 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehensive Layer-wise Analysis of SSL Models for Audio Deepfake Detection
Feb 05, 2025



This paper conducts a comprehensive layer-wise analysis of self-supervised learning (SSL) models for audio deepfake detection across diverse contexts, including multilingual datasets (English, Chinese, Spanish), partial, song, and scene-based deepfake scenarios. By systematically evaluating the contributions of different transformer layers, we uncover critical insights into model behavior and performance. Our findings reveal that lower layers consistently provide the most discriminative features, while higher layers capture less relevant information. Notably, all models achieve competitive equal error rate (EER) scores even when employing a reduced number of layers. This indicates that we can reduce computational costs and increase the inference speed of detecting deepfakes by utilizing only a few lower layers. This work enhances our understanding of SSL models in deepfake detection, offering valuable insights applicable across varied linguistic and contextual settings. Our trained models and code are publicly available: https://github.com/Yaselley/SSL_Layerwise_Deepfake.
Scalable Prompt Generation for Semi-supervised Learning with Language Models
Feb 18, 2023

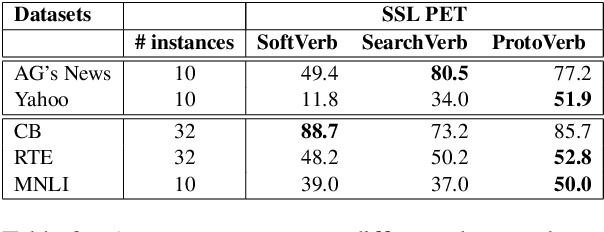

Prompt-based learning methods in semi-supervised learning (SSL) settings have been shown to be effective on multiple natural language understanding (NLU) datasets and tasks in the literature. However, manually designing multiple prompts and verbalizers requires domain knowledge and human effort, making it difficult and expensive to scale across different datasets. In this paper, we propose two methods to automatically design multiple prompts and integrate automatic verbalizer in SSL settings without sacrificing performance. The first method uses various demonstration examples with learnable continuous prompt tokens to create diverse prompt models. The second method uses a varying number of soft prompt tokens to encourage language models to learn different prompts. For the verbalizer, we use the prototypical verbalizer to replace the manual one. In summary, we obtained the best average accuracy of 73.2% (a relative improvement of 2.52% over even the previous state-of-the-art SSL method with manual prompts and verbalizers) in different few-shot learning settings.
C1 at SemEval-2020 Task 9: SentiMix: Sentiment Analysis for Code-Mixed Social Media Text using Feature Engineering
Aug 09, 2020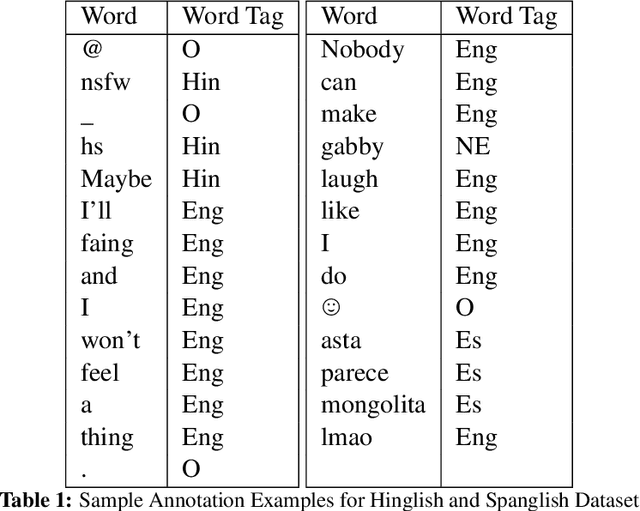
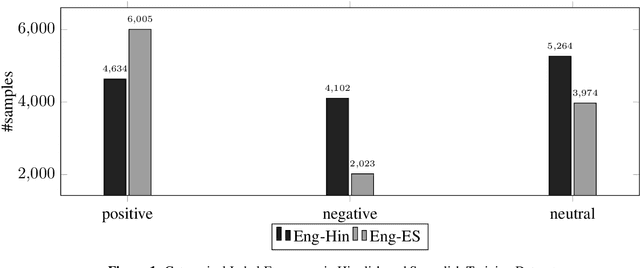
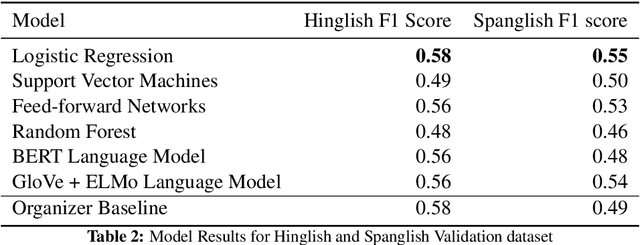

In today's interconnected and multilingual world, code-mixing of languages on social media is a common occurrence. While many Natural Language Processing (NLP) tasks like sentiment analysis are mature and well designed for monolingual text, techniques to apply these tasks to code-mixed text still warrant exploration. This paper describes our feature engineering approach to sentiment analysis in code-mixed social media text for SemEval-2020 Task 9: SentiMix. We tackle this problem by leveraging a set of hand-engineered lexical, sentiment, and metadata features to design a classifier that can disambiguate between "positive", "negative" and "neutral" sentiment. With this model, we are able to obtain a weighted F1 score of 0.65 for the "Hinglish" task and 0.63 for the "Spanglish" tasks
A Multi-task Approach for Named Entity Recognition in Social Media Data
Jun 10, 2019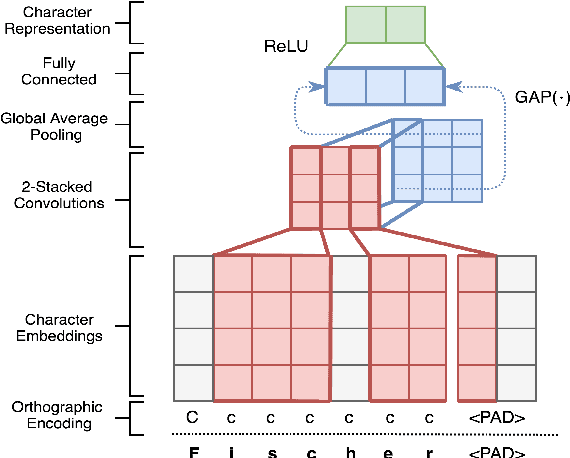
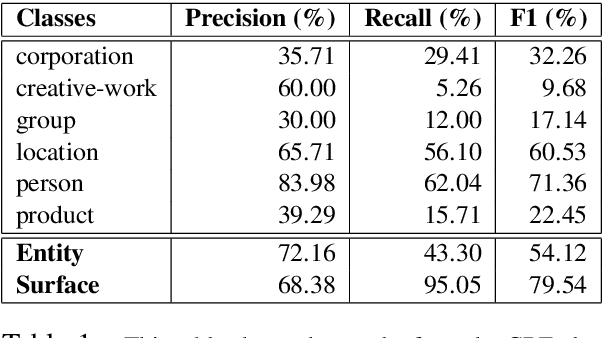
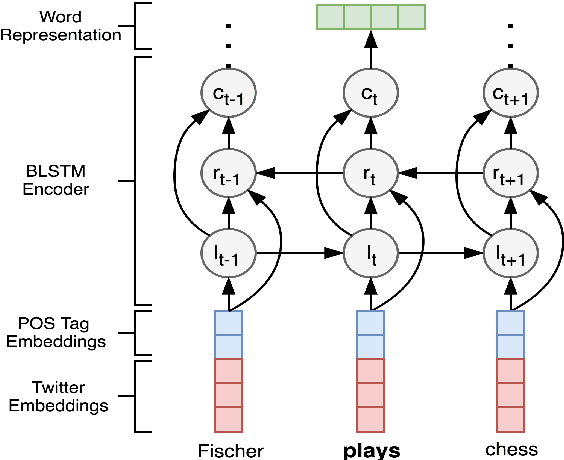
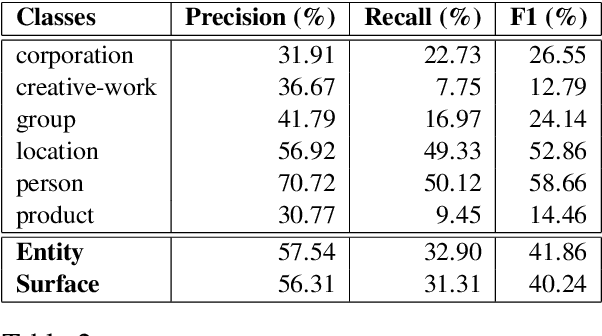
Named Entity Recognition for social media data is challenging because of its inherent noisiness. In addition to improper grammatical structures, it contains spelling inconsistencies and numerous informal abbreviations. We propose a novel multi-task approach by employing a more general secondary task of Named Entity (NE) segmentation together with the primary task of fine-grained NE categorization. The multi-task neural network architecture learns higher order feature representations from word and character sequences along with basic Part-of-Speech tags and gazetteer information. This neural network acts as a feature extractor to feed a Conditional Random Fields classifier. We were able to obtain the first position in the 3rd Workshop on Noisy User-generated Text (WNUT-2017) with a 41.86% entity F1-score and a 40.24% surface F1-score.
* EMNLP 2017 (W-NUT)
Folksonomication: Predicting Tags for Movies from Plot Synopses Using Emotion Flow Encoded Neural Network
Aug 15, 2018
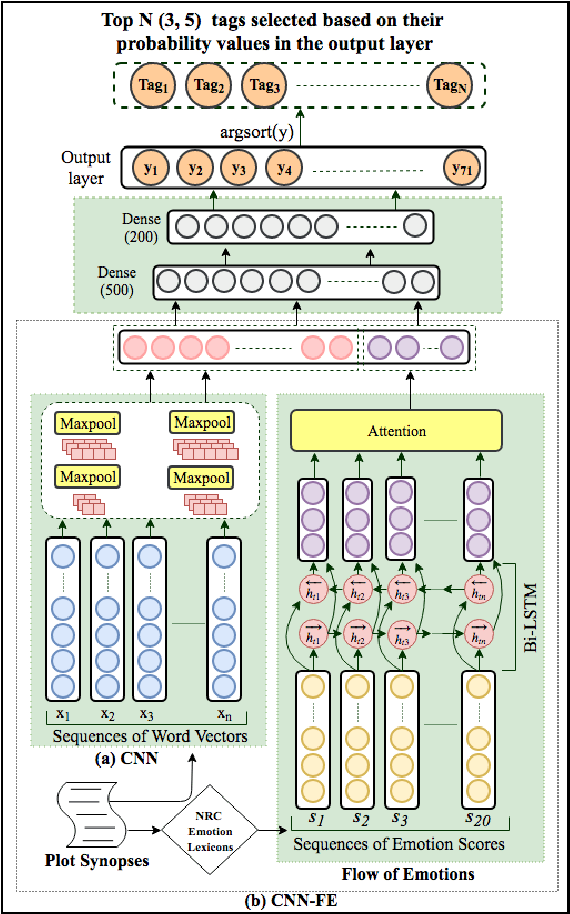

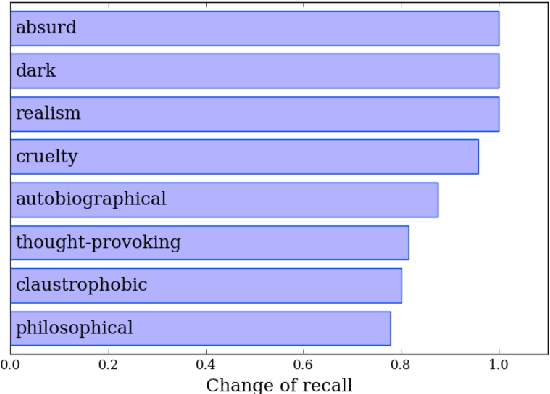
Folksonomy of movies covers a wide range of heterogeneous information about movies, like the genre, plot structure, visual experiences, soundtracks, metadata, and emotional experiences from watching a movie. Being able to automatically generate or predict tags for movies can help recommendation engines improve retrieval of similar movies, and help viewers know what to expect from a movie in advance. In this work, we explore the problem of creating tags for movies from plot synopses. We propose a novel neural network model that merges information from synopses and emotion flows throughout the plots to predict a set of tags for movies. We compare our system with multiple baselines and found that the addition of emotion flows boosts the performance of the network by learning ~18\% more tags than a traditional machine learning system.
Letting Emotions Flow: Success Prediction by Modeling the Flow of Emotions in Books
May 25, 2018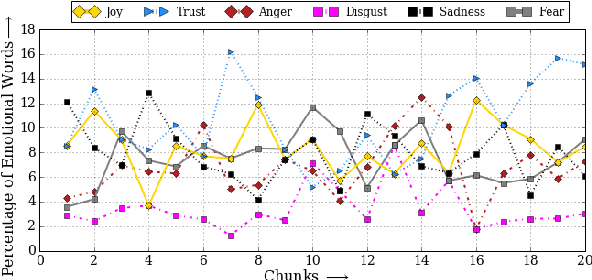

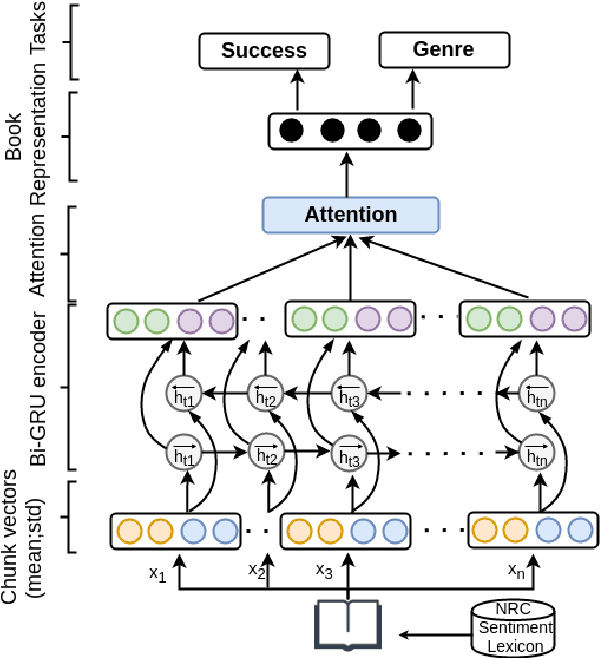

Books have the power to make us feel happiness, sadness, pain, surprise, or sorrow. An author's dexterity in the use of these emotions captivates readers and makes it difficult for them to put the book down. In this paper, we model the flow of emotions over a book using recurrent neural networks and quantify its usefulness in predicting success in books. We obtained the best weighted F1-score of 69% for predicting books' success in a multitask setting (simultaneously predicting success and genre of books).
MPST: A Corpus of Movie Plot Synopses with Tags
Feb 23, 2018
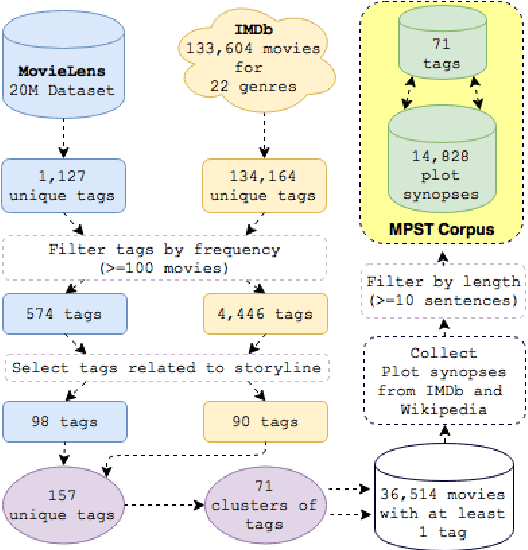
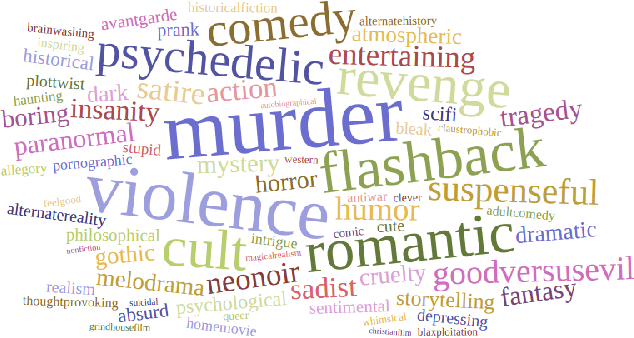
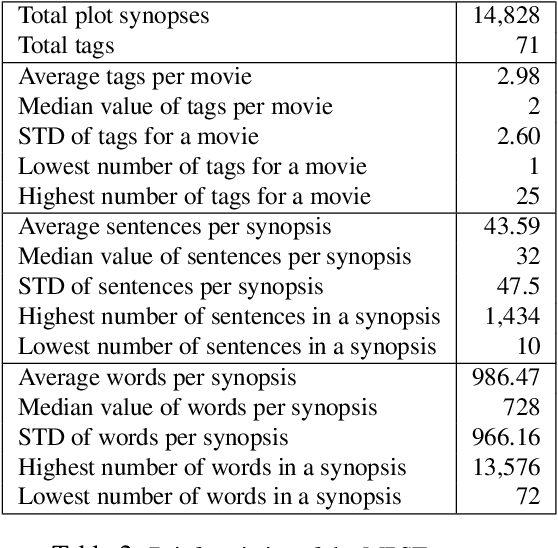
Social tagging of movies reveals a wide range of heterogeneous information about movies, like the genre, plot structure, soundtracks, metadata, visual and emotional experiences. Such information can be valuable in building automatic systems to create tags for movies. Automatic tagging systems can help recommendation engines to improve the retrieval of similar movies as well as help viewers to know what to expect from a movie in advance. In this paper, we set out to the task of collecting a corpus of movie plot synopses and tags. We describe a methodology that enabled us to build a fine-grained set of around 70 tags exposing heterogeneous characteristics of movie plots and the multi-label associations of these tags with some 14K movie plot synopses. We investigate how these tags correlate with movies and the flow of emotions throughout different types of movies. Finally, we use this corpus to explore the feasibility of inferring tags from plot synopses. We expect the corpus will be useful in other tasks where analysis of narratives is relevant.