 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Contrastive Decoding Enhances Large Audio Language Models?
Mar 10, 2026While Contrastive Decoding (CD) has proven effective at enhancing Large Audio Language Models (LALMs), the underlying mechanisms driving its success and the comparative efficacy of different strategies remain unclear. This study systematically evaluates four distinct CD strategies across diverse LALM architectures. We identify Audio-Aware Decoding and Audio Contrastive Decoding as the most effective methods. However, their impact varies significantly by model. To explain this variability, we introduce a Transition Matrix framework to map error pattern shifts during inference. Our analysis demonstrates that CD reliably rectifies errors in which models falsely claim an absence of audio or resort to uncertainty-driven guessing. Conversely, it fails to correct flawed reasoning or confident misassertions. Ultimately, these findings provide a clear guideline for determining which LALM architectures are most suitable for CD enhancement based on their baseline error profiles.
DeSTA2.5-Audio: Toward General-Purpose Large Audio Language Model with Self-Generated Cross-Modal Alignment
Jul 03, 2025
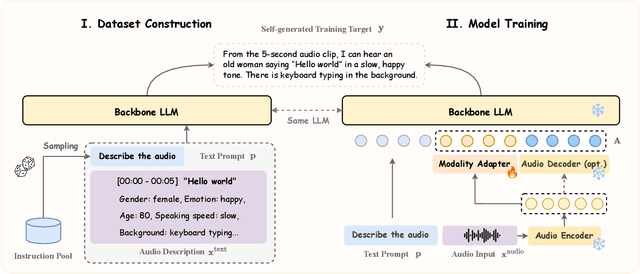


We introduce DeSTA2.5-Audio, a general-purpose Large Audio Language Model (LALM) designed for robust auditory perception and instruction-following, without requiring task-specific audio instruction-tuning. Recent LALMs typically augment Large Language Models (LLMs) with auditory capabilities by training on large-scale, manually curated or LLM-synthesized audio-instruction datasets. However, these approaches have often suffered from the catastrophic forgetting of the LLM's original language abilities. To address this, we revisit the data construction pipeline and propose DeSTA, a self-generated cross-modal alignment strategy in which the backbone LLM generates its own training targets. This approach preserves the LLM's native language proficiency while establishing effective audio-text alignment, thereby enabling zero-shot generalization without task-specific tuning. Using DeSTA, we construct DeSTA-AQA5M, a large-scale, task-agnostic dataset containing 5 million training samples derived from 7,000 hours of audio spanning 50 diverse datasets, including speech, environmental sounds, and music. DeSTA2.5-Audio achieves state-of-the-art or competitive performance across a wide range of audio-language benchmarks, including Dynamic-SUPERB, MMAU, SAKURA, Speech-IFEval, and VoiceBench. Comprehensive comparative studies demonstrate that our self-generated strategy outperforms widely adopted data construction and training strategies in both auditory perception and instruction-following capabilities. Our findings underscore the importance of carefully designed data construction in LALM development and offer practical insights for building robust, general-purpose LALMs.
Speech-FT: A Fine-tuning Strategy for Enhancing Speech Representation Models Without Compromising Generalization Ability
Feb 18, 2025



Speech representation models are highly effective at extracting general features for various tasks. While fine-tuning can enhance these representations for specific applications, it often compromises their generalization ability. To address this challenge, we propose Speech-FT, a fine-tuning strategy for speech representation models that leverages model merging to preserve generalization ability while still benefiting from fine-tuning. Speech-FT is effective across different fine-tuning scenarios and is compatible with various types of speech representation models, providing a versatile solution. Speech-FT offers an efficient and practical approach to further improving general speech representations after pre-training.
Building a Taiwanese Mandarin Spoken Language Model: A First Attempt
Nov 11, 2024



This technical report presents our initial attempt to build a spoken large language model (LLM) for Taiwanese Mandarin, specifically tailored to enable real-time, speech-to-speech interaction in multi-turn conversations. Our end-to-end model incorporates a decoder-only transformer architecture and aims to achieve seamless interaction while preserving the conversational flow, including full-duplex capabilities allowing simultaneous speaking and listening. The paper also details the training process, including data preparation with synthesized dialogues and adjustments for real-time interaction. We also developed a platform to evaluate conversational fluency and response coherence in multi-turn dialogues. We hope the release of the report can contribute to the future development of spoken LLMs in Taiwanese Mandarin.
Speech-Copilot: Leveraging Large Language Models for Speech Processing via Task Decomposition, Modularization, and Program Generation
Jul 13, 2024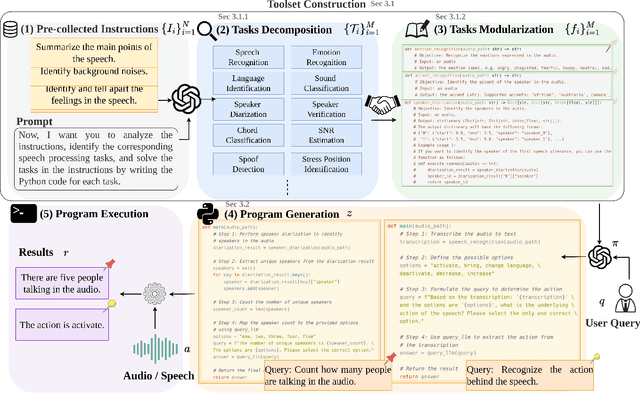
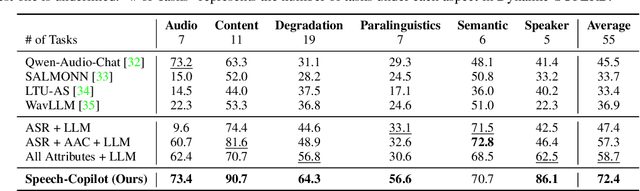


In this work, we introduce Speech-Copilot, a modular framework for instruction-oriented speech-processing tasks that minimizes human effort in toolset construction. Unlike end-to-end methods using large audio-language models, Speech-Copilot builds speech processing-specific toolsets by analyzing pre-collected task instructions and breaking tasks into manageable sub-tasks. It features a flexible agent based on large language models that performs tasks through program generation. Our approach achieves state-of-the-art performance on the Dynamic-SUPERB benchmark, demonstrating its effectiveness across diverse speech-processing tasks. Key contributions include: 1) developing an innovative framework for speech processing-specific toolset construction, 2) establishing a high-performing agent based on large language models, and 3) offering a new perspective on addressing challenging instruction-oriented speech-processing tasks. Without additional training processes required by end-to-end approaches, our method provides a flexible and extendable solution for a wide range of speech-processing applications.
Continual Test-time Adaptation for End-to-end Speech Recognition on Noisy Speech
Jun 16, 2024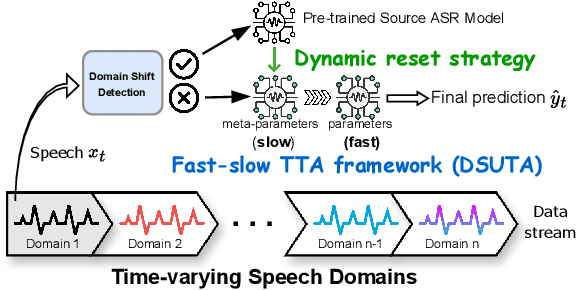
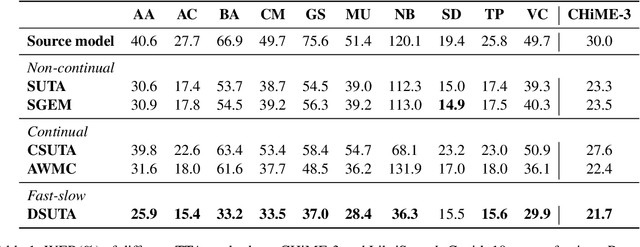
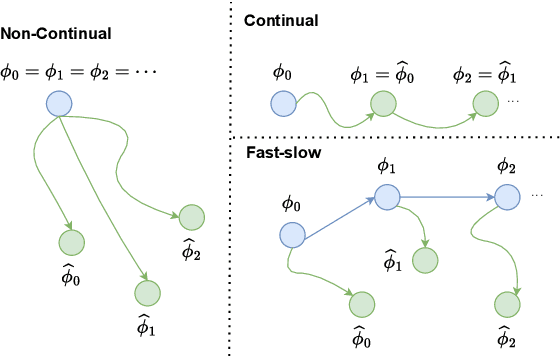
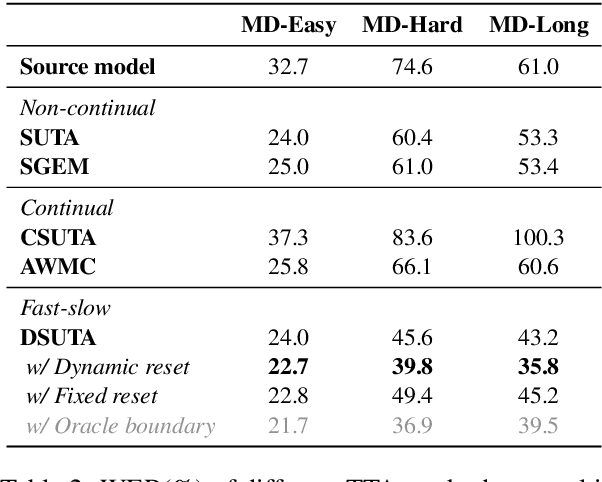
Deep learning-based end-to-end automatic speech recognition (ASR) has made significant strides but still struggles with performance on out-of-domain (OOD) samples due to domain shifts in real-world scenarios. Test-Time Adaptation (TTA) methods address this issue by adapting models using test samples at inference time. However, current ASR TTA methods have largely focused on non-continual TTA, which limits cross-sample knowledge learning compared to continual TTA. In this work, we propose a Fast-slow TTA framework for ASR, which leverages the advantage of continual and non-continual TTA. Within this framework, we introduce Dynamic SUTA (DSUTA), an entropy-minimization-based continual TTA method for ASR. To enhance DSUTA's robustness on time-varying data, we propose a dynamic reset strategy that automatically detects domain shifts and resets the model, making it more effective at handling multi-domain data. Our method demonstrates superior performance on various noisy ASR datasets, outperforming both non-continual and continual TTA baselines while maintaining robustness to domain changes without requiring domain boundary information.
Understanding Sounds, Missing the Questions: The Challenge of Object Hallucination in Large Audio-Language Models
Jun 12, 2024



Large audio-language models (LALMs) enhance traditional large language models by integrating audio perception capabilities, allowing them to tackle audio-related tasks. Previous research has primarily focused on assessing the performance of LALMs across various tasks, yet overlooking their reliability, particularly concerning issues like object hallucination. In our study, we introduce methods to assess the extent of object hallucination of publicly available LALMs. Our findings reveal that LALMs are comparable to specialized audio captioning models in their understanding of audio content, but struggle to answer discriminative questions, specifically those requiring the identification of the presence of particular object sounds within an audio clip. This limitation highlights a critical weakness in current LALMs: their inadequate understanding of discriminative queries. Moreover, we explore the potential of prompt engineering to enhance LALMs' performance on discriminative questions.
Maximizing Data Efficiency for Cross-Lingual TTS Adaptation by Self-Supervised Representation Mixing and Embedding Initialization
Jan 23, 2024This paper presents an effective transfer learning framework for language adaptation in text-to-speech systems, with a focus on achieving language adaptation using minimal labeled and unlabeled data. While many works focus on reducing the usage of labeled data, very few consider minimizing the usage of unlabeled data. By utilizing self-supervised features in the pretraining stage, replacing the noisy portion of pseudo labels with these features during fine-tuning, and incorporating an embedding initialization trick, our method leverages more information from unlabeled data compared to conventional approaches. Experimental results show that our framework is able to synthesize intelligible speech in unseen languages with only 4 utterances of labeled data and 15 minutes of unlabeled data. Our methodology continues to surpass conventional techniques, even when a greater volume of data is accessible. These findings highlight the potential of our data-efficient language adaptation framework.
Findings of the 2023 ML-SUPERB Challenge: Pre-Training and Evaluation over More Languages and Beyond
Oct 09, 2023

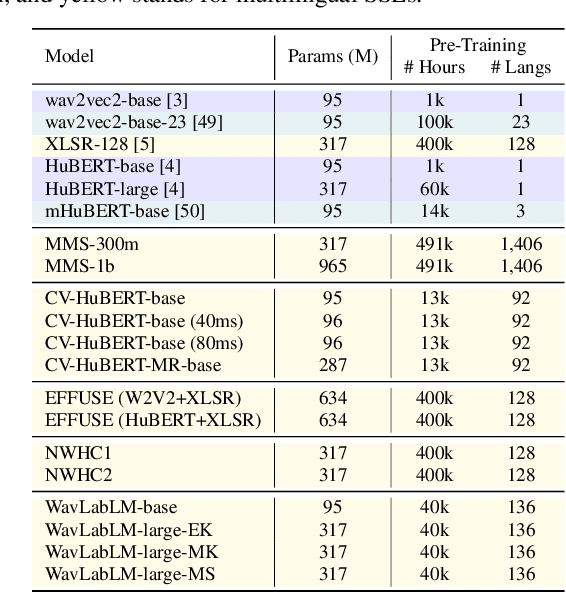
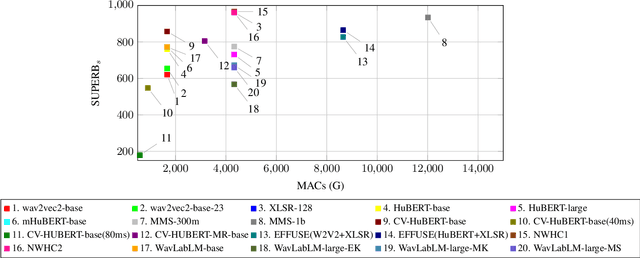
The 2023 Multilingual Speech Universal Performance Benchmark (ML-SUPERB) Challenge expands upon the acclaimed SUPERB framework, emphasizing self-supervised models in multilingual speech recognition and language identification. The challenge comprises a research track focused on applying ML-SUPERB to specific multilingual subjects, a Challenge Track for model submissions, and a New Language Track where language resource researchers can contribute and evaluate their low-resource language data in the context of the latest progress in multilingual speech recognition. The challenge garnered 12 model submissions and 54 language corpora, resulting in a comprehensive benchmark encompassing 154 languages. The findings indicate that merely scaling models is not the definitive solution for multilingual speech tasks, and a variety of speech/voice types present significant challenges in multilingual speech processing.
Why We Should Report the Details in Subjective Evaluation of TTS More Rigorously
Jun 03, 2023This paper emphasizes the importance of reporting experiment details in subjective evaluations and demonstrates how such details can significantly impact evaluation results in the field of speech synthesis. Through an analysis of 80 papers presented at INTERSPEECH 2022, we find a lack of thorough reporting on critical details such as evaluator recruitment and filtering, instructions and payments, and the geographic and linguistic backgrounds of evaluators. To illustrate the effect of these details on evaluation outcomes, we conducted mean opinion score (MOS) tests on three well-known TTS systems under different evaluation settings and we obtain at least three distinct rankings of TTS models. We urge the community to report experiment details in subjective evaluations to improve the reliability and interpretability of experimental results.