 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Cross-Lingual TTS Using Transferable Phoneme Embedding
Paper and Code
Jun 27, 2022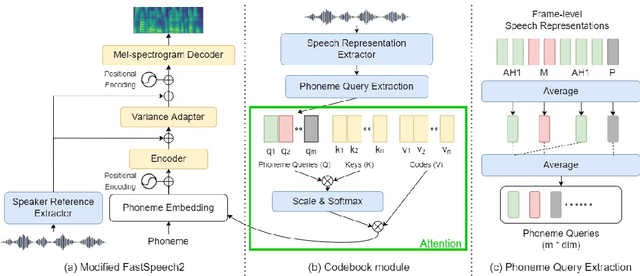

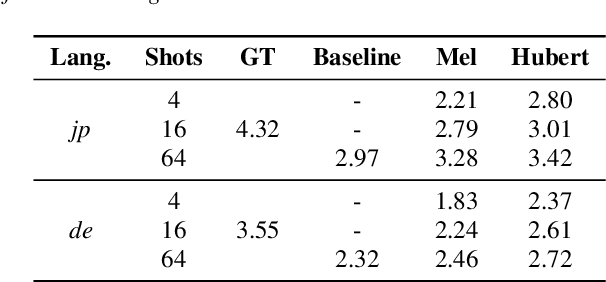
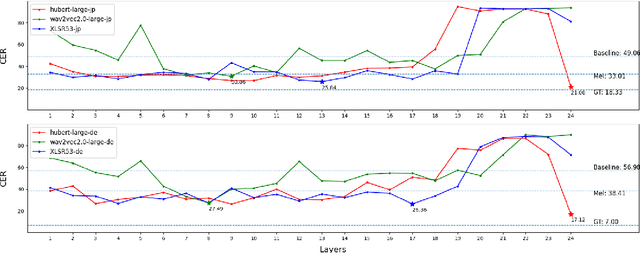
This paper studies a transferable phoneme embedding framework that aims to deal with the cross-lingual text-to-speech (TTS) problem under the few-shot setting. Transfer learning is a common approach when it comes to few-shot learning since training from scratch on few-shot training data is bound to overfit. Still, we find that the naive transfer learning approach fails to adapt to unseen languages under extremely few-shot settings, where less than 8 minutes of data is provided. We deal with the problem by proposing a framework that consists of a phoneme-based TTS model and a codebook module to project phonemes from different languages into a learned latent space. Furthermore, by utilizing phoneme-level averaged self-supervised learned features, we effectively improve the quality of synthesized speeches. Experiments show that using 4 utterances, which is about 30 seconds of data, is enough to synthesize intelligible speech when adapting to an unseen language using our framework.