 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Unsupervised Adaptation of a Speech Recogniser Using Entropy Minimisation and Speaker Codes
Jun 12, 2025Speech recognisers usually perform optimally only in a specific environment and need to be adapted to work well in another. For adaptation to a new speaker, there is often too little data for fine-tuning to be robust, and that data is usually unlabelled. This paper proposes a combination of approaches to make adaptation to a single minute of data robust. First, instead of estimating the adaptation parameters with cross-entropy on a single error-prone hypothesis or "pseudo-label", this paper proposes a novel loss function, the conditional entropy over complete hypotheses. Using multiple hypotheses makes adaptation more robust to errors in the initial recognition. Second, a "speaker code" characterises a speaker in a vector short enough that it requires little data to estimate. On a far-field noise-augmented version of Common Voice, the proposed scheme yields a 20% relative improvement in word error rate on one minute of adaptation data, increasing on 10 minutes to 29%.
Evaluation of LLMs in Speech is Often Flawed: Test Set Contamination in Large Language Models for Speech Recognition
May 28, 2025Recent work suggests that large language models (LLMs) can improve performance of speech tasks compared to existing systems. To support their claims, results on LibriSpeech and Common Voice are often quoted. However, this work finds that a substantial amount of the LibriSpeech and Common Voice evaluation sets appear in public LLM pretraining corpora. This calls into question the reliability of findings drawn from these two datasets. To measure the impact of contamination, LLMs trained with or without contamination are compared, showing that a contaminated LLM is more likely to generate test sentences it has seen during training. Speech recognisers using contaminated LLMs shows only subtle differences in error rates, but assigns significantly higher probabilities to transcriptions seen during training. Results show that LLM outputs can be biased by tiny amounts of data contamination, highlighting the importance of evaluating LLM-based speech systems with held-out data.
Loquacious Set: 25,000 Hours of Transcribed and Diverse English Speech Recognition Data for Research and Commercial Use
May 27, 2025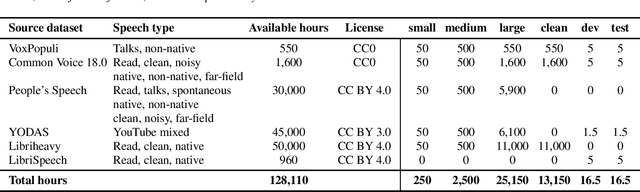
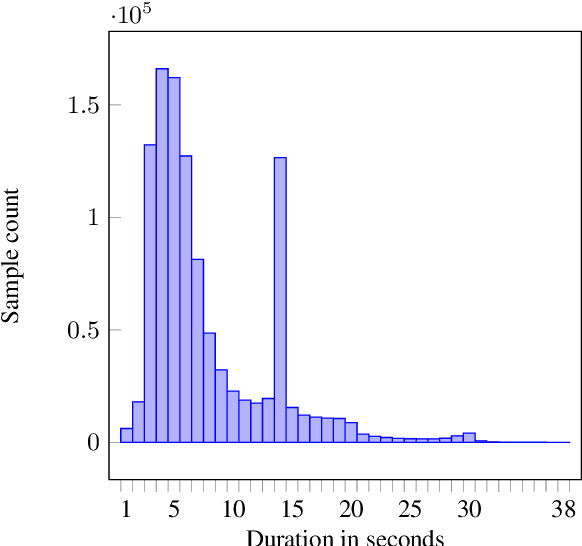
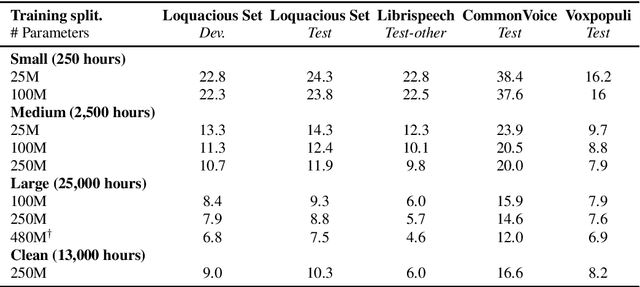
Automatic speech recognition (ASR) research is driven by the availability of common datasets between industrial researchers and academics, encouraging comparisons and evaluations. LibriSpeech, despite its long success as an ASR benchmark, is now limited by its size and focus on clean, read speech, leading to near-zero word error rates. More recent datasets, including MOSEL, YODAS, Gigaspeech, OWSM, Libriheavy or People's Speech suffer from major limitations including licenses that researchers in the industry cannot use, unreliable transcriptions, incorrect audio data, or the lack of evaluation sets. This work presents the Loquacious Set, a 25,000-hour curated collection of commercially usable English speech. Featuring hundreds of thousands of speakers with diverse accents and a wide range of speech types (read, spontaneous, talks, clean, noisy), the Loquacious Set is designed to work for academics and researchers in the industry to build ASR systems in real-world scenarios.
Benchmarking Rotary Position Embeddings for Automatic Speech Recognition
Jan 10, 2025Rotary Position Embedding (RoPE) encodes relative and absolute positional information in Transformer-based models through rotation matrices applied to input vectors within sequences. While RoPE has demonstrated superior performance compared to other positional embedding technologies in natural language processing tasks, its effectiveness in speech processing applications remains understudied. In this work, we conduct a comprehensive evaluation of RoPE across diverse automatic speech recognition (ASR) tasks. Our experimental results demonstrate that for ASR tasks, RoPE consistently achieves lower error rates compared to the currently widely used relative positional embedding. To facilitate further research, we release the implementation and all experimental recipes through the SpeechBrain toolkit.
Linear Time Complexity Conformers with SummaryMixing for Streaming Speech Recognition
Sep 11, 2024


Automatic speech recognition (ASR) with an encoder equipped with self-attention, whether streaming or non-streaming, takes quadratic time in the length of the speech utterance. This slows down training and decoding, increase their cost, and limit the deployment of the ASR in constrained devices. SummaryMixing is a promising linear-time complexity alternative to self-attention for non-streaming speech recognition that, for the first time, preserves or outperforms the accuracy of self-attention models. Unfortunately, the original definition of SummaryMixing is not suited to streaming speech recognition. Hence, this work extends SummaryMixing to a Conformer Transducer that works in both a streaming and an offline mode. It shows that this new linear-time complexity speech encoder outperforms self-attention in both scenarios while requiring less compute and memory during training and decoding.
Linear-Complexity Self-Supervised Learning for Speech Processing
Jul 18, 2024Self-supervised learning (SSL) models usually require weeks of pre-training with dozens of high-end GPUs. These models typically have a multi-headed self-attention (MHSA) context encoder. However, MHSA takes quadratic time and space in the input length, contributing to the high pre-training cost. Linear-complexity alternatives to MHSA have been proposed. For instance, in supervised training, the SummaryMixing model is the first to outperform MHSA across multiple speech processing tasks. However, these cheaper alternatives have not been explored for SSL yet. This paper studies a linear-complexity context encoder for SSL for the first time. With better or equivalent performance for the downstream tasks of the MP3S benchmark, SummaryMixing reduces the pre-training time and peak VRAM of wav2vec 2.0 model by 18% and by 23%, respectively, leading to the pre-training of a 155M wav2vec 2.0 model finished within one week with 4 Tesla A100 GPUs. Code is available at https://github.com/SamsungLabs/SummaryMixing.
Open-Source Conversational AI with SpeechBrain 1.0
Jul 02, 2024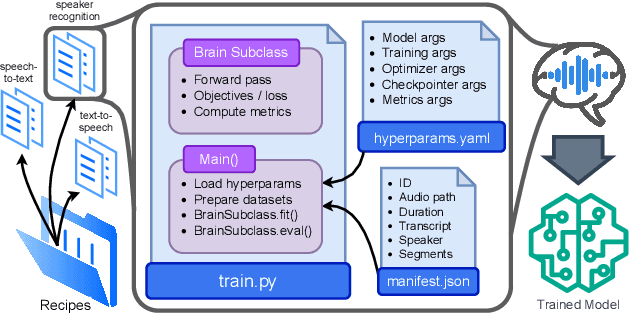

SpeechBrain is an open-source Conversational AI toolkit based on PyTorch, focused particularly on speech processing tasks such as speech recognition, speech enhancement, speaker recognition, text-to-speech, and much more. It promotes transparency and replicability by releasing both the pre-trained models and the complete "recipes" of code and algorithms required for training them. This paper presents SpeechBrain 1.0, a significant milestone in the evolution of the toolkit, which now has over 200 recipes for speech, audio, and language processing tasks, and more than 100 models available on Hugging Face. SpeechBrain 1.0 introduces new technologies to support diverse learning modalities, Large Language Model (LLM) integration, and advanced decoding strategies, along with novel models, tasks, and modalities. It also includes a new benchmark repository, offering researchers a unified platform for evaluating models across diverse tasks
CARE: Large Precision Matrix Estimation for Compositional Data
Sep 13, 2023High-dimensional compositional data are prevalent in many applications. The simplex constraint poses intrinsic challenges to inferring the conditional dependence relationships among the components forming a composition, as encoded by a large precision matrix. We introduce a precise specification of the compositional precision matrix and relate it to its basis counterpart, which is shown to be asymptotically identifiable under suitable sparsity assumptions. By exploiting this connection, we propose a composition adaptive regularized estimation (CARE) method for estimating the sparse basis precision matrix. We derive rates of convergence for the estimator and provide theoretical guarantees on support recovery and data-driven parameter tuning. Our theory reveals an intriguing trade-off between identification and estimation, thereby highlighting the blessing of dimensionality in compositional data analysis. In particular, in sufficiently high dimensions, the CARE estimator achieves minimax optimality and performs as well as if the basis were observed. We further discuss how our framework can be extended to handle data containing zeros, including sampling zeros and structural zeros. The advantages of CARE over existing methods are illustrated by simulation studies and an application to inferring microbial ecological networks in the human gut.
LeBenchmark 2.0: a Standardized, Replicable and Enhanced Framework for Self-supervised Representations of French Speech
Sep 11, 2023Self-supervised learning (SSL) is at the origin of unprecedented improvements in many different domains including computer vision and natural language processing. Speech processing drastically benefitted from SSL as most of the current domain-related tasks are now being approached with pre-trained models. This work introduces LeBenchmark 2.0 an open-source framework for assessing and building SSL-equipped French speech technologies. It includes documented, large-scale and heterogeneous corpora with up to 14,000 hours of heterogeneous speech, ten pre-trained SSL wav2vec 2.0 models containing from 26 million to one billion learnable parameters shared with the community, and an evaluation protocol made of six downstream tasks to complement existing benchmarks. LeBenchmark 2.0 also presents unique perspectives on pre-trained SSL models for speech with the investigation of frozen versus fine-tuned downstream models, task-agnostic versus task-specific pre-trained models as well as a discussion on the carbon footprint of large-scale model training.
Sumformer: A Linear-Complexity Alternative to Self-Attention for Speech Recognition
Jul 12, 2023Modern speech recognition systems rely on self-attention. Unfortunately, token mixing with self-attention takes quadratic time in the length of the speech utterance, slowing down inference as well as training and increasing memory consumption. Cheaper alternatives to self-attention for ASR have been developed, but fail to consistently reach the same level of accuracy. In practice, however, the self-attention weights of trained speech recognizers take the form of a global average over time. This paper, therefore, proposes a linear-time alternative to self-attention for speech recognition. It summarises a whole utterance with the mean over vectors for all time steps. This single summary is then combined with time-specific information. We call this method ``Summary Mixing''. Introducing Summary Mixing in state-of-the-art ASR models makes it feasible to preserve or exceed previous speech recognition performance while lowering the training and inference times by up to 27% and reducing the memory budget by a factor of two.