 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Ultra-Low Latency, End-to-End Streaming Speech Synthesis Architecture via Block-Wise Generation and Depth-Wise Codec Decoding
Apr 14, 2026Real-time speech synthesis requires balancing inference latency and acoustic fidelity for interactive applications. Conventional continuous text-to-speech pipelines require computationally intensive neural vocoders to reconstruct phase information, creating a significant streaming bottleneck. Furthermore, regression-based acoustic modeling frequently induces spectral over-smoothing artifacts. To address these limitations, this paper proposes a novel end-to-end non-autoregressive architecture optimized for ultra-low latency block-wise generation, directly modeling the highly compressed discrete latent space of the Mimi neural audio codec. Integrating a modified FastSpeech 2 backbone with a progressive depth-wise sequential decoding strategy, the architecture dynamically conditions 32 layers of residual vector quantization codes. This mechanism resolves phonetic alignment degradation and manages the complexity of high-fidelity discrete representations without temporal autoregressive overhead. Experimental evaluations on English and Malay datasets validate its language-independent deployment capability. Compared to conventional continuous regression models, the proposed architecture demonstrates quantitative improvements in fundamental voicing accuracy and mitigates high-frequency spectral degradation. It achieves ultra-low latency inference, translating to a 10.6-fold absolute acceleration over conventional cascaded pipelines. Crucially, the system achieves an average time-to-first-byte latency of 48.99 milliseconds, falling significantly below the human perception threshold for real-time interactive streaming. These results firmly establish the proposed architecture as a highly optimized solution for deploying real-time streaming speech interfaces.
Ara-Best-RQ: Multi Dialectal Arabic SSL
Mar 23, 2026We present Ara-BEST-RQ, a family of self-supervised learning (SSL) models specifically designed for multi-dialectal Arabic speech processing. Leveraging 5,640 hours of crawled Creative Commons speech and combining it with publicly available datasets, we pre-train conformer-based BEST-RQ models up to 600M parameters. Our models are evaluated on dialect identification (DID) and automatic speech recognition (ASR) tasks, achieving state-of-the-art performance on the former while using fewer parameters than competing models. We demonstrate that family-targeted pre-training on Arabic dialects significantly improves downstream performance compared to multilingual or monolingual models trained on non-Arabic data. All models, code, and pre-processed datasets will be publicly released to support reproducibility and further research in Arabic speech technologies.
SLURP-TN : Resource for Tunisian Dialect Spoken Language Understanding
Mar 23, 2026Spoken Language Understanding (SLU) aims to extract the semantic information from the speech utterance of user queries. It is a core component in a task-oriented dialogue system. With the spectacular progress of deep neural network models and the evolution of pre-trained language models, SLU has obtained significant breakthroughs. However, only a few high-resource languages have taken advantage of this progress due to the absence of SLU resources. In this paper, we seek to mitigate this obstacle by introducing SLURP-TN. This dataset was created by recording 55 native speakers uttering sentences in Tunisian dialect, manually translated from six SLURP domains. The result is an SLU Tunisian dialect dataset that comprises 4165 sentences recorded into around 5 hours of acoustic material. We also develop a number of Automatic Speech Recognition and SLU models exploiting SLUTP-TN. The Dataset and baseline models are available at: https://huggingface.co/datasets/Elyadata/SLURP-TN.
Learning Multiple Utterance-Level Attribute Representations with a Unified Speech Encoder
Mar 09, 2026Speech foundation models trained with self-supervised learning produce generic speech representations that support a wide range of speech processing tasks. When further adapted with supervised learning, these models can achieve strong performance on specific downstream tasks. Recent post-training approaches, such as SAMU-XSLR and SONAR, align speech representations with utterance-level semantic representations, enabling effective multimodal (speech-text) and multilingual applications. While speech foundation models typically learn contextual embeddings at the acoustic frame level, these methods learn representations at the utterance level. In this work, we extend this paradigm to arbitrary utterance-level attributes and propose a unified post-training framework that enables a single speech foundation model to generate multiple types of utterance-level representations. We demonstrate the effectiveness of this approach by jointly learning semantic and speaker representations and evaluating them on multilingual speech retrieval and speaker recognition tasks.
Using Multimodal and Language-Agnostic Sentence Embeddings for Abstractive Summarization
Mar 09, 2026Abstractive summarization aims to generate concise summaries by creating new sentences, allowing for flexible rephrasing. However, this approach can be vulnerable to inaccuracies, particularly `hallucinations' where the model introduces non-existent information. In this paper, we leverage the use of multimodal and multilingual sentence embeddings derived from pretrained models such as LaBSE, SONAR, and BGE-M3, and feed them into a modified BART-based French model. A Named Entity Injection mechanism that appends tokenized named entities to the decoder input is introduced, in order to improve the factual consistency of the generated summary. Our novel framework, SBARThez, is applicable to both text and speech inputs and supports cross-lingual summarization; it shows competitive performance relative to token-level baselines, especially for low-resource languages, while generating more concise and abstract summaries.
Pantagruel: Unified Self-Supervised Encoders for French Text and Speech
Jan 09, 2026We release Pantagruel models, a new family of self-supervised encoder models for French text and speech. Instead of predicting modality-tailored targets such as textual tokens or speech units, Pantagruel learns contextualized target representations in the feature space, allowing modality-specific encoders to capture linguistic and acoustic regularities more effectively. Separate models are pre-trained on large-scale French corpora, including Wikipedia, OSCAR and CroissantLLM for text, together with MultilingualLibriSpeech, LeBenchmark, and INA-100k for speech. INA-100k is a newly introduced 100,000-hour corpus of French audio derived from the archives of the Institut National de l'Audiovisuel (INA), the national repository of French radio and television broadcasts, providing highly diverse audio data. We evaluate Pantagruel across a broad range of downstream tasks spanning both modalities, including those from the standard French benchmarks such as FLUE or LeBenchmark. Across these tasks, Pantagruel models show competitive or superior performance compared to strong French baselines such as CamemBERT, FlauBERT, and LeBenchmark2.0, while maintaining a shared architecture that can seamlessly handle either speech or text inputs. These results confirm the effectiveness of feature-space self-supervised objectives for French representation learning and highlight Pantagruel as a robust foundation for multimodal speech-text understanding.
ADI-20: Arabic Dialect Identification dataset and models
Nov 13, 2025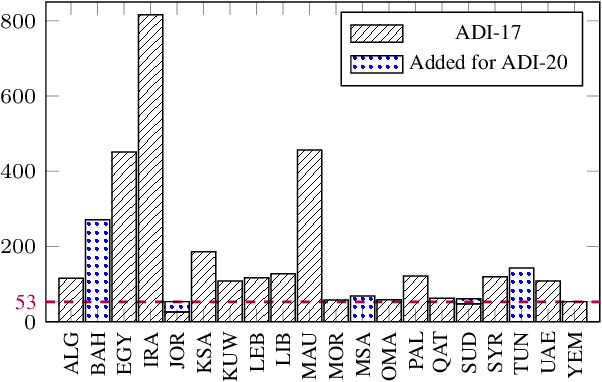
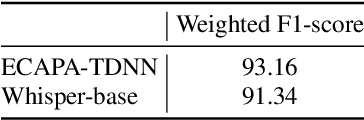
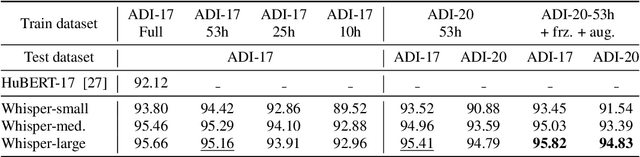
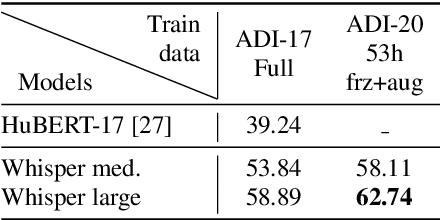
We present ADI-20, an extension of the previously published ADI-17 Arabic Dialect Identification (ADI) dataset. ADI-20 covers all Arabic-speaking countries' dialects. It comprises 3,556 hours from 19 Arabic dialects in addition to Modern Standard Arabic (MSA). We used this dataset to train and evaluate various state-of-the-art ADI systems. We explored fine-tuning pre-trained ECAPA-TDNN-based models, as well as Whisper encoder blocks coupled with an attention pooling layer and a classification dense layer. We investigated the effect of (i) training data size and (ii) the model's number of parameters on identification performance. Our results show a small decrease in F1 score while using only 30% of the original training data. We open-source our collected data and trained models to enable the reproduction of our work, as well as support further research in ADI.
TEDxTN: A Three-way Speech Translation Corpus for Code-Switched Tunisian Arabic - English
Nov 13, 2025In this paper, we introduce TEDxTN, the first publicly available Tunisian Arabic to English speech translation dataset. This work is in line with the ongoing effort to mitigate the data scarcity obstacle for a number of Arabic dialects. We collected, segmented, transcribed and translated 108 TEDx talks following our internally developed annotations guidelines. The collected talks represent 25 hours of speech with code-switching that cover speakers with various accents from over 11 different regions of Tunisia. We make the annotation guidelines and corpus publicly available. This will enable the extension of TEDxTN to new talks as they become available. We also report results for strong baseline systems of Speech Recognition and Speech Translation using multiple pre-trained and fine-tuned end-to-end models. This corpus is the first open source and publicly available speech translation corpus of Code-Switching Tunisian dialect. We believe that this is a valuable resource that can motivate and facilitate further research on the natural language processing of Tunisian Dialect.
ELYADATA & LIA at NADI 2025: ASR and ADI Subtasks
Nov 13, 2025This paper describes Elyadata \& LIA's joint submission to the NADI multi-dialectal Arabic Speech Processing 2025. We participated in the Spoken Arabic Dialect Identification (ADI) and multi-dialectal Arabic ASR subtasks. Our submission ranked first for the ADI subtask and second for the multi-dialectal Arabic ASR subtask among all participants. Our ADI system is a fine-tuned Whisper-large-v3 encoder with data augmentation. This system obtained the highest ADI accuracy score of \textbf{79.83\%} on the official test set. For multi-dialectal Arabic ASR, we fine-tuned SeamlessM4T-v2 Large (Egyptian variant) separately for each of the eight considered dialects. Overall, we obtained an average WER and CER of \textbf{38.54\%} and \textbf{14.53\%}, respectively, on the test set. Our results demonstrate the effectiveness of large pre-trained speech models with targeted fine-tuning for Arabic speech processing.
Towards a Unified Benchmark for Arabic Pronunciation Assessment: Quranic Recitation as Case Study
Jun 09, 2025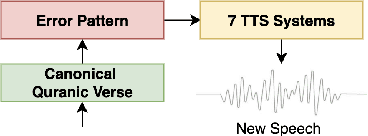
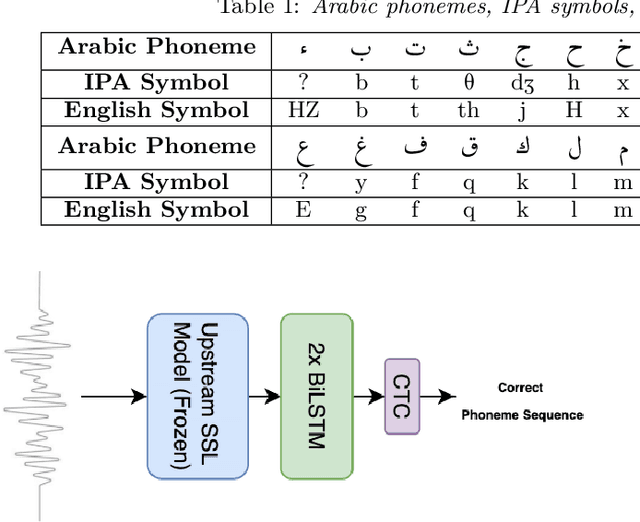
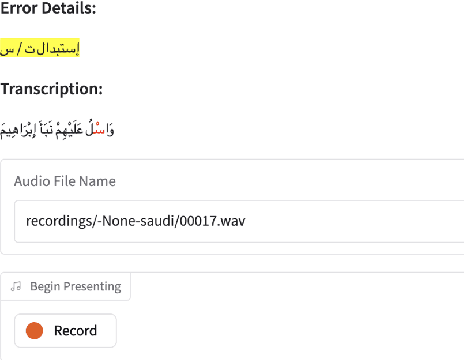

We present a unified benchmark for mispronunciation detection in Modern Standard Arabic (MSA) using Qur'anic recitation as a case study. Our approach lays the groundwork for advancing Arabic pronunciation assessment by providing a comprehensive pipeline that spans data processing, the development of a specialized phoneme set tailored to the nuances of MSA pronunciation, and the creation of the first publicly available test set for this task, which we term as the Qur'anic Mispronunciation Benchmark (QuranMB.v1). Furthermore, we evaluate several baseline models to provide initial performance insights, thereby highlighting both the promise and the challenges inherent in assessing MSA pronunciation. By establishing this standardized framework, we aim to foster further research and development in pronunciation assessment in Arabic language technology and related applications.