 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of LLMs in Speech is Often Flawed: Test Set Contamination in Large Language Models for Speech Recognition
May 28, 2025Recent work suggests that large language models (LLMs) can improve performance of speech tasks compared to existing systems. To support their claims, results on LibriSpeech and Common Voice are often quoted. However, this work finds that a substantial amount of the LibriSpeech and Common Voice evaluation sets appear in public LLM pretraining corpora. This calls into question the reliability of findings drawn from these two datasets. To measure the impact of contamination, LLMs trained with or without contamination are compared, showing that a contaminated LLM is more likely to generate test sentences it has seen during training. Speech recognisers using contaminated LLMs shows only subtle differences in error rates, but assigns significantly higher probabilities to transcriptions seen during training. Results show that LLM outputs can be biased by tiny amounts of data contamination, highlighting the importance of evaluating LLM-based speech systems with held-out data.
Loquacious Set: 25,000 Hours of Transcribed and Diverse English Speech Recognition Data for Research and Commercial Use
May 27, 2025
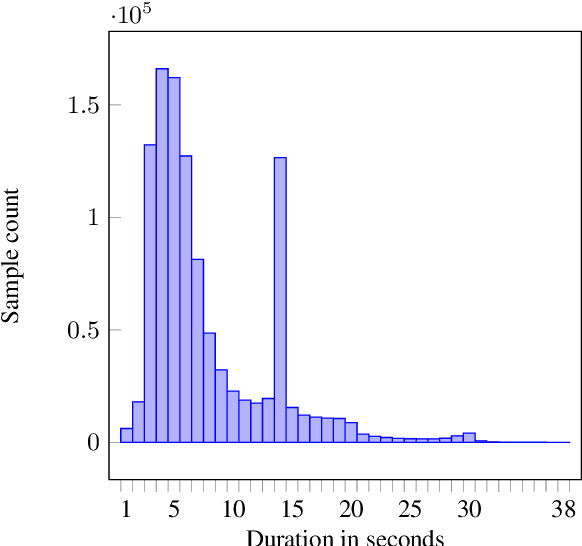
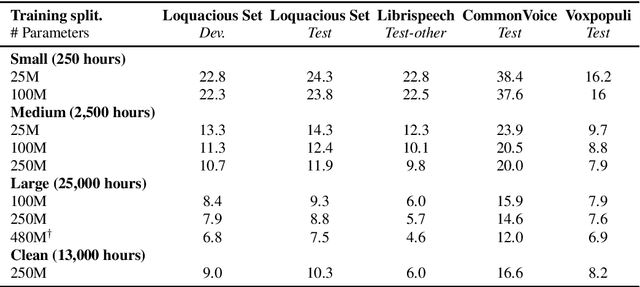
Automatic speech recognition (ASR) research is driven by the availability of common datasets between industrial researchers and academics, encouraging comparisons and evaluations. LibriSpeech, despite its long success as an ASR benchmark, is now limited by its size and focus on clean, read speech, leading to near-zero word error rates. More recent datasets, including MOSEL, YODAS, Gigaspeech, OWSM, Libriheavy or People's Speech suffer from major limitations including licenses that researchers in the industry cannot use, unreliable transcriptions, incorrect audio data, or the lack of evaluation sets. This work presents the Loquacious Set, a 25,000-hour curated collection of commercially usable English speech. Featuring hundreds of thousands of speakers with diverse accents and a wide range of speech types (read, spontaneous, talks, clean, noisy), the Loquacious Set is designed to work for academics and researchers in the industry to build ASR systems in real-world scenarios.
CodecFake-Omni: A Large-Scale Codec-based Deepfake Speech Dataset
Jan 14, 2025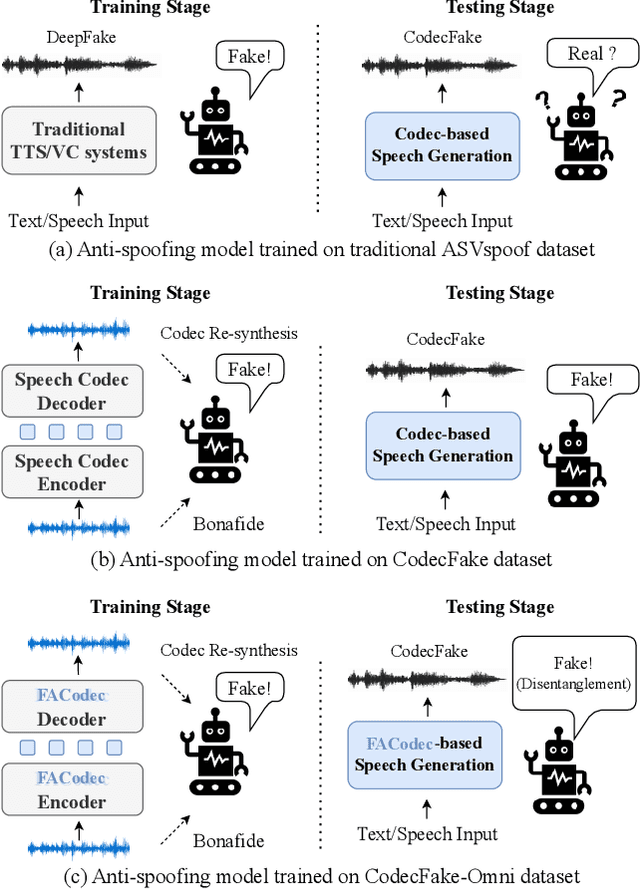
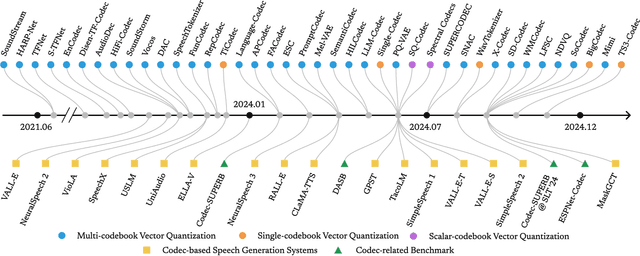

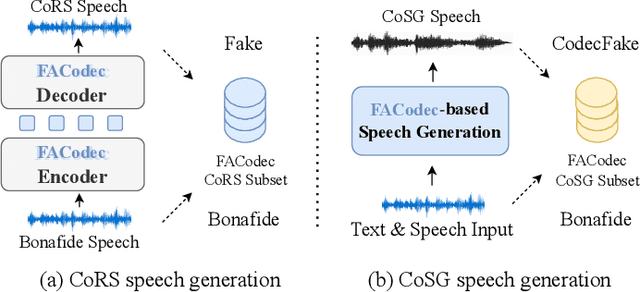
With the rapid advancement of codec-based speech generation (CoSG) systems, creating fake speech that mimics an individual's identity and spreads misinformation has become remarkably easy. Addressing the risks posed by such deepfake speech has attracted significant attention. However, most existing studies focus on detecting fake data generated by traditional speech generation models. Research on detecting fake speech generated by CoSG systems remains limited and largely unexplored. In this paper, we introduce CodecFake-Omni, a large-scale dataset specifically designed to advance the study of neural codec-based deepfake speech (CodecFake) detection and promote progress within the anti-spoofing community. To the best of our knowledge, CodecFake-Omni is the largest dataset of its kind till writing this paper, encompassing the most diverse range of codec architectures. The training set is generated through re-synthesis using nearly all publicly available open-source 31 neural audio codec models across 21 different codec families (one codec family with different configurations will result in multiple different codec models). The evaluation set includes web-sourced data collected from websites generated by 17 advanced CoSG models with eight codec families. Using this large-scale dataset, we reaffirm our previous findings that anti-spoofing models trained on traditional spoofing datasets generated by vocoders struggle to detect synthesized speech from current CoSG systems. Additionally, we propose a comprehensive neural audio codec taxonomy, categorizing neural audio codecs by their root components: vector quantizer, auxiliary objectives, and decoder types, with detailed explanations and representative examples for each. Using this comprehensive taxonomy, we conduct stratified analysis to provide valuable insights for future CodecFake detection research.
CodecFake: Enhancing Anti-Spoofing Models Against Deepfake Audios from Codec-Based Speech Synthesis Systems
Jun 11, 2024



Current state-of-the-art (SOTA) codec-based audio synthesis systems can mimic anyone's voice with just a 3-second sample from that specific unseen speaker. Unfortunately, malicious attackers may exploit these technologies, causing misuse and security issues. Anti-spoofing models have been developed to detect fake speech. However, the open question of whether current SOTA anti-spoofing models can effectively counter deepfake audios from codec-based speech synthesis systems remains unanswered. In this paper, we curate an extensive collection of contemporary SOTA codec models, employing them to re-create synthesized speech. This endeavor leads to the creation of CodecFake, the first codec-based deepfake audio dataset. Additionally, we verify that anti-spoofing models trained on commonly used datasets cannot detect synthesized speech from current codec-based speech generation systems. The proposed CodecFake dataset empowers these models to counter this challenge effectively.
REBORN: Reinforcement-Learned Boundary Segmentation with Iterative Training for Unsupervised ASR
Feb 06, 2024Unsupervised automatic speech recognition (ASR) aims to learn the mapping between the speech signal and its corresponding textual transcription without the supervision of paired speech-text data. A word/phoneme in the speech signal is represented by a segment of speech signal with variable length and unknown boundary, and this segmental structure makes learning the mapping between speech and text challenging, especially without paired data. In this paper, we propose REBORN, Reinforcement-Learned Boundary Segmentation with Iterative Training for Unsupervised ASR. REBORN alternates between (1) training a segmentation model that predicts the boundaries of the segmental structures in speech signals and (2) training the phoneme prediction model, whose input is a segmental structure segmented by the segmentation model, to predict a phoneme transcription. Since supervised data for training the segmentation model is not available, we use reinforcement learning to train the segmentation model to favor segmentations that yield phoneme sequence predictions with a lower perplexity. We conduct extensive experiments and find that under the same setting, REBORN outperforms all prior unsupervised ASR models on LibriSpeech, TIMIT, and five non-English languages in Multilingual LibriSpeech. We comprehensively analyze why the boundaries learned by REBORN improve the unsupervised ASR performance.
AV-SUPERB: A Multi-Task Evaluation Benchmark for Audio-Visual Representation Models
Sep 19, 2023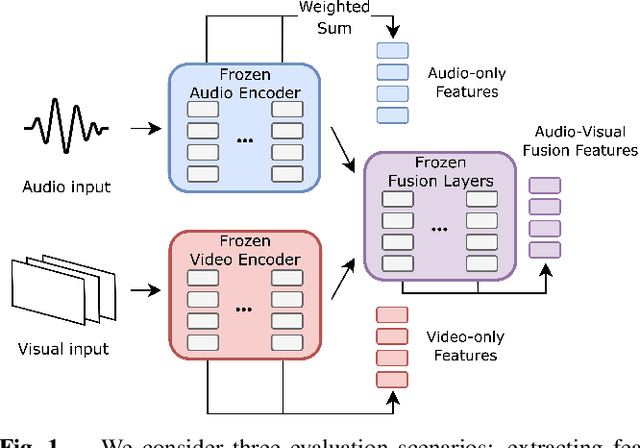
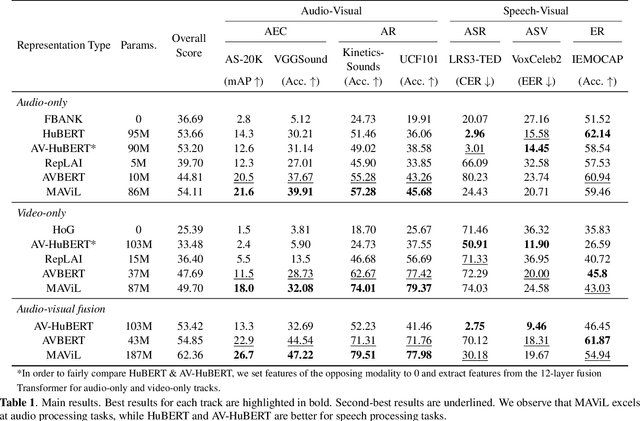
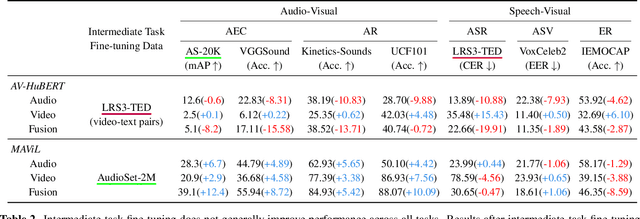
Audio-visual representation learning aims to develop systems with human-like perception by utilizing correlation between auditory and visual information. However, current models often focus on a limited set of tasks, and generalization abilities of learned representations are unclear. To this end, we propose the AV-SUPERB benchmark that enables general-purpose evaluation of unimodal audio/visual and bimodal fusion representations on 7 datasets covering 5 audio-visual tasks in speech and audio processing. We evaluate 5 recent self-supervised models and show that none of these models generalize to all tasks, emphasizing the need for future study on improving universal model performance. In addition, we show that representations may be improved with intermediate-task fine-tuning and audio event classification with AudioSet serves as a strong intermediate task. We release our benchmark with evaluation code and a model submission platform to encourage further research in audio-visual learning.
Cascading and Direct Approaches to Unsupervised Constituency Parsing on Spoken Sentences
Mar 15, 2023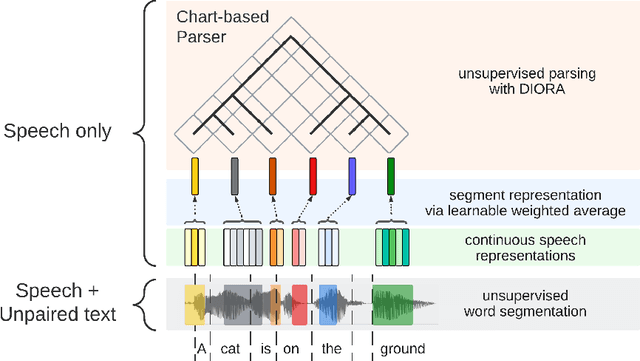
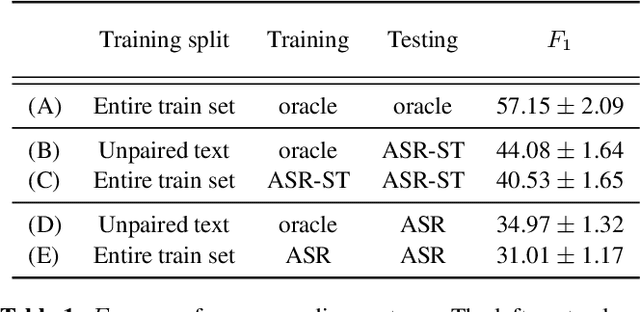
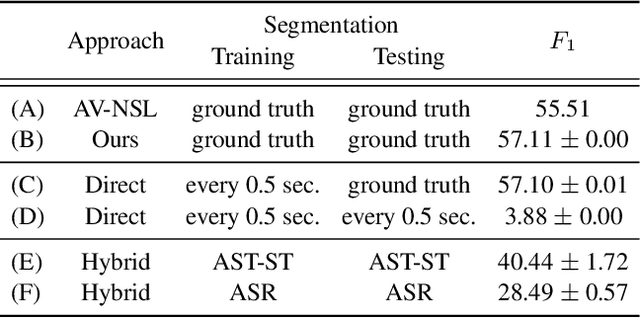
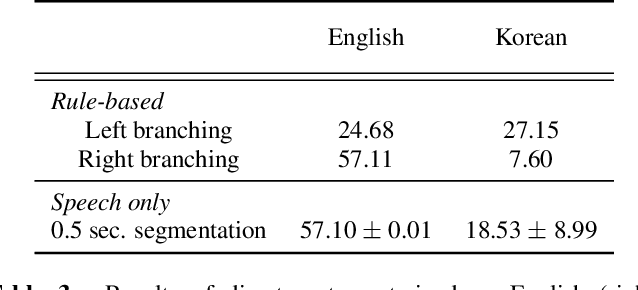
Past work on unsupervised parsing is constrained to written form. In this paper, we present the first study on unsupervised spoken constituency parsing given unlabeled spoken sentences and unpaired textual data. The goal is to determine the spoken sentences' hierarchical syntactic structure in the form of constituency parse trees, such that each node is a span of audio that corresponds to a constituent. We compare two approaches: (1) cascading an unsupervised automatic speech recognition (ASR) model and an unsupervised parser to obtain parse trees on ASR transcripts, and (2) direct training an unsupervised parser on continuous word-level speech representations. This is done by first splitting utterances into sequences of word-level segments, and aggregating self-supervised speech representations within segments to obtain segment embeddings. We find that separately training a parser on the unpaired text and directly applying it on ASR transcripts for inference produces better results for unsupervised parsing. Additionally, our results suggest that accurate segmentation alone may be sufficient to parse spoken sentences accurately. Finally, we show the direct approach may learn head-directionality correctly for both head-initial and head-final languages without any explicit inductive bias.
On the Utility of Self-supervised Models for Prosody-related Tasks
Oct 13, 2022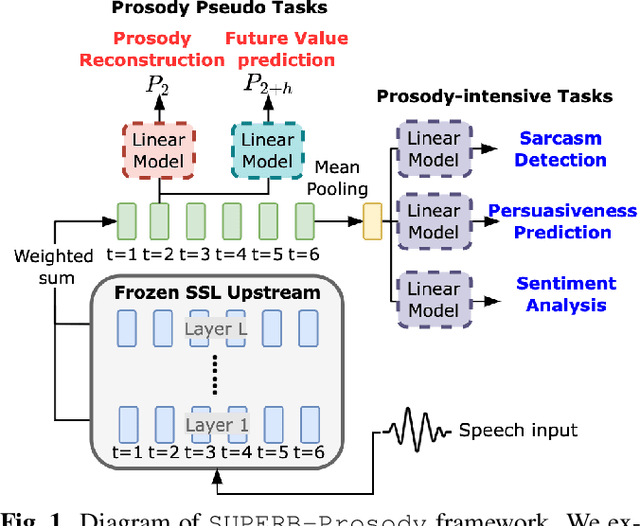
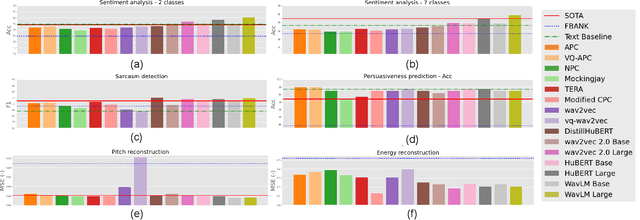
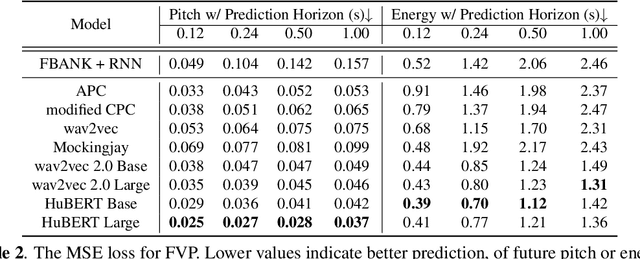
Self-Supervised Learning (SSL) from speech data has produced models that have achieved remarkable performance in many tasks, and that are known to implicitly represent many aspects of information latently present in speech signals. However, relatively little is known about the suitability of such models for prosody-related tasks or the extent to which they encode prosodic information. We present a new evaluation framework, SUPERB-prosody, consisting of three prosody-related downstream tasks and two pseudo tasks. We find that 13 of the 15 SSL models outperformed the baseline on all the prosody-related tasks. We also show good performance on two pseudo tasks: prosody reconstruction and future prosody prediction. We further analyze the layerwise contributions of the SSL models. Overall we conclude that SSL speech models are highly effective for prosody-related tasks.