 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfQA: Answer Only If You Are Confident
Jun 08, 2025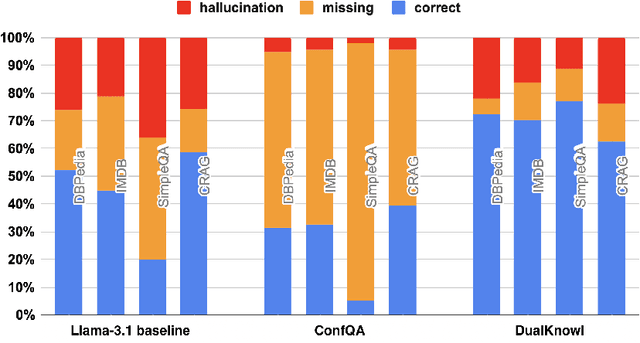
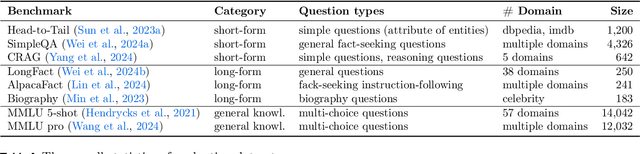
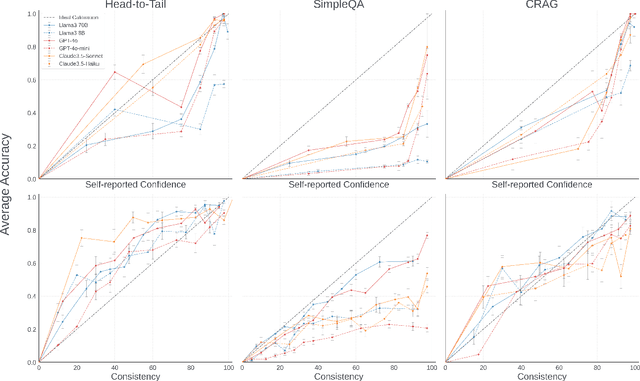
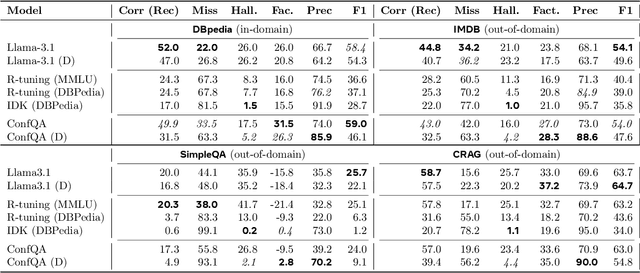
Can we teach Large Language Models (LLMs) to refrain from hallucinating factual statements? In this paper we present a fine-tuning strategy that we call ConfQA, which can reduce hallucination rate from 20-40% to under 5% across multiple factuality benchmarks. The core idea is simple: when the LLM answers a question correctly, it is trained to continue with the answer; otherwise, it is trained to admit "I am unsure". But there are two key factors that make the training highly effective. First, we introduce a dampening prompt "answer only if you are confident" to explicitly guide the behavior, without which hallucination remains high as 15%-25%. Second, we leverage simple factual statements, specifically attribute values from knowledge graphs, to help LLMs calibrate the confidence, resulting in robust generalization across domains and question types. Building on this insight, we propose the Dual Neural Knowledge framework, which seamlessly select between internally parameterized neural knowledge and externally recorded symbolic knowledge based on ConfQA's confidence. The framework enables potential accuracy gains to beyond 95%, while reducing unnecessary external retrievals by over 30%.
Effective Proxy for Human Labeling: Ensemble Disagreement Scores in Large Language Models for Industrial NLP
Sep 11, 2023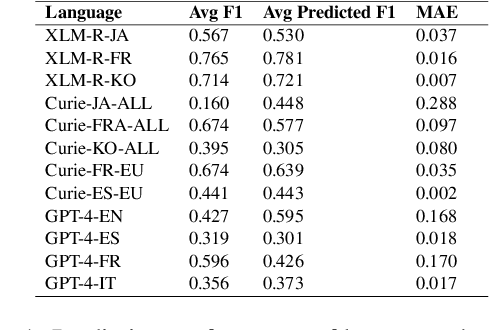
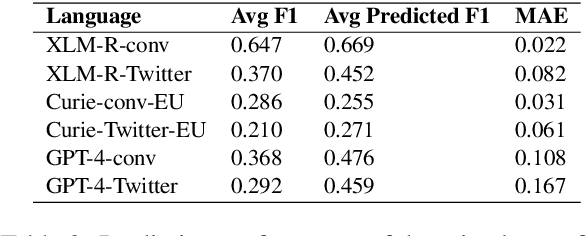
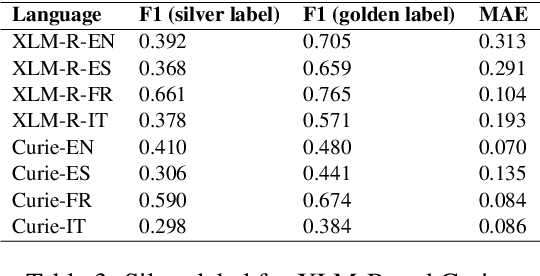
Large language models (LLMs) have demonstrated significant capability to generalize across a large number of NLP tasks. For industry applications, it is imperative to assess the performance of the LLM on unlabeled production data from time to time to validate for a real-world setting. Human labeling to assess model error requires considerable expense and time delay. Here we demonstrate that ensemble disagreement scores work well as a proxy for human labeling for language models in zero-shot, few-shot, and fine-tuned settings, per our evaluation on keyphrase extraction (KPE) task. We measure fidelity of the results by comparing to true error measured from human labeled ground truth. We contrast with the alternative of using another LLM as a source of machine labels, or silver labels. Results across various languages and domains show disagreement scores provide a better estimation of model performance with mean average error (MAE) as low as 0.4% and on average 13.8% better than using silver labels.
Compressing Cross-Lingual Multi-Task Models at Qualtrics
Nov 29, 2022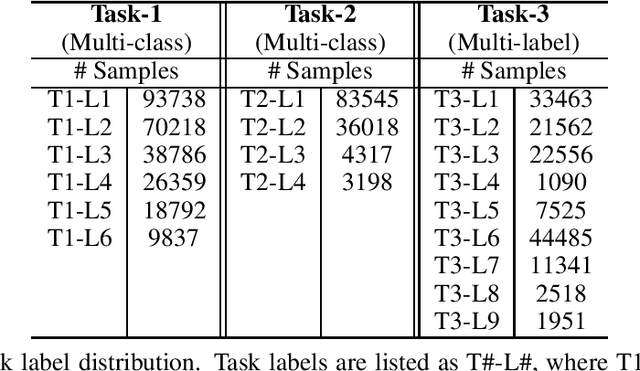

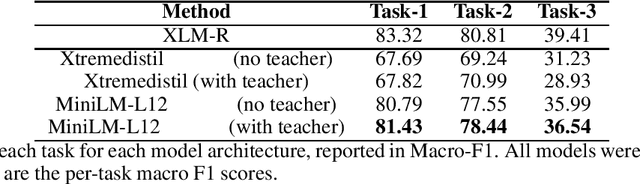
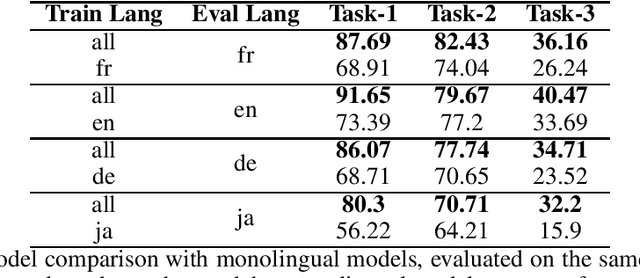
Experience management is an emerging business area where organizations focus on understanding the feedback of customers and employees in order to improve their end-to-end experiences. This results in a unique set of machine learning problems to help understand how people feel, discover issues they care about, and find which actions need to be taken on data that are different in content and distribution from traditional NLP domains. In this paper, we present a case study of building text analysis applications that perform multiple classification tasks efficiently in 12 languages in the nascent business area of experience management. In order to scale up modern ML methods on experience data, we leverage cross lingual and multi-task modeling techniques to consolidate our models into a single deployment to avoid overhead. We also make use of model compression and model distillation to reduce overall inference latency and hardware cost to the level acceptable for business needs while maintaining model prediction quality. Our findings show that multi-task modeling improves task performance for a subset of experience management tasks in both XLM-R and mBert architectures. Among the compressed architectures we explored, we found that MiniLM achieved the best compression/performance tradeoff. Our case study demonstrates a speedup of up to 15.61x with 2.60% average task degradation (or 3.29x speedup with 1.71% degradation) and estimated savings of 44% over using the original full-size model. These results demonstrate a successful scaling up of text classification for the challenging new area of ML for experience management.
End-to-end Joint Entity Extraction and Negation Detection for Clinical Text
Jan 18, 2019
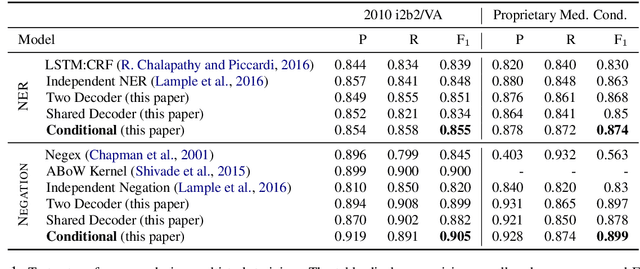
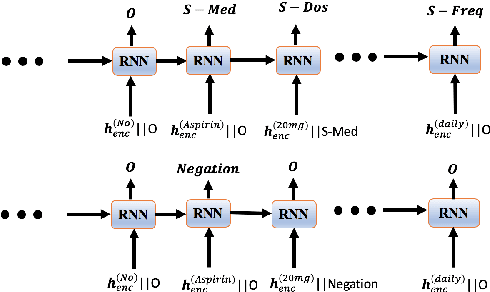
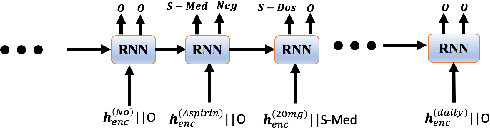
Negative medical findings are prevalent in clinical reports, yet discriminating them from positive findings remains a challenging task for information extraction. Most of the existing systems treat this task as a pipeline of two separate tasks, i.e., named entity recognition (NER) and rule-based negation detection. We consider this as a multi-task problem and present a novel end-to-end neural model to jointly extract entities and negations. We extend a standard hierarchical encoder-decoder NER model and first adopt a shared encoder followed by separate decoders for the two tasks. This architecture performs considerably better than the previous rule-based and machine learning-based systems. To overcome the problem of increased parameter size especially for low-resource settings, we propose the \textit{Conditional Softmax Shared Decoder} architecture which achieves state-of-art results for NER and negation detection on the 2010 i2b2/VA challenge dataset and a proprietary de-identified clinical dataset.
Improving Hospital Mortality Prediction with Medical Named Entities and Multimodal Learning
Dec 04, 2018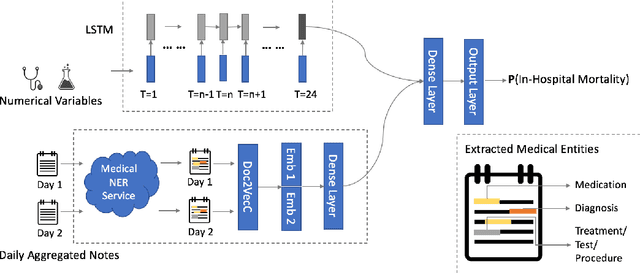
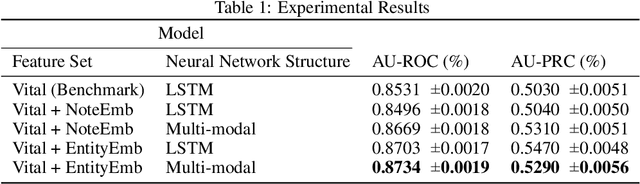

Clinical text provides essential information to estimate the acuity of a patient during hospital stays in addition to structured clinical data. In this study, we explore how clinical text can complement a clinical predictive learning task. We leverage an internal medical natural language processing service to perform named entity extraction and negation detection on clinical notes and compose selected entities into a new text corpus to train document representations. We then propose a multimodal neural network to jointly train time series signals and unstructured clinical text representations to predict the in-hospital mortality risk for ICU patients. Our model outperforms the benchmark by 2% AUC.