs equipped with inference-time techniques (e.g., chain-of-thought (CoT), self-consistency) show only marginal or even negative performance gains, contrary to prior literature suggesting their broad effectiveness. (2) Overall, reasoning models do not demonstrate statistically significant improvements over non-reasoning models in most settings. This suggests that extended long CoT provides relatively limited benefits for data annotation in specialized domains. (3) Certain model behaviors emerge in the multi-agent discussion environment. For instance, Claude 3.7 Sonnet with thinking rarely changes its initial annotations, even when other agents provide correct annotations or valid reasoning.
Are Expert-Level Language Models Expert-Level Annotators?
Oct 04, 2024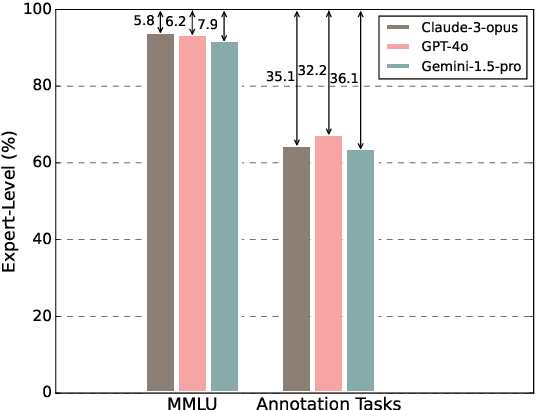
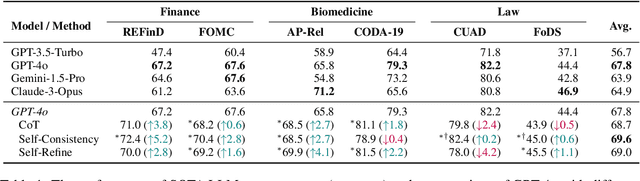
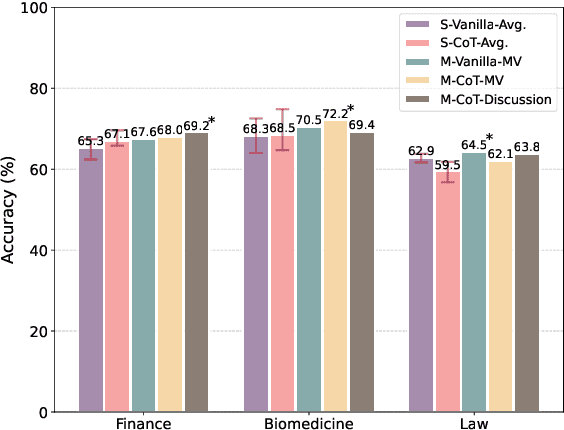
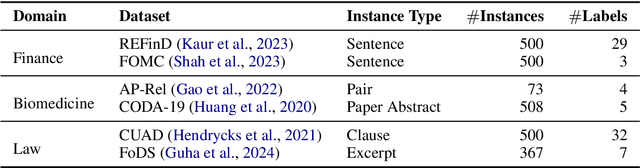
Data annotation refers to the labeling or tagging of textual data with relevant information. A large body of works have reported positive results on leveraging LLMs as an alternative to human annotators. However, existing studies focus on classic NLP tasks, and the extent to which LLMs as data annotators perform in domains requiring expert knowledge remains underexplored. In this work, we investigate comprehensive approaches across three highly specialized domains and discuss practical suggestions from a cost-effectiveness perspective. To the best of our knowledge, we present the first systematic evaluation of LLMs as expert-level data annotators.
Co-Trained Retriever-Generator Framework for Question Generation in Earnings Calls
Sep 27, 2024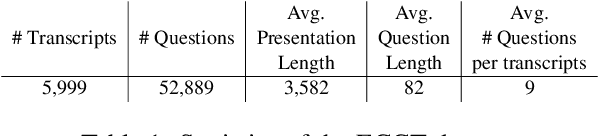


In diverse professional environments, ranging from academic conferences to corporate earnings calls, the ability to anticipate audience questions stands paramount. Traditional methods, which rely on manual assessment of an audience's background, interests, and subject knowledge, often fall short - particularly when facing large or heterogeneous groups, leading to imprecision and inefficiency. While NLP has made strides in text-based question generation, its primary focus remains on academic settings, leaving the intricate challenges of professional domains, especially earnings call conferences, underserved. Addressing this gap, our paper pioneers the multi-question generation (MQG) task specifically designed for earnings call contexts. Our methodology involves an exhaustive collection of earnings call transcripts and a novel annotation technique to classify potential questions. Furthermore, we introduce a retriever-enhanced strategy to extract relevant information. With a core aim of generating a spectrum of potential questions that analysts might pose, we derive these directly from earnings call content. Empirical evaluations underscore our approach's edge, revealing notable excellence in the accuracy, consistency, and perplexity of the questions generated.
"Why" Has the Least Side Effect on Model Editing
Sep 27, 2024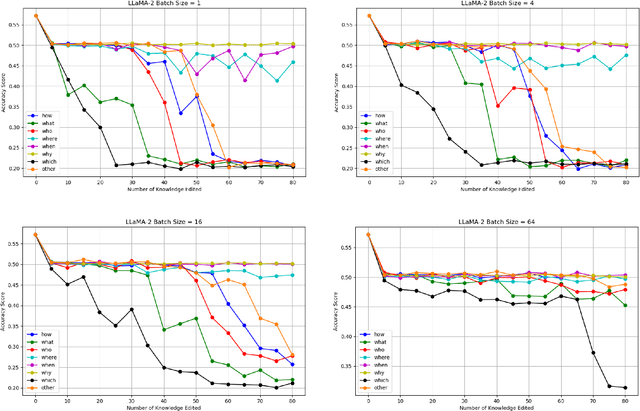

Training large language models (LLMs) from scratch is an expensive endeavor, particularly as world knowledge continually evolves. To maintain relevance and accuracy of LLMs, model editing has emerged as a pivotal research area. While these methods hold promise, they can also produce unintended side effects. Their underlying factors and causes remain largely unexplored. This paper delves into a critical factor-question type-by categorizing model editing questions. Our findings reveal that the extent of performance degradation varies significantly across different question types, providing new insights for experimental design in knowledge editing. Furthermore, we investigate whether insights from smaller models can be extrapolated to larger models. Our results indicate discrepancies in findings between models of different sizes, suggesting that insights from smaller models may not necessarily apply to larger models. Additionally, we examine the impact of batch size on side effects, discovering that increasing the batch size can mitigate performance drops.
Pre-Finetuning with Impact Duration Awareness for Stock Movement Prediction
Sep 25, 2024



Understanding the duration of news events' impact on the stock market is crucial for effective time-series forecasting, yet this facet is largely overlooked in current research. This paper addresses this research gap by introducing a novel dataset, the Impact Duration Estimation Dataset (IDED), specifically designed to estimate impact duration based on investor opinions. Our research establishes that pre-finetuning language models with IDED can enhance performance in text-based stock movement predictions. In addition, we juxtapose our proposed pre-finetuning task with sentiment analysis pre-finetuning, further affirming the significance of learning impact duration. Our findings highlight the promise of this novel research direction in stock movement prediction, offering a new avenue for financial forecasting. We also provide the IDED and pre-finetuned language models under the CC BY-NC-SA 4.0 license for academic use, fostering further exploration in this field.