 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFKI-Speech System for WildSpoof Challenge: A robust framework for SASV In-the-Wild
Feb 02, 2026This paper presents the DFKI-Speech system developed for the WildSpoof Challenge under the Spoofing aware Automatic Speaker Verification (SASV) track. We propose a robust SASV framework in which a spoofing detector and a speaker verification (SV) network operate in tandem. The spoofing detector employs a self-supervised speech embedding extractor as the frontend, combined with a state-of-the-art graph neural network backend. In addition, a top-3 layer based mixture-of-experts (MoE) is used to fuse high-level and low-level features for effective spoofed utterance detection. For speaker verification, we adapt a low-complexity convolutional neural network that fuses 2D and 1D features at multiple scales, trained with the SphereFace loss. Additionally, contrastive circle loss is applied to adaptively weight positive and negative pairs within each training batch, enabling the network to better distinguish between hard and easy sample pairs. Finally, fixed imposter cohort based AS Norm score normalization and model ensembling are used to further enhance the discriminative capability of the speaker verification system.
Two Views, One Truth: Spectral and Self-Supervised Features Fusion for Robust Speech Deepfake Detection
Jul 27, 2025Recent advances in synthetic speech have made audio deepfakes increasingly realistic, posing significant security risks. Existing detection methods that rely on a single modality, either raw waveform embeddings or spectral based features, are vulnerable to non spoof disturbances and often overfit to known forgery algorithms, resulting in poor generalization to unseen attacks. To address these shortcomings, we investigate hybrid fusion frameworks that integrate self supervised learning (SSL) based representations with handcrafted spectral descriptors (MFCC , LFCC, CQCC). By aligning and combining complementary information across modalities, these fusion approaches capture subtle artifacts that single feature approaches typically overlook. We explore several fusion strategies, including simple concatenation, cross attention, mutual cross attention, and a learnable gating mechanism, to optimally blend SSL features with fine grained spectral cues. We evaluate our approach on four challenging public benchmarks and report generalization performance. All fusion variants consistently outperform an SSL only baseline, with the cross attention strategy achieving the best generalization with a 38% relative reduction in equal error rate (EER). These results confirm that joint modeling of waveform and spectral views produces robust, domain agnostic representations for audio deepfake detection.
Towards a Unified Benchmark for Arabic Pronunciation Assessment: Quranic Recitation as Case Study
Jun 09, 2025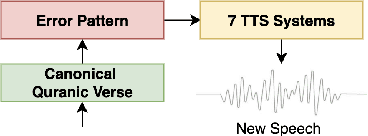
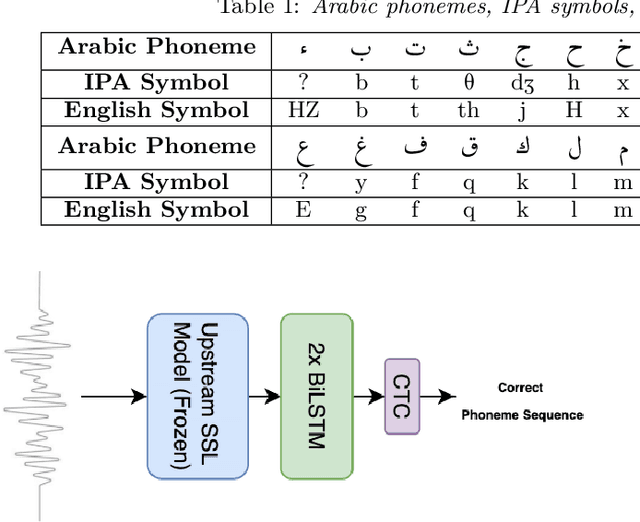

We present a unified benchmark for mispronunciation detection in Modern Standard Arabic (MSA) using Qur'anic recitation as a case study. Our approach lays the groundwork for advancing Arabic pronunciation assessment by providing a comprehensive pipeline that spans data processing, the development of a specialized phoneme set tailored to the nuances of MSA pronunciation, and the creation of the first publicly available test set for this task, which we term as the Qur'anic Mispronunciation Benchmark (QuranMB.v1). Furthermore, we evaluate several baseline models to provide initial performance insights, thereby highlighting both the promise and the challenges inherent in assessing MSA pronunciation. By establishing this standardized framework, we aim to foster further research and development in pronunciation assessment in Arabic language technology and related applications.
BiCrossMamba-ST: Speech Deepfake Detection with Bidirectional Mamba Spectro-Temporal Cross-Attention
May 20, 2025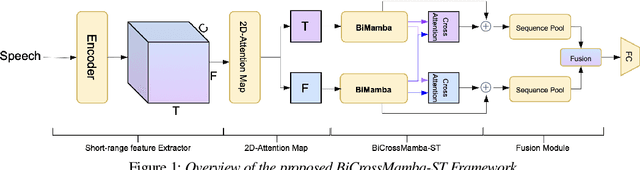
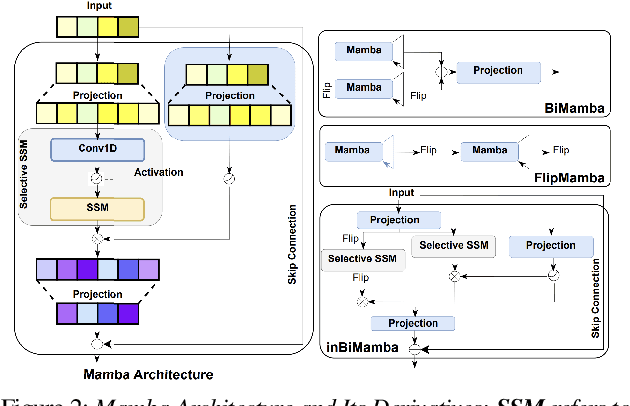
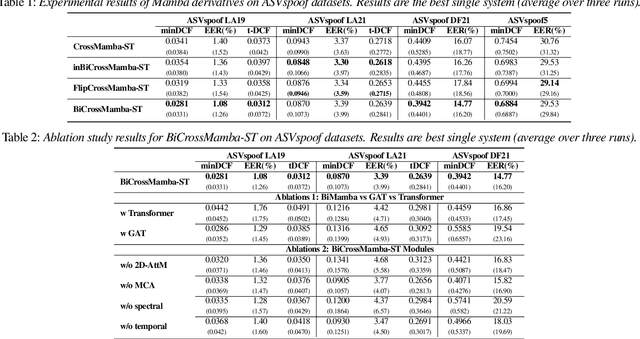
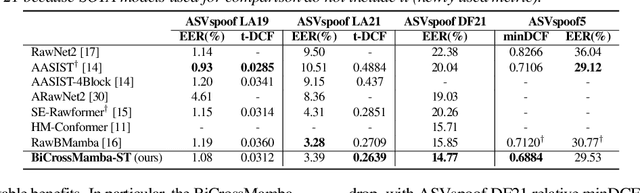
We propose BiCrossMamba-ST, a robust framework for speech deepfake detection that leverages a dual-branch spectro-temporal architecture powered by bidirectional Mamba blocks and mutual cross-attention. By processing spectral sub-bands and temporal intervals separately and then integrating their representations, BiCrossMamba-ST effectively captures the subtle cues of synthetic speech. In addition, our proposed framework leverages a convolution-based 2D attention map to focus on specific spectro-temporal regions, enabling robust deepfake detection. Operating directly on raw features, BiCrossMamba-ST achieves significant performance improvements, a 67.74% and 26.3% relative gain over state-of-the-art AASIST on ASVSpoof LA21 and ASVSpoof DF21 benchmarks, respectively, and a 6.80% improvement over RawBMamba on ASVSpoof DF21. Code and models will be made publicly available.
Comprehensive Layer-wise Analysis of SSL Models for Audio Deepfake Detection
Feb 05, 2025



This paper conducts a comprehensive layer-wise analysis of self-supervised learning (SSL) models for audio deepfake detection across diverse contexts, including multilingual datasets (English, Chinese, Spanish), partial, song, and scene-based deepfake scenarios. By systematically evaluating the contributions of different transformer layers, we uncover critical insights into model behavior and performance. Our findings reveal that lower layers consistently provide the most discriminative features, while higher layers capture less relevant information. Notably, all models achieve competitive equal error rate (EER) scores even when employing a reduced number of layers. This indicates that we can reduce computational costs and increase the inference speed of detecting deepfakes by utilizing only a few lower layers. This work enhances our understanding of SSL models in deepfake detection, offering valuable insights applicable across varied linguistic and contextual settings. Our trained models and code are publicly available: https://github.com/Yaselley/SSL_Layerwise_Deepfake.
MorphBPE: A Morpho-Aware Tokenizer Bridging Linguistic Complexity for Efficient LLM Training Across Morphologies
Feb 02, 2025Tokenization is fundamental to Natural Language Processing (NLP), directly impacting model efficiency and linguistic fidelity. While Byte Pair Encoding (BPE) is widely used in Large Language Models (LLMs), it often disregards morpheme boundaries, leading to suboptimal segmentation, particularly in morphologically rich languages. We introduce MorphBPE, a morphology-aware extension of BPE that integrates linguistic structure into subword tokenization while preserving statistical efficiency. Additionally, we propose two morphology-based evaluation metrics: (i) Morphological Consistency F1-Score, which quantifies the consistency between morpheme sharing and token sharing, contributing to LLM training convergence, and (ii) Morphological Edit Distance, which measures alignment between morphemes and tokens concerning interpretability. Experiments on English, Russian, Hungarian, and Arabic across 300M and 1B parameter LLMs demonstrate that MorphBPE consistently reduces cross-entropy loss, accelerates convergence, and improves morphological alignment scores. Fully compatible with existing LLM pipelines, MorphBPE requires minimal modifications for integration. The MorphBPE codebase and tokenizer playground will be available at: https://github.com/llm-lab-org/MorphBPE and https://tokenizer.llm-lab.org
CAFE A Novel Code switching Dataset for Algerian Dialect French and English
Nov 20, 2024



The paper introduces and publicly releases (Data download link available after acceptance) CAFE -- the first Code-switching dataset between Algerian dialect, French, and english languages. The CAFE speech data is unique for (a) its spontaneous speaking style in vivo human-human conversation capturing phenomena like code-switching and overlapping speech, (b) addresses distinct linguistic challenges in North African Arabic dialect; (c) the CAFE captures dialectal variations from various parts of Algeria within different sociolinguistic contexts. CAFE data contains approximately 37 hours of speech, with a subset, CAFE-small, of 2 hours and 36 minutes released with manual human annotation including speech segmentation, transcription, explicit annotation of code-switching points, overlapping speech, and other events such as noises, and laughter among others. The rest approximately 34.58 hours contain pseudo label transcriptions. In addition to the data release, the paper also highlighted the challenges of using state-of-the-art Automatic Speech Recognition (ASR) models such as Whisper large-v2,3 and PromptingWhisper to handle such content. Following, we benchmark CAFE data with the aforementioned Whisper models and show how well-designed data processing pipelines and advanced decoding techniques can improve the ASR performance in terms of Mixed Error Rate (MER) of 0.310, Character Error Rate (CER) of 0.329 and Word Error Rate (WER) of 0.538.
Beyond Orthography: Automatic Recovery of Short Vowels and Dialectal Sounds in Arabic
Aug 05, 2024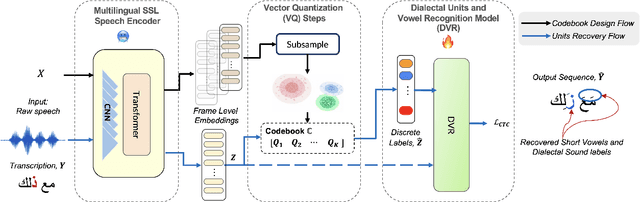

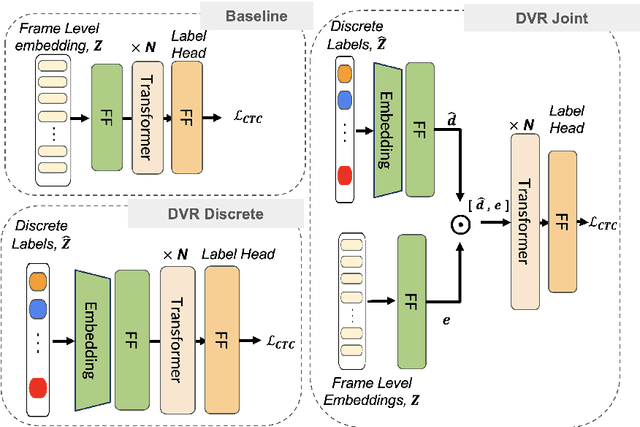

This paper presents a novel Dialectal Sound and Vowelization Recovery framework, designed to recognize borrowed and dialectal sounds within phonologically diverse and dialect-rich languages, that extends beyond its standard orthographic sound sets. The proposed framework utilized a quantized sequence of input with(out) continuous pretrained self-supervised representation. We show the efficacy of the pipeline using limited data for Arabic, a dialect-rich language containing more than 22 major dialects. Phonetically correct transcribed speech resources for dialectal Arabic are scarce. Therefore, we introduce ArabVoice15, a first-of-its-kind, curated test set featuring 5 hours of dialectal speech across 15 Arab countries, with phonetically accurate transcriptions, including borrowed and dialect-specific sounds. We described in detail the annotation guideline along with the analysis of the dialectal confusion pairs. Our extensive evaluation includes both subjective -- human perception tests and objective measures. Our empirical results, reported with three test sets, show that with only one and half hours of training data, our model improve character error rate by ~ 7\% in ArabVoice15 compared to the baseline.
Speech Representation Analysis based on Inter- and Intra-Model Similarities
Jun 23, 2024Self-supervised models have revolutionized speech processing, achieving new levels of performance in a wide variety of tasks with limited resources. However, the inner workings of these models are still opaque. In this paper, we aim to analyze the encoded contextual representation of these foundation models based on their inter- and intra-model similarity, independent of any external annotation and task-specific constraint. We examine different SSL models varying their training paradigm -- Contrastive (Wav2Vec2.0) and Predictive models (HuBERT); and model sizes (base and large). We explore these models on different levels of localization/distributivity of information including (i) individual neurons; (ii) layer representation; (iii) attention weights and (iv) compare the representations with their finetuned counterparts.Our results highlight that these models converge to similar representation subspaces but not to similar neuron-localized concepts\footnote{A concept represents a coherent fragment of knowledge, such as ``a class containing certain objects as elements, where the objects have certain properties. We made the code publicly available for facilitating further research, we publicly released our code.
Automatic Pronunciation Assessment -- A Review
Oct 21, 2023Pronunciation assessment and its application in computer-aided pronunciation training (CAPT) have seen impressive progress in recent years. With the rapid growth in language processing and deep learning over the past few years, there is a need for an updated review. In this paper, we review methods employed in pronunciation assessment for both phonemic and prosodic. We categorize the main challenges observed in prominent research trends, and highlight existing limitations, and available resources. This is followed by a discussion of the remaining challenges and possible directions for future work.