 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHearing the Order: Investigating Selection Bias in Large Audio-Language Models
Oct 01, 2025Large audio-language models (LALMs) are often used in tasks that involve reasoning over ordered options. An open question is whether their predictions are influenced by the order of answer choices, which would indicate a form of selection bias and undermine their reliability. In this paper, we identify and analyze this problem in LALMs. We demonstrate that no model is immune to this bias through extensive experiments on six LALMs across three widely used benchmarks and their spoken counterparts. Shuffling the order of answer options can cause performance fluctuations of up to 24% and even change model rankings, raising concerns about the reliability of current evaluation practices. We also study permutation-based strategies and show that they can mitigate bias in most cases. Our work represents the first systematic investigation of this issue in LALMs, and we hope it raises awareness and motivates further research in this direction.
Few-Shot Cross-Lingual TTS Using Transferable Phoneme Embedding
Jun 27, 2022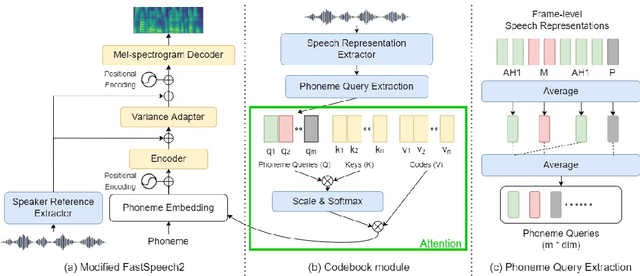

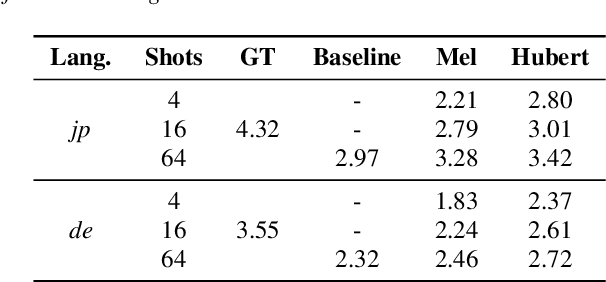
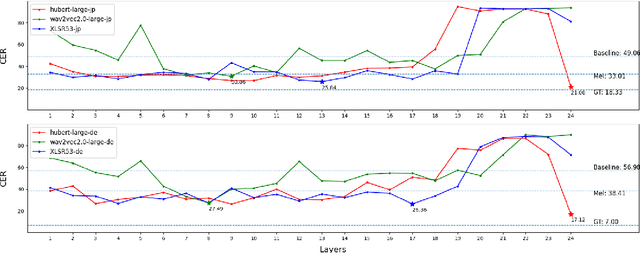
This paper studies a transferable phoneme embedding framework that aims to deal with the cross-lingual text-to-speech (TTS) problem under the few-shot setting. Transfer learning is a common approach when it comes to few-shot learning since training from scratch on few-shot training data is bound to overfit. Still, we find that the naive transfer learning approach fails to adapt to unseen languages under extremely few-shot settings, where less than 8 minutes of data is provided. We deal with the problem by proposing a framework that consists of a phoneme-based TTS model and a codebook module to project phonemes from different languages into a learned latent space. Furthermore, by utilizing phoneme-level averaged self-supervised learned features, we effectively improve the quality of synthesized speeches. Experiments show that using 4 utterances, which is about 30 seconds of data, is enough to synthesize intelligible speech when adapting to an unseen language using our framework.
Dynamic Time-Aware Attention to Speaker Roles and Contexts for Spoken Language Understanding
Dec 08, 2017


Spoken language understanding (SLU) is an essential component in conversational systems. Most SLU component treats each utterance independently, and then the following components aggregate the multi-turn information in the separate phases. In order to avoid error propagation and effectively utilize contexts, prior work leveraged history for contextual SLU. However, the previous model only paid attention to the content in history utterances without considering their temporal information and speaker roles. In the dialogues, the most recent utterances should be more important than the least recent ones. Furthermore, users usually pay attention to 1) self history for reasoning and 2) others' utterances for listening, the speaker of the utterances may provides informative cues to help understanding. Therefore, this paper proposes an attention-based network that additionally leverages temporal information and speaker role for better SLU, where the attention to contexts and speaker roles can be automatically learned in an end-to-end manner. The experiments on the benchmark Dialogue State Tracking Challenge 4 (DSTC4) dataset show that the time-aware dynamic role attention networks significantly improve the understanding performance.
Speaker Role Contextual Modeling for Language Understanding and Dialogue Policy Learning
Sep 30, 2017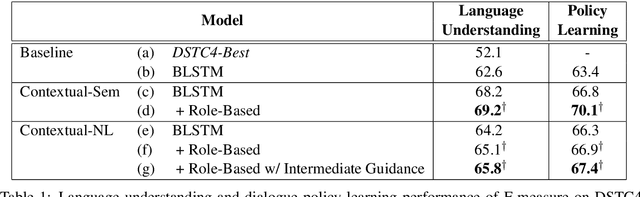

Language understanding (LU) and dialogue policy learning are two essential components in conversational systems. Human-human dialogues are not well-controlled and often random and unpredictable due to their own goals and speaking habits. This paper proposes a role-based contextual model to consider different speaker roles independently based on the various speaking patterns in the multi-turn dialogues. The experiments on the benchmark dataset show that the proposed role-based model successfully learns role-specific behavioral patterns for contextual encoding and then significantly improves language understanding and dialogue policy learning tasks.