 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemoving Spurious Correlation from Neural Network Interpretations
Dec 03, 2024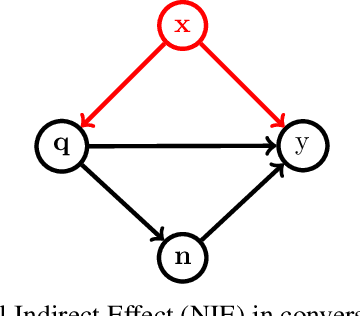
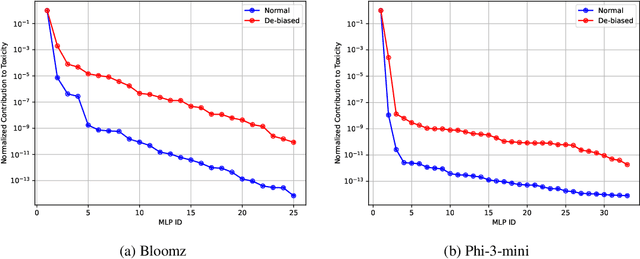
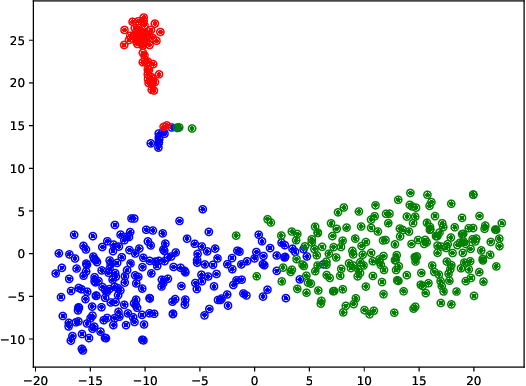
The existing algorithms for identification of neurons responsible for undesired and harmful behaviors do not consider the effects of confounders such as topic of the conversation. In this work, we show that confounders can create spurious correlations and propose a new causal mediation approach that controls the impact of the topic. In experiments with two large language models, we study the localization hypothesis and show that adjusting for the effect of conversation topic, toxicity becomes less localized.
Fast Training Dataset Attribution via In-Context Learning
Aug 14, 2024We investigate the use of in-context learning and prompt engineering to estimate the contributions of training data in the outputs of instruction-tuned large language models (LLMs). We propose two novel approaches: (1) a similarity-based approach that measures the difference between LLM outputs with and without provided context, and (2) a mixture distribution model approach that frames the problem of identifying contribution scores as a matrix factorization task. Our empirical comparison demonstrates that the mixture model approach is more robust to retrieval noise in in-context learning, providing a more reliable estimation of data contributions.
Multiply-Robust Causal Change Attribution
Apr 12, 2024Comparing two samples of data, we observe a change in the distribution of an outcome variable. In the presence of multiple explanatory variables, how much of the change can be explained by each possible cause? We develop a new estimation strategy that, given a causal model, combines regression and re-weighting methods to quantify the contribution of each causal mechanism. Our proposed methodology is multiply robust, meaning that it still recovers the target parameter under partial misspecification. We prove that our estimator is consistent and asymptotically normal. Moreover, it can be incorporated into existing frameworks for causal attribution, such as Shapley values, which will inherit the consistency and large-sample distribution properties. Our method demonstrates excellent performance in Monte Carlo simulations, and we show its usefulness in an empirical application.
End-to-End Balancing for Causal Continuous Treatment-Effect Estimation
Jul 27, 2021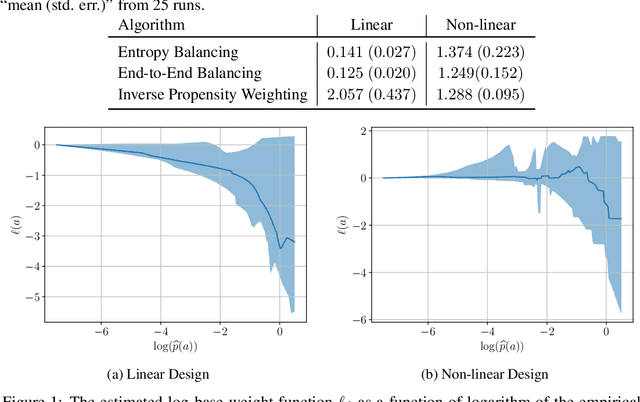
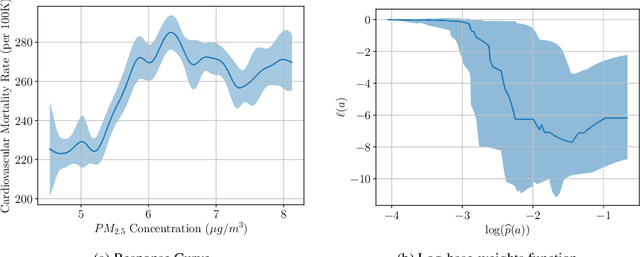
We study the problem of observational causal inference with continuous treatment. We focus on the challenge of estimating the causal response curve for infrequently-observed treatment values. We design a new algorithm based on the framework of entropy balancing which learns weights that directly maximize causal inference accuracy using end-to-end optimization. Our weights can be customized for different datasets and causal inference algorithms. We propose a new theory for consistency of entropy balancing for continuous treatments. Using synthetic and real-world data, we show that our proposed algorithm outperforms the entropy balancing in terms of causal inference accuracy.
Debiasing Concept Bottleneck Models with Instrumental Variables
Jul 22, 2020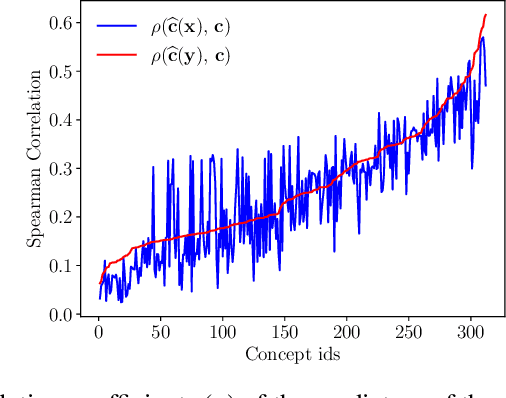
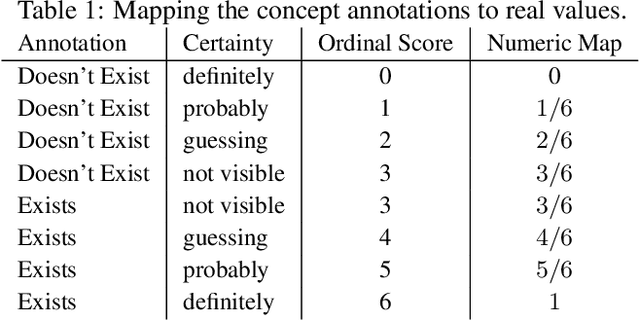
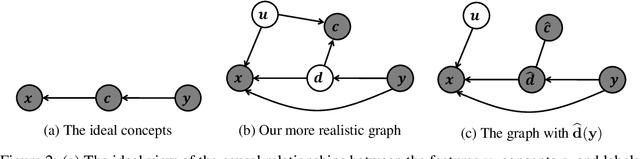
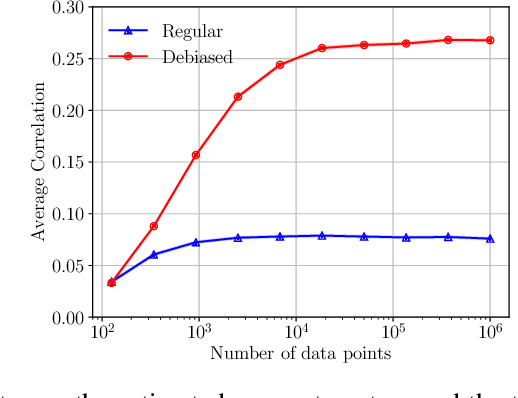
Concept-based explanation approach is a popular model interpertability tool because it expresses the reasons for a model's predictions in terms of concepts that are meaningful for the domain experts. In this work, we study the problem of the concepts being correlated with confounding information in the features. We propose a new causal prior graph for modeling the impacts of unobserved variables and a method to remove the impact of confounding information using the instrumental variable techniques. We also model the completeness of the concepts set. Our synthetic and real-world experiments demonstrate the success of our method in removing biases due to confounding and noise from the concepts.
Discovering Invariances in Healthcare Neural Networks
Nov 08, 2019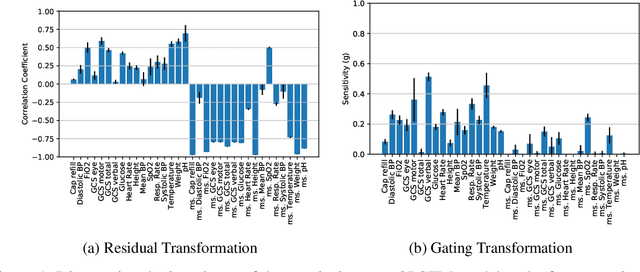

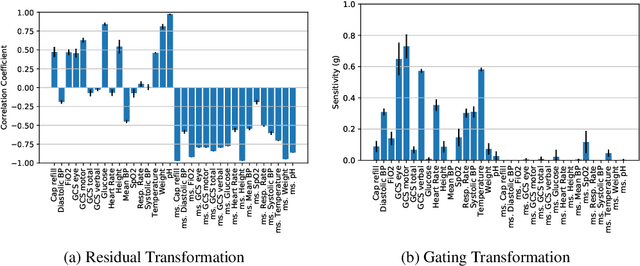
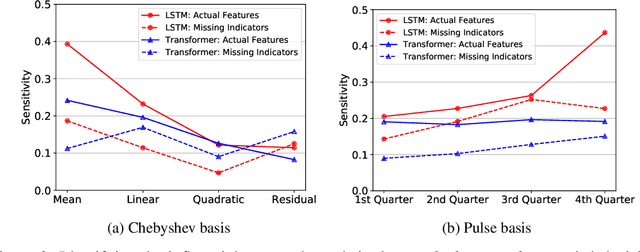
We study the invariance characteristics of pre-trained predictive models by empirically learning transformations on the input that leave the prediction function approximately unchanged. To learn invariance transformations, we minimize the Wasserstein distance between the predictive distribution conditioned on the data instances and the predictive distribution conditioned on the transformed data instances. To avoid finding degenerate or perturbative transformations, we further regularize by adding a similarity term between the data and its transformed values. Applying the proposed technique to clinical time series data, we discover variables that commonly-used LSTM models do not rely on for their prediction, especially when the LSTM is trained to be adversarially robust.
Temporal-Clustering Invariance in Irregular Healthcare Time Series
Apr 27, 2019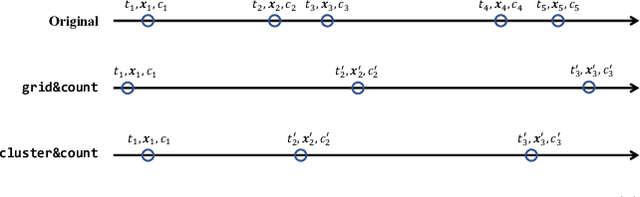

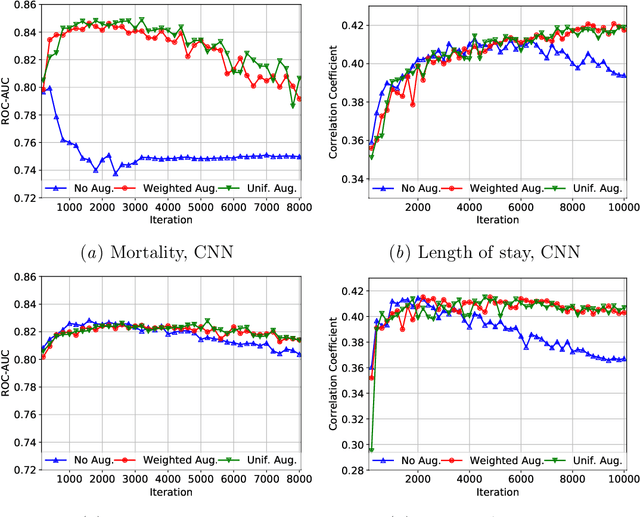
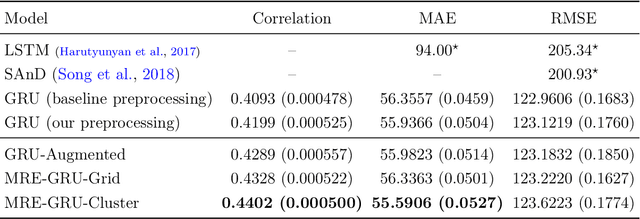
Electronic records contain sequences of events, some of which take place all at once in a single visit, and others that are dispersed over multiple visits, each with a different timestamp. We postulate that fine temporal detail, e.g., whether a series of blood tests are completed at once or in rapid succession should not alter predictions based on this data. Motivated by this intuition, we propose models for analyzing sequences of multivariate clinical time series data that are invariant to this temporal clustering. We propose an efficient data augmentation technique that exploits the postulated temporal-clustering invariance to regularize deep neural networks optimized for several clinical prediction tasks. We introduce two techniques to temporally coarsen (downsample) irregular time series: (i) grouping the data points based on regularly-spaced timestamps; and (ii) clustering them, yielding irregularly-paced timestamps. Moreover, we propose a MultiResolution Ensemble (MRE) model, improving predictive accuracy by ensembling predictions based on inputs sequences transformed by different coarsening operators. Our experiments show that MRE improves the mAP on the benchmark mortality prediction task from 51.53% to 53.92%.
Improving Hospital Mortality Prediction with Medical Named Entities and Multimodal Learning
Dec 04, 2018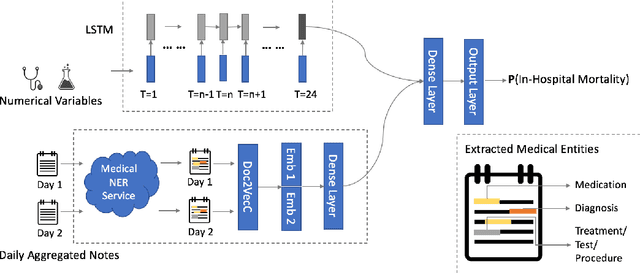
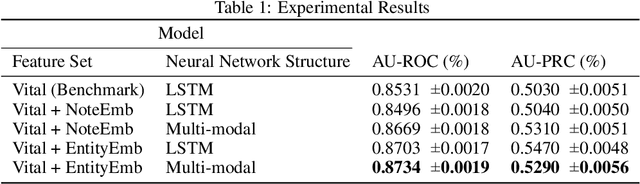

Clinical text provides essential information to estimate the acuity of a patient during hospital stays in addition to structured clinical data. In this study, we explore how clinical text can complement a clinical predictive learning task. We leverage an internal medical natural language processing service to perform named entity extraction and negation detection on clinical notes and compose selected entities into a new text corpus to train document representations. We then propose a multimodal neural network to jointly train time series signals and unstructured clinical text representations to predict the in-hospital mortality risk for ICU patients. Our model outperforms the benchmark by 2% AUC.
GRAM: Graph-based Attention Model for Healthcare Representation Learning
Apr 01, 2017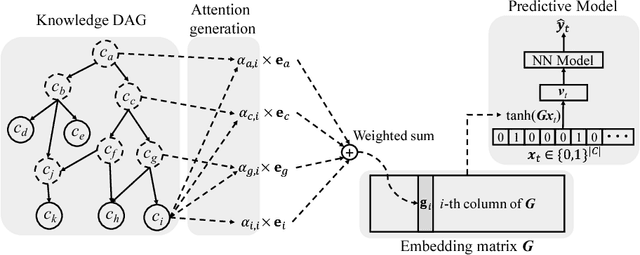
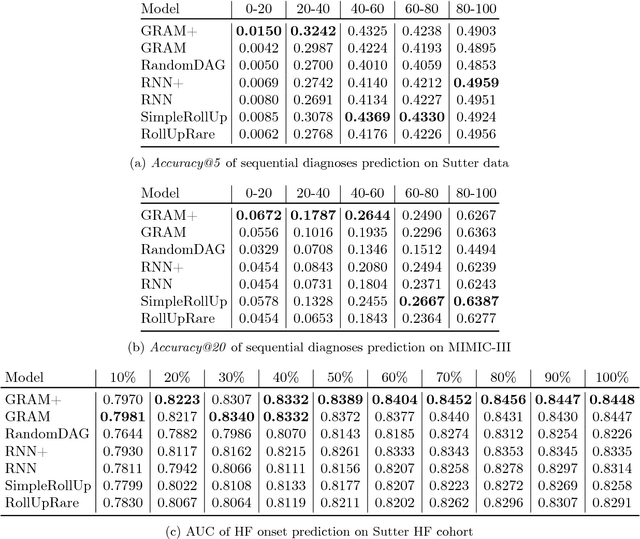

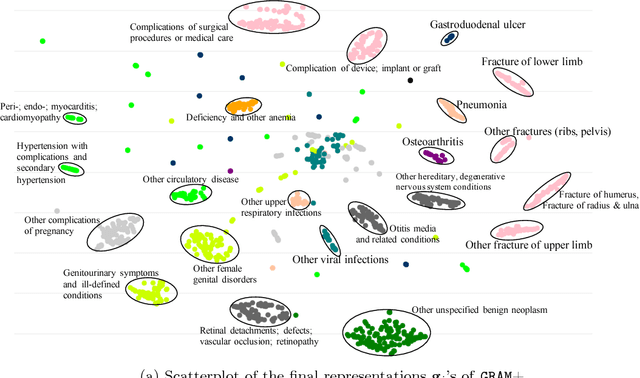
Deep learning methods exhibit promising performance for predictive modeling in healthcare, but two important challenges remain: -Data insufficiency:Often in healthcare predictive modeling, the sample size is insufficient for deep learning methods to achieve satisfactory results. -Interpretation:The representations learned by deep learning methods should align with medical knowledge. To address these challenges, we propose a GRaph-based Attention Model, GRAM that supplements electronic health records (EHR) with hierarchical information inherent to medical ontologies. Based on the data volume and the ontology structure, GRAM represents a medical concept as a combination of its ancestors in the ontology via an attention mechanism. We compared predictive performance (i.e. accuracy, data needs, interpretability) of GRAM to various methods including the recurrent neural network (RNN) in two sequential diagnoses prediction tasks and one heart failure prediction task. Compared to the basic RNN, GRAM achieved 10% higher accuracy for predicting diseases rarely observed in the training data and 3% improved area under the ROC curve for predicting heart failure using an order of magnitude less training data. Additionally, unlike other methods, the medical concept representations learned by GRAM are well aligned with the medical ontology. Finally, GRAM exhibits intuitive attention behaviors by adaptively generalizing to higher level concepts when facing data insufficiency at the lower level concepts.
RETAIN: An Interpretable Predictive Model for Healthcare using Reverse Time Attention Mechanism
Feb 26, 2017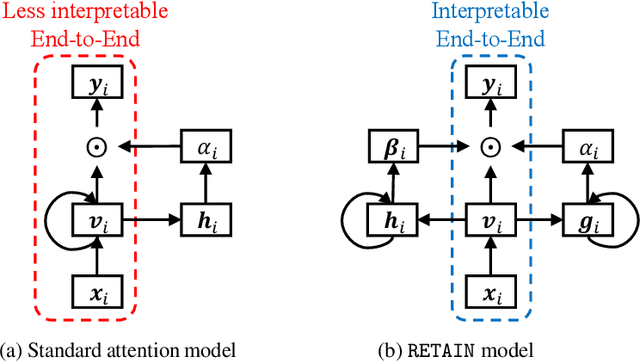

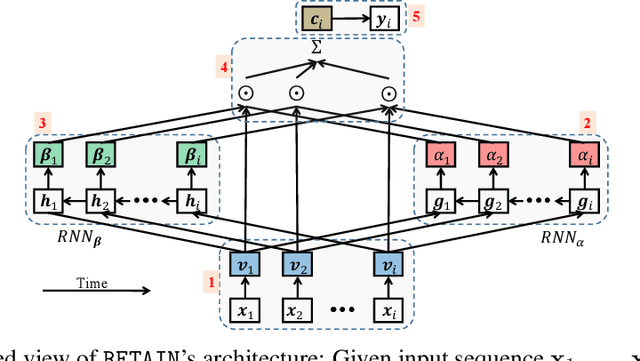
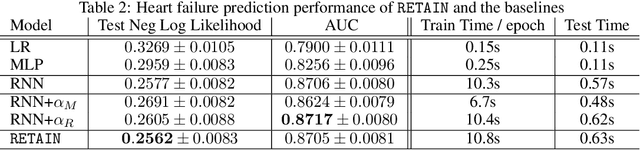
Accuracy and interpretability are two dominant features of successful predictive models. Typically, a choice must be made in favor of complex black box models such as recurrent neural networks (RNN) for accuracy versus less accurate but more interpretable traditional models such as logistic regression. This tradeoff poses challenges in medicine where both accuracy and interpretability are important. We addressed this challenge by developing the REverse Time AttentIoN model (RETAIN) for application to Electronic Health Records (EHR) data. RETAIN achieves high accuracy while remaining clinically interpretable and is based on a two-level neural attention model that detects influential past visits and significant clinical variables within those visits (e.g. key diagnoses). RETAIN mimics physician practice by attending the EHR data in a reverse time order so that recent clinical visits are likely to receive higher attention. RETAIN was tested on a large health system EHR dataset with 14 million visits completed by 263K patients over an 8 year period and demonstrated predictive accuracy and computational scalability comparable to state-of-the-art methods such as RNN, and ease of interpretability comparable to traditional models.