 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory Guard -- A Lightweight, Sequence-Aware Model for Real-Time Anomaly Detection in Agentic AI
Jan 02, 2026Autonomous LLM agents generate multi-step action plans that can fail due to contextual misalignment or structural incoherence. Existing anomaly detection methods are ill-suited for this challenge: mean-pooling embeddings dilutes anomalous steps, while contrastive-only approaches ignore sequential structure. Standard unsupervised methods on pre-trained embeddings achieve F1-scores no higher than 0.69. We introduce Trajectory Guard, a Siamese Recurrent Autoencoder with a hybrid loss function that jointly learns task-trajectory alignment via contrastive learning and sequential validity via reconstruction. This dual objective enables unified detection of both "wrong plan for this task" and "malformed plan structure." On benchmarks spanning synthetic perturbations and real-world failures from security audits (RAS-Eval) and multi-agent systems (Who\&When), we achieve F1-scores of 0.88-0.94 on balanced sets and recall of 0.86-0.92 on imbalanced external benchmarks. At 32 ms inference latency, our approach runs 17-27$\times$ faster than LLM Judge baselines, enabling real-time safety verification in production deployments.
When Small Models Are Right for Wrong Reasons: Process Verification for Trustworthy Agents
Jan 01, 2026Deploying small language models (7-9B parameters) as autonomous agents requires trust in their reasoning, not just their outputs. We reveal a critical reliability crisis: 50-69\% of correct answers from these models contain fundamentally flawed reasoning -- a ``Right-for-Wrong-Reasons'' phenomenon invisible to standard accuracy metrics. Through analysis of 10,734 reasoning traces across three models and diverse tasks, we introduce the Reasoning Integrity Score (RIS), a process-based metric validated with substantial inter-rater agreement ($κ=0.657$). Conventional practices are challenged by our findings: while retrieval-augmented generation (RAG) significantly improves reasoning integrity (Cohen's $d=0.23$--$0.93$), meta-cognitive interventions like self-critique often harm performance ($d=-0.14$ to $-0.33$) in small models on the evaluated tasks. Mechanistic analysis reveals RAG succeeds by grounding calculations in external evidence, reducing errors by 7.6\%, while meta-cognition amplifies confusion without sufficient model capacity. To enable deployment, verification capabilities are distilled into a neural classifier achieving 0.86 F1-score with 100$\times$ speedup. These results underscore the necessity of process-based verification for trustworthy agents: accuracy alone is dangerously insufficient when models can be right for entirely wrong reasons.
Effective Proxy for Human Labeling: Ensemble Disagreement Scores in Large Language Models for Industrial NLP
Sep 11, 2023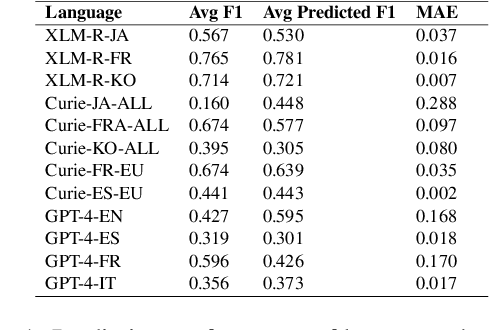
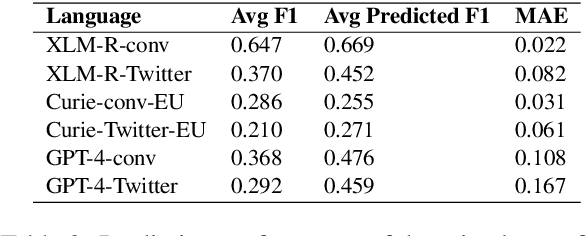
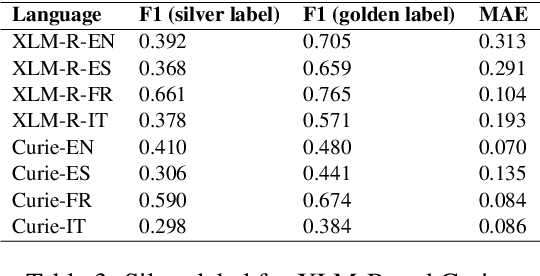
Large language models (LLMs) have demonstrated significant capability to generalize across a large number of NLP tasks. For industry applications, it is imperative to assess the performance of the LLM on unlabeled production data from time to time to validate for a real-world setting. Human labeling to assess model error requires considerable expense and time delay. Here we demonstrate that ensemble disagreement scores work well as a proxy for human labeling for language models in zero-shot, few-shot, and fine-tuned settings, per our evaluation on keyphrase extraction (KPE) task. We measure fidelity of the results by comparing to true error measured from human labeled ground truth. We contrast with the alternative of using another LLM as a source of machine labels, or silver labels. Results across various languages and domains show disagreement scores provide a better estimation of model performance with mean average error (MAE) as low as 0.4% and on average 13.8% better than using silver labels.
C1 at SemEval-2020 Task 9: SentiMix: Sentiment Analysis for Code-Mixed Social Media Text using Feature Engineering
Aug 09, 2020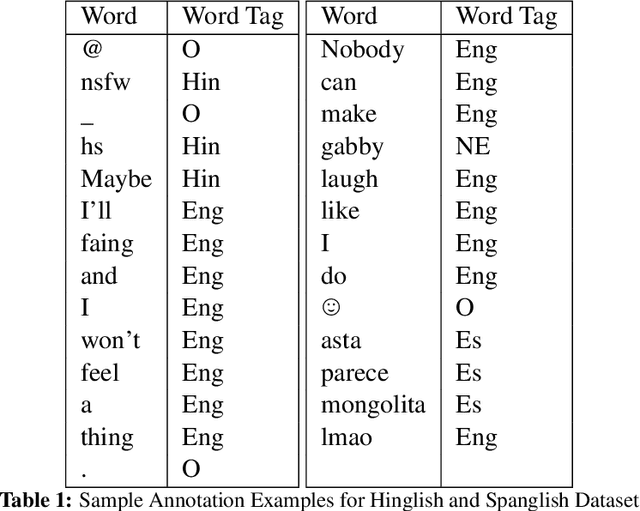
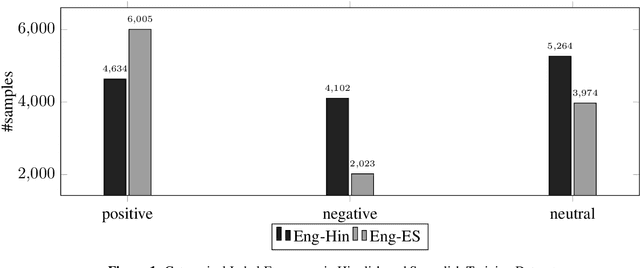
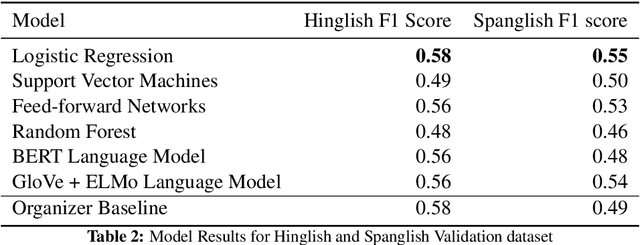

In today's interconnected and multilingual world, code-mixing of languages on social media is a common occurrence. While many Natural Language Processing (NLP) tasks like sentiment analysis are mature and well designed for monolingual text, techniques to apply these tasks to code-mixed text still warrant exploration. This paper describes our feature engineering approach to sentiment analysis in code-mixed social media text for SemEval-2020 Task 9: SentiMix. We tackle this problem by leveraging a set of hand-engineered lexical, sentiment, and metadata features to design a classifier that can disambiguate between "positive", "negative" and "neutral" sentiment. With this model, we are able to obtain a weighted F1 score of 0.65 for the "Hinglish" task and 0.63 for the "Spanglish" tasks